
Introduction
In our previous blog, we explored the foundational concepts of Regions and Availability Zones (AZs) as offered by AWS, Azure, and GCP. These building blocks are crucial for constructing resilient and scalable cloud infrastructures.
In this blog, we delve deeper into how these two major cloud providers, AWS and Azure, leverage these components to deliver high availability (HA) for your applications and data.
Understanding High Availability
Before diving into the specifics of AWS and Azure, it's essential to clarify the concept of high availability. At its essence, high availability means minimizing downtime and ensuring continuous access to systems and applications. This is typically achieved through redundancy, load balancing, and failover mechanisms.
- Redundancy: Creating multiple instances of critical components (servers, databases, applications) to distribute the workload.
- Load Balancing: Distributing incoming traffic across multiple instances to prevent overload and improve performance.
- Failover: Automatically switching to a backup system or component in case of a failure.
To better understand the impact of different availability levels, consider the following table which illustrates the relationship between availability percentages and actual downtime:
| Availability | Downtime per Year | Downtime per Month | Downtime per Week |
| 99% | 3.65 days | 7.20 hours | 1.68 hours |
| 99.90% | 8.76 hours | 43.8 minutes | 10.1 minutes |
| 99.99% | 52.56 minutes | 4.38 minutes | 1.01 minutes |
| 99.999% | 5.26 minutes | 26.30 seconds | 6.05 seconds |
This table demonstrates how even small improvements in availability percentages can significantly reduce potential downtime. As we explore AWS and Azure strategies for high availability, keep these figures in mind to better appreciate the impact of various approaches on system uptime.
These downtime values are derived from a straightforward calculation based on the availability percentage. For any given period, the downtime is calculated as:
Downtime = Total time in the period × (100% - Availability %)
For example, to calculate the yearly downtime for 99.9% availability:
Total time in a year = 365 days × 24 hours = 8,760 hours
Downtime = 8,760 hours × (100% - 99.9%) = 8,760 × 0.1% = 8.76 hours
This method can be applied to any time period and availability percentage.
It's important to note that these calculations assume continuous operation and represent statistical averages. In practice, downtime might occur in larger chunks rather than being evenly distributed, and actual performance can vary. Understanding these figures helps in setting realistic expectations and planning appropriate high-availability strategies.
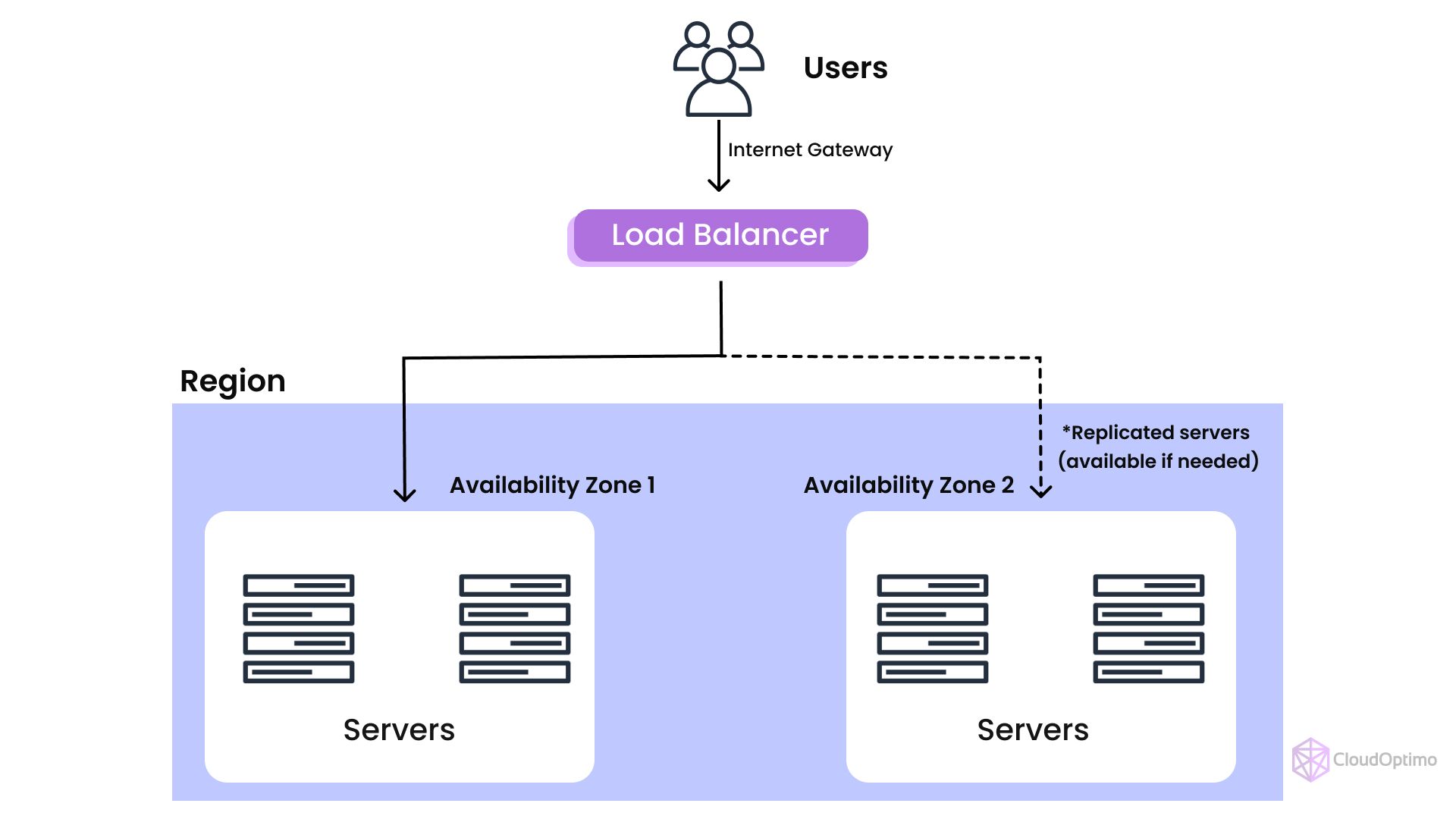
AWS High Availability Overview
Amazon Web Services (AWS) is renowned for its global infrastructure that spans multiple geographic regions and availability zones (AZs). Here’s how AWS ensures high availability:
- Regions and Availability Zones (AZs)
AWS divides the world into geographic regions, each containing multiple availability zones. Availability zones are distinct data centers within a region, separated to minimize the risk of a single event impacting multiple AZs. AWS recommends deploying applications across multiple AZs to achieve fault tolerance and high availability.
AWS Services for High Availability
AWS provides a variety of services and features designed to enhance high availability:
- Amazon EC2 Auto Scaling: Automatically adjusts the number of EC2 instances based on traffic demand to maintain performance and availability.
- Amazon S3: Offers 99.999999999% (11 9's) durability and ensures high availability through redundancy across multiple devices and AZs.
- Elastic Load Balancing (ELB): Distributes incoming application traffic across multiple targets, such as EC2 instances, ensuring high availability and fault tolerance.
- Amazon RDS Multi-AZ Deployments: Automatically replicates databases across AZs to provide data redundancy and failover support.
Azure High Availability Overview
Microsoft Azure provides a comprehensive set of services and features to ensure high availability for applications and services. Azure’s approach to high availability includes:
Regions and Availability Zones (AZs)
Azure regions are global data center locations where Azure resources are deployed. Each region consists of multiple data centers, and Azure offers availability zones (AZs) in select regions, ensuring resilient infrastructure for critical applications.
Azure Services for High Availability
Azure offers several services and features aimed at achieving high availability:
- Azure Virtual Machines (VMs) Availability Sets: Distributes VM instances across multiple fault domains to ensure application availability during planned and unplanned events.
- Azure Blob Storage: Provides redundancy options such as Geo-redundant Storage (GRS) and Zone-redundant Storage (ZRS) to ensure data durability and availability.
- Azure Load Balancer: Distributes incoming traffic across multiple VMs within a single data center or across availability zones for high availability.
- Azure SQL Database Automatic Failover Groups: Enables automatic failover and replication across regions to maintain application availability and data consistency.
| Feature | AWS | Azure |
| Compute | EC2 | Virtual Machines, Scale Sets |
| Storage | Amazon S3 | Azure Blob Storage |
| Load Balancing | Elastic Load Balancing | Azure Load Balancer |
| Database | RDS Multi-AZ Deployments | SQL Database Automatic Failover Groups |
| DNS Routing | Route 53 | Azure Traffic Manager |
| Serverless | Lambda | Azure Functions |
| Edge Computing | AWS Outposts | Azure Stack |
High Availability Strategies and Best Practices
- AWS
- Multi-AZ Deployments: Distribute application components across multiple AZs.
- Best Practice: Design your architecture to withstand the failure of a single AZ.
- EBS Volume Mirroring: Create synchronous or asynchronous copies of EBS volumes across AZs.
- Best Practice: Regularly test failover scenarios to ensure data consistency.
- Route 53 Failover Routing: Direct traffic to healthy instances or regions.
- Best Practice: Implement health checks and configure appropriate failover thresholds.
- AWS Lambda: Leverage serverless functions for automatic scaling and high availability.
- Best Practice: Design functions to be stateless and idempotent for better resilience.
- Multi-AZ Deployments: Distribute application components across multiple AZs.
- Azure
- Availability Sets: Group VMs within an availability zone for load balancing and fault tolerance.
- Best Practice: Distribute VMs across multiple update and fault domains within the set.
- Availability Zones: Deploy application components across multiple AZs.
- Best Practice: Design applications to be zone-redundant where possible.
- Azure Storage Redundancy Options: Choose appropriate storage redundancy levels.
- Best Practice: Use geo-redundant storage for critical data that requires cross-region replication.
- Azure SQL Database High Availability: Configure geo-replication or automatic failover groups.
- Best Practice: Implement application-level retry logic to handle transient failures.
- Azure Traffic Manager: Distribute traffic across multiple endpoints.
- Best Practice: Use multiple routing methods to optimize for both performance and availability.
- Availability Sets: Group VMs within an availability zone for load balancing and fault tolerance.
| Feature | AWS Implementation | Azure Implementation |
| Multi-AZ Deployment | Deploy across multiple AZs | Deploy across multiple AZs |
| Data Redundancy | S3 Cross-Region Replication | Geo-Redundant Storage |
| Load Distribution | Elastic Load Balancing | Azure Load Balancer |
| Auto-scaling | EC2 Auto Scaling | VM Scale Sets |
| Health Monitoring | CloudWatch | Azure Monitor |
| Disaster Recovery | AWS Backup | Azure Site Recovery |
Choosing the Right High-Availability Strategy
Selecting the appropriate high-availability strategy depends on several factors:
| High Availability Factor | AWS Strategy | Azure Strategy | How It Enhances Availability |
| Multi-Region Resilience | Global Accelerator | Traffic Manager | Distributes traffic across multiple regions, ensuring continuity if one region fails |
| Data Replication | S3 Cross-Region Replication | Azure Geo-Redundant Storage | Maintains data availability by replicating across geographically distant locations |
| Load Balancing | Elastic Load Balancing | Azure Load Balancer | Distributes incoming traffic across multiple resources, preventing overload and improving responsiveness |
| Auto-Scaling | EC2 Auto Scaling | Virtual Machine Scale Sets | Automatically adjusts resource capacity based on demand, maintaining performance during traffic spikes |
| Database Failover | RDS Multi-AZ Deployments | SQL Database Failover Groups | Provides automatic failover to a standby database in case of primary database failure |
| Content Delivery | CloudFront | Azure Content Delivery Network | Caches content at edge locations, reducing latency and improving availability for global users |
| Serverless Computing | Lambda | Azure Functions | Eliminates infrastructure management, automatically scaling to handle varying workloads |
| Disaster Recovery | AWS Backup | Azure Site Recovery | Enables rapid recovery of critical systems in case of major outages or disasters |
Advanced High Availability Concepts
Edge Computing
Both AWS and Azure extend their cloud capabilities to edge locations, enhancing high availability for applications requiring low latency or local data processing. AWS Outposts are designed to support applications that need to operate with single-digit millisecond latencies or local data processing requirements, enhancing high availability by reducing latency and improving data locality. Similarly, Azure Stack helps maintain high availability even when direct access to public cloud services is limited or latency requirements are stringent.
The importance of high availability in edge computing is as follows:
- Reduced Latency: By processing data closer to where it's generated or consumed, edge computing reduces latency, which is crucial for applications requiring real-time responsiveness and reliability.
- Resilience: Edge locations can operate independently or in a federated model with cloud regions, providing resilience against network disruptions or data center failures.
- Data Sovereignty: Edge computing supports compliance requirements by enabling data processing and storage within specific geographic boundaries, ensuring data sovereignty and regulatory adherence.
Use cases include:
- IoT deployments - Edge computing is essential for IoT deployments where low-latency data processing is critical for real-time decision-making.
- Content delivery networks - Edge locations facilitate faster content delivery, improving user experience for streaming services, gaming platforms, and media distribution.
- Mission-critical operations - Industries such as finance, healthcare, and manufacturing benefit from edge computing's ability to maintain operations during network outages or connectivity issues.
Serverless Computing
AWS Lambda and Azure Functions provide inherent high availability through their serverless architectures, automatically scaling and distributing compute tasks across multiple availability zones or regions. AWS Lambda allows you to run code without provisioning or managing servers. It automatically scales your application by running code in response to triggers and events, handling the deployment and scaling of the infrastructure required to run your code. Azure Functions similarly enables serverless computing, where you can write and deploy code that executes in response to events, without managing infrastructure.
The importance of high availability in serverless computing is as follows:
- Automatic Scaling: Serverless platforms automatically scale resources up or down based on demand, ensuring high availability during traffic spikes without manual intervention.
- Fault Isolation: Functions in serverless architectures are inherently isolated, meaning failures in one function don't directly impact others, enhancing overall system resilience.
- Reduced Operational Overhead: By eliminating server management, serverless computing reduces the risk of downtime due to misconfiguration or inadequate maintenance, improving overall availability.
- Built-in Redundancy: Cloud providers typically run serverless functions across multiple availability zones, providing built-in redundancy and fault tolerance.
- Rapid Recovery: In case of failures, serverless platforms can quickly spin up new instances of functions, minimizing downtime and ensuring continuous service availability.
- Cost-Effective High Availability: Serverless computing allows organizations to achieve high availability without the cost and complexity of maintaining always-on server infrastructure.
Ideal for:
- Event-driven architectures - Serverless platforms excel in event-driven scenarios where tasks are triggered by events such as HTTP requests, database changes, or file uploads.
- Batch processing - Applications requiring periodic or ad-hoc batch processing tasks benefit from serverless architectures, ensuring these tasks run reliably without manual scaling.
- Microservices implementations - Serverless functions are well-suited for implementing microservices architectures, where each function can handle a specific task or function independently.
Conclusion
Both AWS and Azure offer robust tools and services for building highly available applications. The choice between them depends on your specific requirements, workload characteristics, and organizational preferences. By leveraging the strategies and best practices outlined in this blog, you can design resilient applications that minimize downtime and ensure business continuity.
Remember, high availability is an ongoing process that requires continuous attention and improvement. Stay informed about the latest developments in cloud computing and regularly review and update your high availability strategies to keep your applications resilient in an ever-changing technological landscape.






