
1. Introduction to MLOps
1.1 What is MLOps?
MLOps, short for Machine Learning Operations, is a set of practices and tools designed to streamline the deployment, monitoring, and management of machine learning (ML) models in production environments. It brings together DevOps principles with machine learning workflows, aiming to automate and optimize the process of delivering ML models from development to production.
Unlike traditional software development, where the focus is primarily on writing code, MLOps addresses the unique challenges of machine learning systems, including data management, model training, validation, deployment, and monitoring.
In essence, MLOps helps bridge the gap between data science and IT operations, ensuring that models are built, deployed, and maintained efficiently throughout their lifecycle.
1.2 Importance of MLOps in Modern ML Workflows
With the increasing use of machine learning in various industries, the importance of MLOps has grown significantly. Here are some key reasons why MLOps is essential in modern ML workflows:
- Faster Time-to-Market: MLOps practices enable continuous integration (CI) and continuous deployment (CD) of ML models, leading to quicker iterations and faster deployment in production environments.
- Scalability: As machine learning models are increasingly used for large-scale applications, MLOps helps scale model deployment, ensuring that models can handle growing amounts of data and traffic.
- Collaboration: By creating a unified pipeline for both data scientists and engineers, MLOps fosters better collaboration and ensures that both teams can work together seamlessly on model development, deployment, and maintenance.
- Automation: MLOps enables the automation of tasks like data collection, feature engineering, model training, testing, and deployment. This reduces human error and increases operational efficiency.
- Consistency and Reliability: In traditional development, software code is tested, deployed, and monitored for issues. MLOps brings similar reliability to ML models, ensuring that they perform consistently in production and can be retrained or replaced easily when needed.
1.3 Benefits of Adopting MLOps in Cloud Environments
Adopting MLOps in cloud environments offers several significant advantages:
- Infrastructure Management: Cloud platforms like AWS, Google Cloud, and Microsoft Azure provide robust infrastructure that scales automatically based on demand. This enables the deployment of ML models without worrying about managing physical servers or computing resources.
- Cost Efficiency: Cloud environments offer pay-as-you-go pricing, allowing businesses to avoid the heavy upfront costs associated with setting up on-premise infrastructure. With MLOps, you can optimize resource usage, ensuring that you only pay for what you need.
- Collaboration: Cloud-based MLOps tools facilitate seamless collaboration across teams located in different regions. Cloud services enable version control, model tracking, and centralized data storage, making collaboration more efficient.
- Security and Compliance: Cloud providers offer advanced security features and compliance certifications, such as encryption and access control, to ensure that data and models are protected. This is particularly important for industries with strict regulatory requirements, such as healthcare and finance.
- Flexibility: Cloud platforms support multiple machine learning frameworks, making it easier for teams to experiment with different models and tools without being locked into a specific infrastructure.
2. Core Components of MLOps
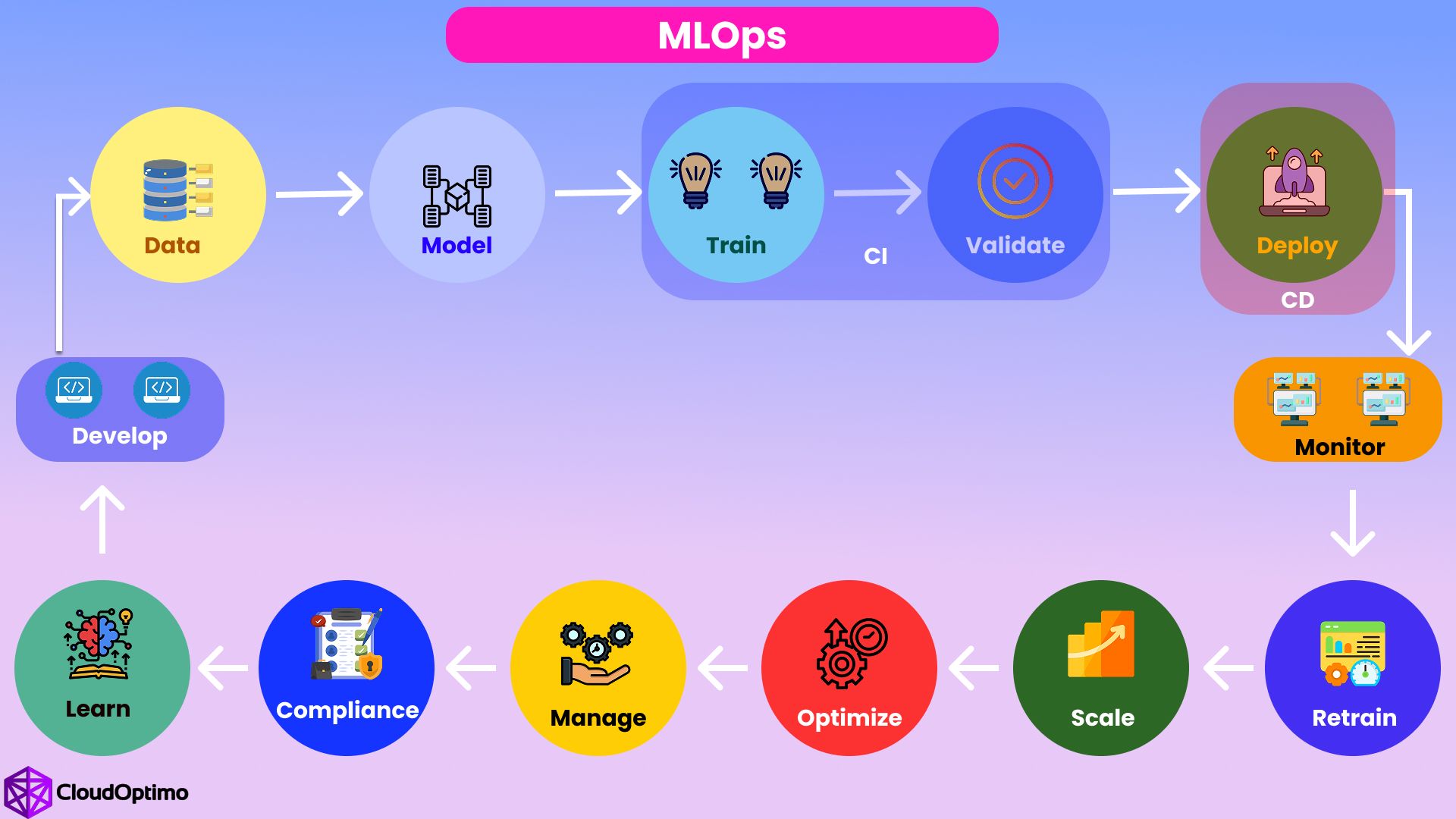
MLOps involves a series of components and practices that ensure the successful development, deployment, and maintenance of machine learning models. The core components of MLOps are as follows:
2.1 Model Development
Model development in MLOps refers to the process of designing, training, and fine-tuning machine learning models. It involves the following steps:
- Data Collection: Gathering raw data from various sources.
- Data Preprocessing: Cleaning, transforming, and preparing data for model training.
- Feature Engineering: Selecting the most relevant features for the model to improve its performance.
- Model Selection: Choosing the appropriate ML algorithms and architectures (e.g., regression, classification, deep learning).
- Model Training: Training the model on the prepared dataset and adjusting parameters.
2.2 Model Deployment
Once a model is developed, it must be deployed into a production environment where it can start making predictions on new data. In MLOps, model deployment involves:
- Deployment Pipelines: Automating the deployment of models into production environments, ensuring they are ready for real-time or batch predictions.
- Model Hosting: Deploying models on cloud infrastructure (e.g., using containerized services like Docker or Kubernetes).
- Version Control: Managing different versions of models to allow for rollback or updates without downtime.
There are several strategies for deployment, including:
- Online Deployment (real-time predictions)
- Batch Deployment (predictions made periodically)
- Edge Deployment (on-device predictions)
2.3 Continuous Integration and Continuous Deployment (CI/CD)
Continuous Integration (CI) and Continuous Deployment (CD) are critical components of MLOps that help automate the testing, integration, and deployment of machine learning models.
- Continuous Integration: Involves automatically testing and integrating changes to the model or code. When data scientists or engineers push changes to the codebase, the system runs tests (unit, integration, and model validation tests) to ensure the changes don’t break the existing system.
- Continuous Deployment: Refers to the automated deployment of models to production environments. Every time the code passes all tests, the model is automatically deployed without manual intervention. This ensures that models can be updated frequently with minimal downtime.
CI/CD pipelines in MLOps tools such as Jenkins or GitLab can be configured to handle model updates, testing, and deployment automatically.
2.4 Monitoring and Maintenance
Once models are deployed, ongoing monitoring is essential to ensure that they continue to perform well in production. This includes:
- Model Drift: Over time, the data distribution might change, making the model's predictions less accurate. Monitoring helps detect such changes (known as "model drift") and triggers retraining if necessary.
- Performance Monitoring: Tracking metrics such as latency, throughput, and error rates to ensure the system is operating optimally.
- Log Analysis: Collecting logs from the production environment to detect anomalies, errors, and performance bottlenecks.
Maintenance involves retraining models, handling failures, and ensuring the ML pipeline remains effective over time.
2.5 Collaboration and Version Control
MLOps emphasizes collaboration between data scientists, software engineers, and operations teams. This is done through:
- Version Control: Just like software code, machine learning models and datasets should be versioned. Tools like Git and DVC (Data Version Control) help manage and track changes in models, datasets, and training pipelines.
- Collaboration Platforms: Cloud platforms (like Azure ML, Google AI Platform, and AWS SageMaker) offer collaborative features such as shared workspaces, notebooks, and project management tools to facilitate teamwork across different teams.
Version control ensures that models and datasets can be reproduced at any point in time, and that changes are transparent and traceable.
3. Cloud Environments for MLOps
Cloud environments are a key enabler for effective MLOps, providing scalability, flexibility, and a host of tools that simplify the management of ML workflows.
3.1 Overview of Cloud Platforms (AWS, Azure, Google Cloud)
Several major cloud platforms provide dedicated services for MLOps. These platforms offer a variety of tools and services for developing, training, deploying, and monitoring ML models in the cloud.
- Amazon Web Services (AWS): AWS offers services like Amazon SageMaker for model building and deployment, AWS Lambda for serverless execution, and Amazon EC2 for scalable compute resources.
- Microsoft Azure: Azure provides services such as Azure Machine Learning for building and managing models, Azure Databricks for collaborative data science, and Azure Kubernetes Service (AKS) for deploying models in containers.
- Google Cloud: Google Cloud offers AI Platform for training and deployment, TensorFlow integrations, and BigQuery for data storage and analysis.
These platforms support various frameworks (like TensorFlow, PyTorch, and Scikit-learn) and tools for end-to-end ML lifecycle management.
3.2 Choosing the Right Cloud Environment for MLOps
When choosing a cloud environment for MLOps, consider the following factors:
- Ease of Use: Choose a platform that offers user-friendly interfaces, pre-built solutions, and templates for common ML tasks.
- Integration with Existing Tools: Ensure that the cloud environment integrates well with your existing ML tools, frameworks, and workflows.
- Cost Efficiency: Analyze pricing models, such as pay-per-use or subscription-based pricing, and select the one that best fits your project needs and budget.
- Scalability: Ensure that the cloud platform can scale seamlessly to handle growing data, traffic, and workload demands.
3.3 Benefits of Using Cloud for MLOps
Using cloud environments for MLOps offers several benefits:
- Flexibility: Cloud platforms support multiple machine learning frameworks and offer powerful computing resources (GPU, TPU) for large-scale ML training.
- Managed Services: Cloud platforms offer managed services like model training, deployment, and monitoring, which reduce the operational overhead of maintaining infrastructure.
- Collaboration: Cloud environments facilitate better collaboration across distributed teams through centralized data storage, version control, and shared workspaces.
- Security: Cloud providers offer advanced security features, such as encryption, access controls, and compliance with various standards (e.g., GDPR, HIPAA).
3.4 Integrating Cloud Infrastructure with MLOps
Integrating cloud infrastructure into your MLOps workflow involves:
- Cloud Storage: Storing datasets, models, and logs in cloud storage services like AWS S3, Azure Blob Storage, or Google Cloud Storage for easy access and management.
- Automating Pipelines: Using cloud-native tools like AWS Step Functions, Azure Pipelines, or Google Cloud Composer to automate the ML pipeline, from data collection to model deployment.
- Monitoring: Leveraging cloud-based monitoring tools like AWS CloudWatch, Azure Monitor, or Google Stackdriver to track model performance and detect issues.
By integrating cloud infrastructure with MLOps practices, you can take full advantage of the cloud's scalability, reliability, and flexibility.
4. Key Challenges in MLOps and Cloud Environments
As with any complex system, implementing MLOps in cloud environments comes with its own set of challenges. These challenges must be carefully managed to ensure smooth, efficient, and reliable ML model development, deployment, and maintenance.
4.1 Scalability and Resource Management
One of the core benefits of the cloud is scalability, but it can also present challenges, particularly when managing resource allocation for machine learning workflows. As models grow in complexity, training on large datasets or running multiple models in parallel, cloud resources (compute, memory, storage) can quickly become a bottleneck.
Key challenges:
- Over-provisioning or Under-provisioning: Properly managing resources to prevent underutilization (wasting money) or overutilization (leading to performance issues).
- Cost Control: Scaling infrastructure in the cloud can lead to increased costs, especially when running resource-intensive models like deep learning networks.
- Auto-Scaling: While cloud providers offer auto-scaling capabilities, it’s important to configure these properly to meet the specific needs of your ML workflows.
Best practices:
- Leverage cloud auto-scaling features to adjust resource usage dynamically based on load.
- Use serverless computing options (e.g., AWS Lambda, Google Cloud Functions) for lightweight tasks.
- Optimize resource allocation by using cloud-native tools to monitor and control costs.
4.2 Security and Data Privacy Concerns
Security and data privacy are critical considerations when working with cloud environments, particularly when handling sensitive data. Machine learning models often require access to large datasets, which can include personal or proprietary information.
Key challenges:
- Data Breaches: Cloud environments must be secured to prevent unauthorized access to sensitive data, which could lead to data leaks or breaches.
- Access Control: Ensuring that only authorized individuals and services have access to training data and deployed models.
- Compliance: Ensuring compliance with regulations like GDPR, HIPAA, and others that govern data usage and privacy.
Best practices:
- Utilize encryption for data at rest and in transit.
- Implement role-based access control (RBAC) to limit permissions and access.
- Use multi-factor authentication (MFA) to secure cloud accounts and services.
- Regularly audit cloud infrastructure to detect any security vulnerabilities or unauthorized access.
4.3 Model Versioning and Experiment Tracking
Tracking the evolution of machine learning models is essential for reproducibility, debugging, and maintaining models in production. In MLOps, managing model versions and experiment tracking becomes increasingly complex as multiple models, datasets, and parameters are involved.
Key challenges:
- Reproducibility: Ensuring that models and experiments can be recreated with the same results.
- Version Control: Managing different versions of models and datasets across multiple environments (development, staging, production).
Best practices:
- Use tools like DVC (Data Version Control) and Git to track changes in data, code, and model artifacts.
- Implement experiment tracking systems (e.g., MLflow) to log parameters, metrics, and results for easy comparison and reproducibility.
4.4 Managing Data Quality and Pipeline Failures
Machine learning models are only as good as the data they are trained on. Poor-quality data can lead to inaccurate or biased models. Additionally, pipeline failures, whether in data collection, processing, or model deployment, can interrupt workflows and reduce the reliability of ML systems.
Key challenges:
- Data Inconsistencies: Inconsistent or incomplete data can lead to model failures.
- Pipeline Failures: ML pipelines that fail to properly collect, preprocess, or serve data to models can bring the entire system down.
Best practices:
- Implement data validation and data cleaning steps to ensure quality data enters the pipeline.
- Use monitoring tools to track pipeline health and trigger alerts when issues arise.
- Apply automated testing at each stage of the pipeline to catch errors early.
4.5 Compliance and Regulatory Issues
As machine learning models increasingly impact industries like finance, healthcare, and government, ensuring compliance with relevant laws and regulations is critical. This includes how data is collected, processed, and used, as well as how models are evaluated and monitored.
Key challenges:
- Regulatory Constraints: Ensuring that models comply with industry-specific regulations such as GDPR, HIPAA, and financial regulations.
- Transparency: Some regulations require that ML models are interpretable and explainable, making it harder to use black-box models in certain scenarios.
Best practices:
- Ensure that data is stored, processed, and transmitted in accordance with relevant privacy laws.
- Use model interpretability tools (e.g., SHAP, LIME) to provide transparency into how models make decisions.
- Regularly audit models for compliance with evolving regulatory standards.
5. Building an End-to-End MLOps Pipeline in Cloud
Creating a robust end-to-end MLOps pipeline in the cloud is essential to streamline and automate the machine learning lifecycle, from data acquisition to model monitoring. An effective pipeline helps automate processes, reduces manual interventions, and ensures that models are continuously updated and maintained.
5.1 Defining the Problem and Data Acquisition
The first step in building an MLOps pipeline is clearly defining the problem to be solved. Once the problem is understood, data must be gathered from various sources—this could include structured data from databases, unstructured data from web scraping, or real-time data from sensors.
Key considerations:
- Data Sources: Identify relevant and high-quality data sources.
- Data Collection: Automate the process of gathering and storing data in cloud storage, ensuring scalability and redundancy.
5.2 Data Preprocessing and Feature Engineering
Once data is collected, it needs to be preprocessed and transformed into a format suitable for machine learning. This step often involves cleaning the data, handling missing values, and performing feature engineering to create meaningful features for model training.
Key considerations:
- Use cloud tools like Google BigQuery or AWS Glue to process large datasets efficiently.
- Automate feature extraction to reduce human intervention and increase pipeline efficiency.
5.3 Model Training and Hyperparameter Tuning
With the data preprocessed, the next step is model training. Machine learning models need to be trained on the data, and this often involves tuning hyperparameters to achieve the best performance.
Key considerations:
- Leverage cloud resources for scalable training, using services like AWS SageMaker, Azure ML, or Google AI Platform.
- Use Hyperparameter optimization tools (e.g., Optuna, Ray Tune) to automatically tune hyperparameters and improve model accuracy.
5.4 Model Evaluation and Validation
After training, the model should be evaluated to ensure it performs as expected. This involves testing the model on unseen data (validation or test set) and measuring its performance using metrics such as accuracy, precision, recall, and F1 score.
Key considerations:
- Cross-validation: To avoid overfitting, use techniques like k-fold cross-validation.
- Use cloud-based experimentation tools to track model performance across different versions.
5.5 Model Deployment Strategies (Online, Batch, Edge)
Once the model is trained and validated, it can be deployed. Different deployment strategies are used depending on the application:
- Online Deployment: Real-time prediction using APIs or serverless functions (e.g., AWS Lambda).
- Batch Deployment: Processing large batches of data periodically for predictions (e.g., AWS Batch).
- Edge Deployment: Deploying models to edge devices for on-site prediction, often used in IoT applications.
5.6 Automating Model Retraining and Monitoring
In an effective MLOps pipeline, models need to be continuously monitored to detect drift or degrade in performance over time. Automated retraining pipelines can trigger model retraining based on performance metrics or data changes.
Key considerations:
- Set up automated pipelines for retraining models using tools like MLflow or Kubeflow.
- Continuously monitor model performance and data quality to ensure models stay accurate in production.
6. Tools and Frameworks for MLOps in the Cloud
Several tools and frameworks are specifically designed to help implement MLOps in cloud environments. These tools automate many aspects of the ML lifecycle, enabling teams to focus on building better models rather than managing infrastructure.
6.1 MLOps Tools for Cloud-Based Development
6.1.1 MLflow
MLflow is an open-source platform that facilitates the management of the ML lifecycle, including experiment tracking, model versioning, and deployment. It integrates easily with cloud platforms like AWS and Azure.
Key features:
- Experiment tracking
- Model packaging
- Serving models in production
6.1.2 Kubeflow
Kubeflow is a Kubernetes-native platform for deploying and managing ML workflows. It’s well-suited for managing large-scale deployments and offers a suite of tools for automation, monitoring, and scaling.
Key features:
- Scalable machine learning workflows
- Integration with Kubernetes
- Pipelines for automated retraining
6.1.3 TensorFlow Extended (TFX)
TensorFlow Extended (TFX) is a production-ready framework built around TensorFlow that helps manage and automate end-to-end machine learning workflows.
Key features:
- Pipelines for continuous deployment
- Integration with TensorFlow
- Data validation and transformation tools
6.1.4 Apache Airflow
Apache Airflow is an open-source tool for orchestrating complex workflows. It is widely used in MLOps to schedule, monitor, and manage tasks within the ML pipeline.
Key features:
- Workflow automation
- Task dependencies and scheduling
- Scalability and integration with cloud environments
6.2 Cloud-Native Tools for MLOps
6.2.1 AWS SageMaker
AWS SageMaker is a fully managed service that provides every step of the machine learning lifecycle—from data preparation to model deployment and monitoring.
Key features:
- Scalable model training
- AutoML tools
- Deployment options for real-time or batch predictions
6.2.2 Azure Machine Learning
Azure ML is a cloud platform for building, training, and deploying machine learning models. It integrates well with Azure's compute and storage services.
Key features:
- Experiment tracking and hyperparameter tuning
- MLOps capabilities for continuous integration and deployment
- End-to-end pipeline management
6.2.3 Google AI Platform
Google AI Platform is a suite of services that helps teams develop, deploy, and manage ML models in the cloud. It provides deep integration with Google Cloud’s ecosystem.
Key features:
- Scalable model training with GPUs and TPUs
- Model deployment with AI Hub
- Integration with Google’s data processing tools (e.g., BigQuery)
7. Best Practices for MLOps in Cloud Environments
Implementing MLOps in cloud environments requires attention to several key best practices to ensure the efficiency, scalability, and success of machine learning workflows. Following these practices will help organizations overcome challenges and streamline the ML lifecycle.
7.1 Standardizing the ML Lifecycle
A well-defined and standardized ML lifecycle is crucial for the successful implementation of MLOps. By standardizing workflows, organizations can reduce errors, ensure repeatability, and improve collaboration between teams.
Key components to standardize include:
- Data Collection: Automate data collection processes and ensure consistency in data sources.
- Data Preprocessing: Standardize preprocessing steps like normalization, feature extraction, and handling missing values to ensure consistency across models.
- Model Training and Validation: Establish clear guidelines for model development, training procedures, and validation criteria to avoid discrepancies across teams and models.
- Deployment and Monitoring: Standardize deployment pipelines and monitoring tools to ensure models are seamlessly integrated into production environments and continuously tracked.
By implementing a standardized approach, teams can build a consistent and reproducible pipeline that simplifies management and enhances collaboration.
7.2 Ensuring Collaboration Across Teams
Collaboration is a key factor in MLOps. In cloud-based environments, data scientists, machine learning engineers, and DevOps teams need to work together closely to deliver models successfully.
Key practices for promoting collaboration:
- Unified Platforms: Use cloud-based tools like Google AI Platform, Azure ML, or AWS SageMaker that offer collaborative features like shared workspaces, version control, and integration with existing development tools (e.g., Git).
- Cross-functional Teams: Foster cross-functional teams that include data scientists, software engineers, and operations specialists. This reduces the silos between teams and encourages sharing knowledge and expertise.
- Clear Communication Channels: Establish regular communication protocols, such as daily stand-ups or weekly reviews, to ensure that everyone is aligned on progress, issues, and goals.
Effective collaboration ensures that all stakeholders are involved in the ML process from development to deployment, making it easier to resolve issues quickly and efficiently.
7.3 Automating ML Pipelines
Automation is a cornerstone of MLOps, enabling teams to reduce manual intervention, improve efficiency, and scale operations. Automating ML pipelines allows for continuous integration (CI), continuous deployment (CD), and automated retraining, ensuring faster updates and lower risk.
Key practices for automation:
- Pipeline Orchestration: Use tools like Kubeflow, Apache Airflow, or MLflow to automate the orchestration of data flows, model training, and deployment.
- Automated Testing: Implement automated unit tests, integration tests, and model validation tests to ensure the quality of models and data before they are deployed.
- Retraining and Versioning: Automate the retraining of models as new data becomes available, and use tools like DVC for data and model versioning to maintain historical context.
By automating every step of the ML pipeline, teams can reduce manual errors, accelerate development cycles, and deploy models with confidence.
7.4 Implementing Continuous Monitoring and Feedback Loops
Continuous monitoring and feedback loops are critical for maintaining model performance in production. Once models are deployed, it is essential to track their performance and detect issues like model drift, data drift, or performance degradation.
Key practices for monitoring:
- Real-time Monitoring: Use cloud-native tools like AWS CloudWatch, Azure Monitor, or Google Stackdriver to track metrics such as latency, error rates, and resource usage in real time.
- Performance Metrics: Regularly evaluate models using performance metrics (accuracy, precision, recall) and retrain them when necessary.
- Automated Alerts: Set up alerts to notify the team when a model's performance falls below a threshold, enabling proactive intervention.
By implementing continuous monitoring and feedback loops, teams can ensure that deployed models stay accurate and operational in the face of changing data and environments.
7.5 Testing and Validating ML Models in Production
Testing and validating models in production is a crucial step to ensure that they function as expected in real-world scenarios. This step includes rigorous testing of model behavior, security, and performance under different conditions.
Key practices for testing and validation:
- A/B Testing: Run A/B tests to compare different models or versions of a model to determine which performs better in production.
- Shadow Testing: Deploy models in "shadow" mode to collect predictions without affecting users, comparing them with the results of the current model to evaluate accuracy.
- Post-Deployment Validation: Once a model is deployed, continuously validate its performance on real-world data to detect issues early.
Thorough testing and validation reduce the risks associated with deploying ML models in production, ensuring that the models deliver accurate and reliable results.
8. Case Studies of Successful MLOps Implementation in the Cloud
Understanding how organizations successfully implement MLOps in the cloud can offer valuable insights into best practices and lessons learned. Here are three examples where MLOps in cloud environments played a pivotal role.
8.1 Case Study 1: Predictive Maintenance in Manufacturing
A global manufacturing company adopted MLOps to optimize its predictive maintenance processes. By using machine learning models to predict when equipment is likely to fail, the company was able to proactively schedule maintenance, reducing downtime and repair costs.
Cloud-based MLOps implementation:
- Data Collection: IoT sensors provided real-time data from machinery.
- Model Deployment: The predictive maintenance models were deployed using AWS SageMaker and continuously monitored.
- Automated Retraining: The models were retrained regularly with new sensor data, improving the accuracy of predictions over time.
Impact:
- Reduced unplanned downtime by 30%.
- Lowered maintenance costs by 25%.
- Improved the lifespan of machinery.
8.2 Case Study 2: Fraud Detection in Financial Services
A financial services company leveraged MLOps to build and deploy a fraud detection system. Using machine learning, the system was able to detect unusual patterns in financial transactions, flagging potentially fraudulent activities in real-time.
Cloud-based MLOps implementation:
- Data Integration: Real-time transaction data was ingested into the cloud.
- Model Development: Fraud detection models were built and trained using Google AI Platform.
- CI/CD Pipelines: MLOps pipelines were set up for continuous training and deployment, ensuring the models adapted to new fraud patterns.
Impact:
- Decreased fraud incidents by 40%.
- Increased the detection accuracy of fraudulent transactions.
8.3 Case Study 3: Personalized Recommendations in E-commerce
An e-commerce company used MLOps to create personalized product recommendations for customers. By deploying machine learning models that analyzed customer behavior, the company was able to provide tailored suggestions to individual users, driving sales and improving customer satisfaction.
Cloud-based MLOps implementation:
- Model Development: Collaborative filtering models were trained using AWS SageMaker.
- Deployment: The models were deployed to the cloud and integrated with the website to serve real-time recommendations.
- Continuous Monitoring: The models were continuously monitored for accuracy and retrained as customer behavior changed.
Impact:
- Increased conversion rates by 20%.
- Improved customer engagement and retention.
9. The Future of MLOps and Cloud Computing
The future of MLOps in cloud environments looks promising, with advancements in automation, AI, and cloud technologies paving the way for even more sophisticated workflows.
9.1 Trends in Cloud MLOps
As cloud computing continues to evolve, several trends are shaping the future of MLOps:
- Hybrid and Multi-cloud Environments: Organizations are increasingly adopting hybrid or multi-cloud strategies, using multiple cloud providers to ensure redundancy, reduce vendor lock-in, and optimize costs.
- Serverless MLOps: Serverless computing is gaining popularity in MLOps, allowing teams to run machine learning models without managing infrastructure, reducing costs and complexity.
- AutoML: AutoML tools are enabling organizations to automate the process of selecting and tuning models, making machine learning more accessible to non-experts.
9.2 AI and Automation’s Role in Future MLOps Workflows
AI and automation will play an increasingly important role in MLOps workflows. Automation will be key in areas like:
- Model Retraining: Automating model retraining when data changes or performance degrades.
- Pipeline Orchestration: Fully automated pipelines for data processing, model training, validation, and deployment.
- AI-Driven Decisions: AI models themselves will assist in making decisions about model updates, pipeline configurations, and resource allocation.
The rise of AI and automation will reduce manual intervention and allow organizations to focus more on improving model performance and less on operational tasks.
9.3 The Evolving Role of Data Engineers and ML Engineers
As MLOps becomes more prevalent, the roles of data engineers and ML engineers will continue to evolve:
- Data Engineers will focus more on building scalable data pipelines, ensuring data quality, and integrating different data sources into cloud environments.
- ML Engineers will be responsible for deploying models at scale, managing the lifecycle of models in production, and ensuring that models remain performant over time.
Both roles will need to work closely with DevOps teams and embrace the automation tools available to streamline processes across the ML lifecycle.






