
1. Introduction
In modern data workflows, ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) represent two core approaches for moving and processing data between systems. Both methods involve similar steps—extraction from a source, transformation of the data, and loading into a destination—but the order in which these steps occur changes how they perform, scale, and integrate with infrastructure.
Historically, ETL emerged in the era of on-premise data warehouses. It was designed to perform data transformation before loading, often using external compute engines or middleware. ELT, by contrast, gained popularity with the rise of cloud-native data warehouses that could scale compute and storage independently. In ELT, raw data is loaded first, and transformations are executed inside the destination system—typically a cloud data platform like Snowflake or BigQuery.
As cloud adoption grows and data ecosystems evolve, the decision between ETL and ELT is no longer just about tools or workflows—it's a matter of architectural fit, team capability, cost, and performance. Understanding the distinctions is critical for building efficient, maintainable, and future-proof data pipelines in cloud-native environments.
2. Foundational Concepts
2.1 Defining ETL (Extract, Transform, Load)
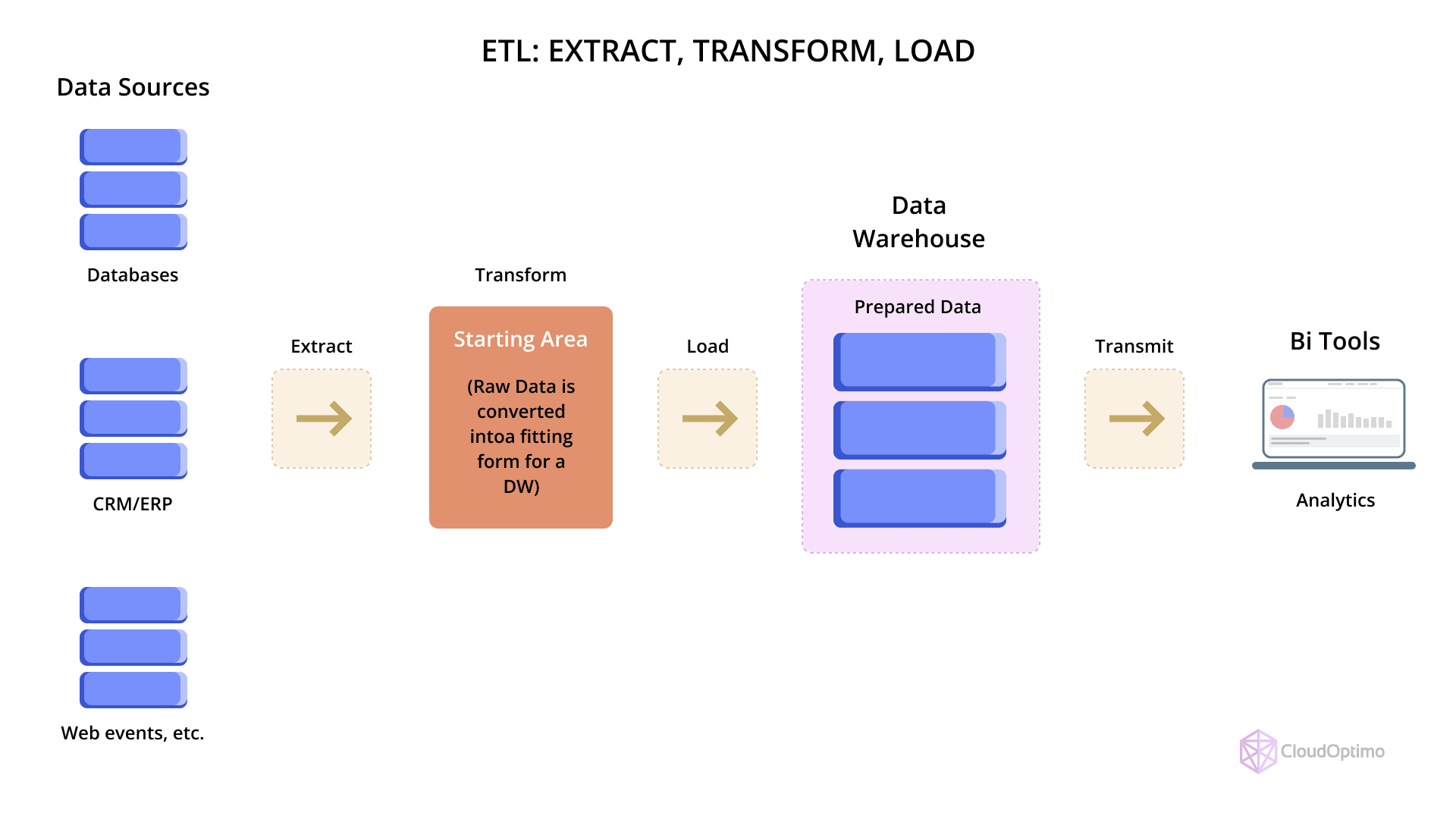
ETL is a traditional data integration process where data is extracted from source systems, transformed into the desired format, and then loaded into a destination, usually a data warehouse. The transformation stage typically involves data cleaning, enrichment, filtering, and reshaping. These transformations occur before loading, often on dedicated ETL servers or through batch scripts. ETL is structured, rule-driven, and is best suited for environments with strict data quality and schema enforcement requirements.
2.2 Defining ELT (Extract, Load, Transform)
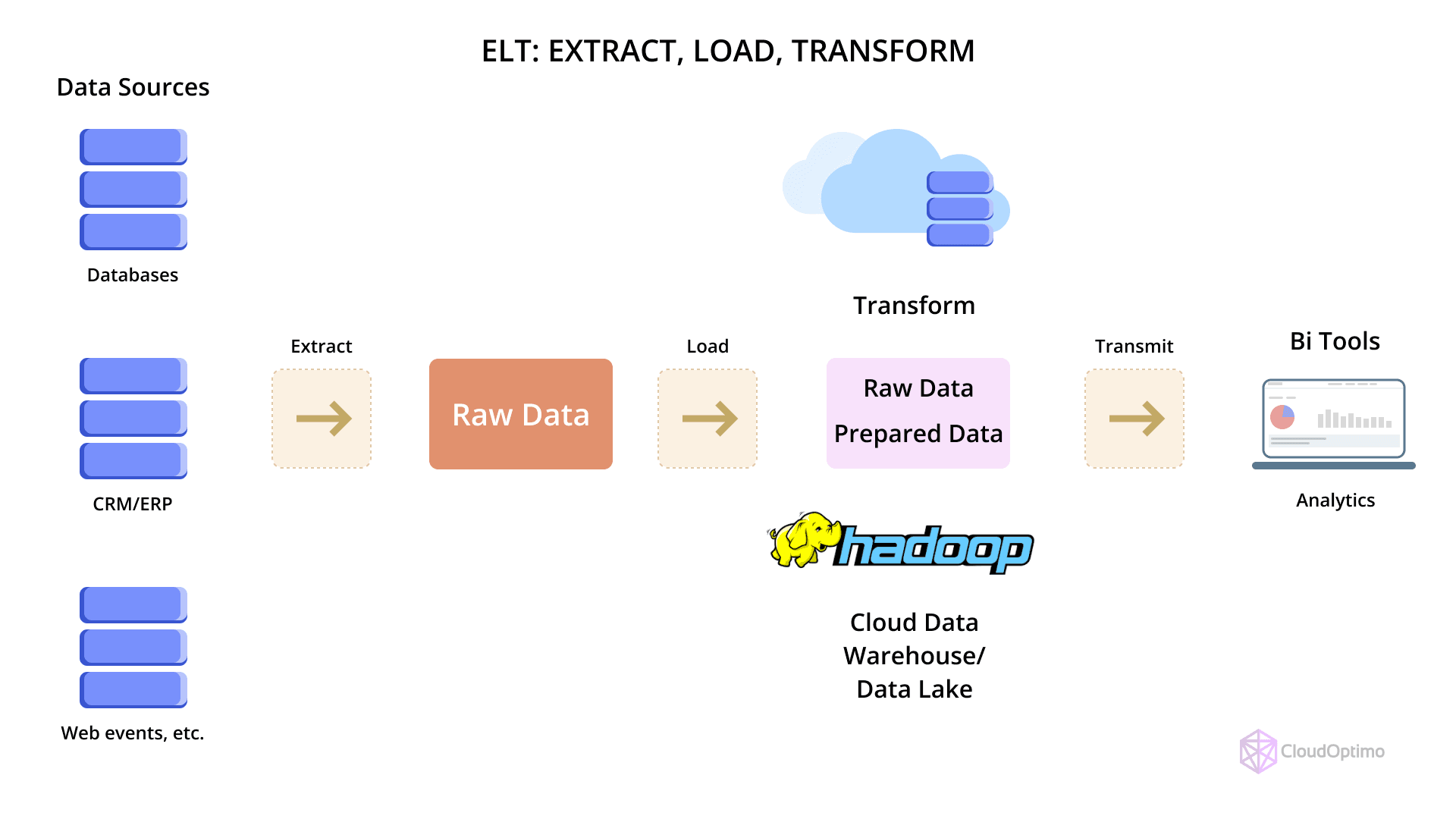
ELT reverses the traditional order by loading raw data first into a storage layer (often a cloud data warehouse) and performing transformations afterward, using the compute resources of the destination system. This approach leverages the scalability and processing power of modern cloud platforms to execute SQL-based or declarative transformations on large datasets directly within the warehouse. ELT supports a more agile data pipeline, where raw data is preserved and transformations can be versioned or rerun as needed.
2.3 Core Differences Between ETL and ELT
The key distinction lies in where and when the transformation happens:
- ETL: Transformations occur before data is loaded into the destination.
- ELT: Transformations occur after loading, inside the destination.
Other differences include:
- Compute Location: ETL uses external compute; ELT uses warehouse-native compute.
- Data Handling: ETL favors curated, schema-enforced pipelines; ELT allows more flexibility with semi-structured and raw data.
- Tooling: ETL pipelines often use enterprise ETL tools (e.g., Informatica, Talend), while ELT workflows use tools like dbt combined with modern warehouses.
3. The Evolution of Data Stacks
3.1 Traditional Data Stacks and the Rise of ETL
In early enterprise systems, data was stored in siloed operational databases. To analyze this data, organizations adopted on-premise data warehouses like Teradata, Oracle, or SQL Server. These systems had limited compute and storage capacity, requiring heavy data transformation before ingestion to avoid overloading them. ETL tools emerged to handle this need—extracting data from transactional systems, transforming it in middleware, and loading only the cleaned data into the warehouse.
3.2 Emergence of Cloud-native Architectures
With the rise of cloud computing, data infrastructure shifted dramatically. Cloud-native platforms decoupled compute from storage, allowing data teams to scale resources elastically. Tools like Amazon Redshift, Google BigQuery, and Snowflake offered managed services with automatic scaling, serverless execution, and pay-as-you-go pricing. This eliminated many of the performance constraints that made pre-load transformation necessary, paving the way for ELT to emerge as a dominant model.
3.3 Why ELT Gained Traction in Cloud-native Environments
Cloud-native warehouses are optimized for in-database processing, making it more efficient to load raw data quickly and perform transformations at scale using SQL or analytics engines. This approach supports:
- Faster ingestion from diverse sources.
- Schema-on-read flexibility.
- Simplified debugging and data lineage.
- Reduced operational overhead since transformation logic can be version-controlled and managed as code.
As cloud-native tools evolved, ELT became the default choice for teams prioritizing agility, scalability, and modern DevOps practices in data engineering.
4. Cloud-native Data Stack Components
4.1 Cloud Data Warehouses (e.g., Snowflake, BigQuery, Redshift)
These platforms serve as the core of ELT pipelines. They store large volumes of structured and semi-structured data and provide in-database compute to run transformations. Each warehouse offers different advantages:
- Snowflake supports multi-cluster compute and zero-copy cloning.
- BigQuery uses a serverless architecture with automatic scaling.
- Redshift offers deep integration with the AWS ecosystem.
4.2 Data Lakes and Lakehouses
Data lakes (e.g., Amazon S3, Azure Data Lake Storage) store raw data in various formats (CSV, JSON, Parquet) without requiring strict schemas. Lakehouses combine the flexibility of lakes with the performance and structure of warehouses. Tools like Databricks and Delta Lake enable SQL-style analytics and ACID transactions over lake-stored data, making them viable for both ETL and ELT workflows.
4.3 Orchestration Tools (e.g., Airflow, Dagster)
Orchestration platforms coordinate the execution of complex data pipelines.
- Airflow is a widely used open-source scheduler that defines workflows as Python code.
- Dagster offers more structured typing and observability, focusing on data-aware pipeline design.
These tools manage dependencies, schedule tasks, handle retries, and integrate with cloud services.
4.4 Transformation Tools (e.g., dbt)
Tools like dbt (data build tool) enable SQL-based transformation logic to be written, version-controlled, and tested like software. dbt compiles SQL models into dependency graphs and runs them inside the data warehouse, making it ideal for ELT workflows. It also supports documentation, testing, and lineage tracking out of the box.
4.5 Integration Tools (e.g., Fivetran, Stitch)
These tools automate data extraction and loading from SaaS platforms (like Salesforce, Shopify, or Google Analytics) into cloud data warehouses.
- Fivetran provides fully managed connectors with automated schema management.
- Stitch offers a simpler, open-source-friendly alternative.
Both are commonly used to feed data into ELT pipelines, offloading the complexity of API integrations and ingestion.
5. ETL in Cloud-native Context
5.1 Workflow and Architecture
In a cloud-native ETL setup, data is first extracted from source systems—databases, APIs, logs, etc.—using connectors or scripts. The transformation phase happens outside the destination warehouse, typically in a cloud-based ETL tool, serverless function, or containerized processing service (e.g., AWS Glue, Azure Data Factory). After transformation, the cleaned and structured data is loaded into a cloud data warehouse for analysis.
While the infrastructure has moved to the cloud, the core workflow remains transformation-first. The architecture still involves staging layers, batch processing, and dependency management, often orchestrated via tools like Airflow.
5.2 Pros of ETL in the Cloud
- Pre-load data validation: Errors are caught before data reaches the warehouse.
- Lower warehouse compute usage: Since transformations occur upstream, warehouses don’t need to spend resources on processing raw data.
- Mature governance workflows: ETL fits well in regulated environments that require strict control over data shape and lineage.
- Fine-tuned transformation logic: External processing layers allow use of general-purpose languages (Python, Scala, Java) beyond SQL.
5.3 Cons of ETL in the Cloud
- Slower development cycles: Pre-load transformation increases pipeline complexity and time-to-insight.
- Harder debugging: Errors discovered post-load require full pipeline reruns.
- Scalability limits: External transformation engines may not scale as elastically as cloud-native warehouses.
- Data loss risk: If transformation logic fails or discards information, the raw data is often unrecoverable unless separately archived.
5.4 Use Cases Where ETL Still Makes Sense
- High-sensitivity data pipelines (e.g., financial reporting or regulatory compliance) where schema enforcement and data integrity are critical.
- Heavily structured operational data (e.g., ERP systems) that must meet strict format standards before ingestion.
- Workflows with non-SQL transformations, such as complex natural language parsing or geospatial data processing.
6. ELT in Cloud-native Context
6.1 Workflow and Architecture
In ELT, data is extracted from source systems and immediately loaded into the cloud data warehouse in its raw form. Once the data resides in the warehouse, transformation logic is executed inside the warehouse, usually using SQL or a tool like dbt. This setup takes advantage of the warehouse's elastic compute and allows analysts and engineers to iterate on transformation logic without re-running entire ingestion processes.
ELT architectures often skip staging environments and rely on versioned transformations, modular SQL models, and lightweight orchestration to manage dependencies.
6.2 Pros of ELT in the Cloud
- Faster ingestion: Raw data is landed in the warehouse quickly, allowing immediate access for exploration.
- Greater scalability: Cloud warehouses can parallelize and auto-scale transformation workloads.
- More flexible pipelines: Raw data is preserved, enabling retrospective changes in transformation logic.
- Simpler infrastructure: Fewer moving parts compared to external ETL engines.
6.3 Cons of ELT in the Cloud
- Higher warehouse compute costs: Transformations are executed inside the warehouse, which may increase usage billing.
- Harder to enforce data contracts: Raw data arrives before validation, increasing the risk of downstream schema mismatches.
- Dependency on warehouse features: ELT assumes that your warehouse supports complex SQL transformations and has sufficient performance for large-scale operations.
6.4 Ideal Use Cases for ELT
- Analytics-driven teams who want to iterate quickly and need flexibility in data modeling.
- Startups and cloud-native companies with no legacy infrastructure and a need for low-maintenance pipelines.
- Environments using modern BI and data ops tools, where transformation-as-code (e.g., dbt) is part of the workflow.
7. Side-by-Side Comparison
Below is a structured comparison across critical decision factors:
| Dimension | ETL (Extract → Transform → Load) | ELT (Extract → Load → Transform) |
| Transformation Location | Outside the warehouse (ETL tool/serverless function) | Inside the warehouse (SQL/dbt/etc.) |
| Speed to Insight | Slower—transformation delays load | Faster—data available immediately after load |
| Compute Efficiency | Offloads transformation from the warehouse | Uses warehouse compute for transformations |
| Pipeline Complexity | More components; transformation and load are decoupled | Simpler architecture; all steps run in a central platform |
| Error Handling | Errors caught early before loading | Errors may appear downstream during transformation |
| Flexibility | Less flexible; rigid schema often required early | High flexibility; raw data is retained |
| Cost Management | Potential cost savings via external compute | Cost depends on warehouse pricing and optimization |
| Tool Ecosystem | Mature ETL tools, often enterprise-grade (e.g., Informatica) | Modern, code-first tools (e.g., dbt, Fivetran, Snowflake) |
| Governance & Compliance | Strong pre-load validation and control | Requires tight post-load monitoring and transformation tests |
| Best For | Legacy systems, financial data, regulatory-heavy use cases | Agile teams, startups, cloud-native analytics environments |
8. Choosing Between ETL and ELT
Choosing between ETL and ELT depends on your team’s goals, technical landscape, and organizational constraints. There is no one-size-fits-all approach—each method offers distinct strengths, and understanding them in the context of your use case is critical.
The table below summarizes how different factors influence the decision:
| Criteria | When ETL Is a Better Fit | When ELT Is a Better Fit |
| Data Sensitivity & Compliance | You need to validate, clean, or mask data before it lands in storage (e.g., healthcare, finance) | You can load raw data securely and apply governance post-load |
| Transformation Complexity | Logic involves advanced processing or non-SQL operations (e.g., NLP, image parsing) | Transformations can be expressed as SQL or handled inside the warehouse |
| Team Skill Set | Engineering-heavy team with Python/Scala/Java experience | Analyst-led team comfortable with SQL and dbt |
| Infrastructure Constraints | You want to minimize data warehouse usage and cost | You rely on warehouse scalability and elasticity |
| Pipeline Agility & Speed | Preprocessing steps are critical, even if ingestion is slower | Rapid ingestion and fast iteration on models is a priority |
| Data Lineage & Control | Strong control is required over how data is shaped before storage | Raw data storage and version-controlled transformation is acceptable |
For example, a bank with strict data retention policies might opt for ETL to validate and mask data before storage, while a SaaS analytics team may use ELT for rapid ingestion and flexibility in building dashboards. It’s important to treat this as a framework—not a rulebook—since hybrid setups are increasingly common.
9. Hybrid Approaches and Future Trends
While ETL and ELT are often positioned as opposites, modern data workflows rarely follow one model exclusively. Many organizations adopt hybrid approaches that combine both, using the right strategy for each part of the pipeline based on business and technical needs.
9.1 Blending ETL and ELT: When and Why
In a hybrid pipeline, structured and sensitive data might undergo ETL processing before landing in a warehouse, ensuring compliance and accuracy. At the same time, less critical or exploratory data—such as product logs or marketing metrics—can be ingested through ELT for faster analysis.
A typical example would involve ETL for loading CRM data where customer PII is masked before warehouse storage, and ELT for ingesting clickstream data that’s later modeled into user behavior metrics. This blending provides both governance and agility in the same ecosystem.
Rather than choosing one over the other, modern teams segment pipelines by data domain, data owner, or system performance characteristics.
9.2 Emerging Trends: Reverse ETL, Data Mesh, and Streaming Pipelines
The traditional flow of data has also begun to reverse. Reverse ETL pushes enriched data from warehouses back into operational systems like CRMs or ad platforms. This enables use cases like sales alerts, customer segmentation, and personalization—all powered by warehouse-modeled data.
Another major trend is the Data Mesh approach, which treats data as a product and decentralizes pipeline ownership to domain teams. This encourages autonomy but requires platforms that support both ETL and ELT patterns across teams and data products.
Finally, streaming ETL/ELT is transforming how real-time data is handled. Technologies like Apache Kafka, Flink, and Materialize allow data to be ingested and transformed in near real-time, blurring the lines between batch and stream processing. Streaming-first architectures often involve mini-ETL steps at ingestion and ELT-like modeling at the warehouse or lakehouse layer.
9.3 How Modern Data Teams Are Evolving
Today’s data teams are embracing modular, code-first, and version-controlled workflows. The rise of tools like dbt, Airbyte, and modern observability platforms reflects a broader shift toward treating data pipelines as software. This includes:
- Writing transformation logic as reusable code
- Implementing CI/CD pipelines for data deployments
- Monitoring pipeline health with alerting and lineage tools
As a result, the rigid distinction between ETL and ELT is fading. Teams now choose approaches based on domain-level needs, infrastructure maturity, and collaboration models rather than technical dogma.
10. Conclusion
10.1 Summary of Key Points
ETL and ELT are not just technical choices—they represent different strategies for handling data in modern organizations. ETL offers structured control and pre-load validation, making it ideal for sensitive, compliance-heavy environments. ELT, on the other hand, embraces the flexibility and scalability of cloud-native systems, making it well-suited for agile, SQL-centric teams.
As cloud data infrastructure has evolved, ELT has gained popularity due to its simplicity and speed. However, ETL remains relevant for use cases where early-stage data quality and transformation are essential.
10.2 Final Recommendations
When choosing between ETL and ELT:
- Start with your constraints: data types, regulatory requirements, skillsets, and infrastructure costs.
- Don’t default to a single model—use a hybrid approach if your pipelines vary in complexity and sensitivity.
- Invest in observability, modularity, and transformation testing regardless of the approach you use.
The best strategy is one that balances performance, governance, and development velocity while aligning with the evolving needs of your business.






