
Organizations are leveraging data to make informed business decisions in today’s fast-paced digital world. However, managing this data requires the right infrastructure. Two primary architectures — Data Warehouse and Data Lake — have emerged as leading solutions for enterprises to store, process, and analyze their data.
Both have their unique strengths, challenges and ideal use cases. However, deciding which one to use can be confusing, especially since they serve overlapping but distinct purposes.
This blog will give you an in-depth comparison of data warehouses and lakes, guiding technical and novice readers to understand which solution best suits specific business needs.
What is a Data Warehouse?
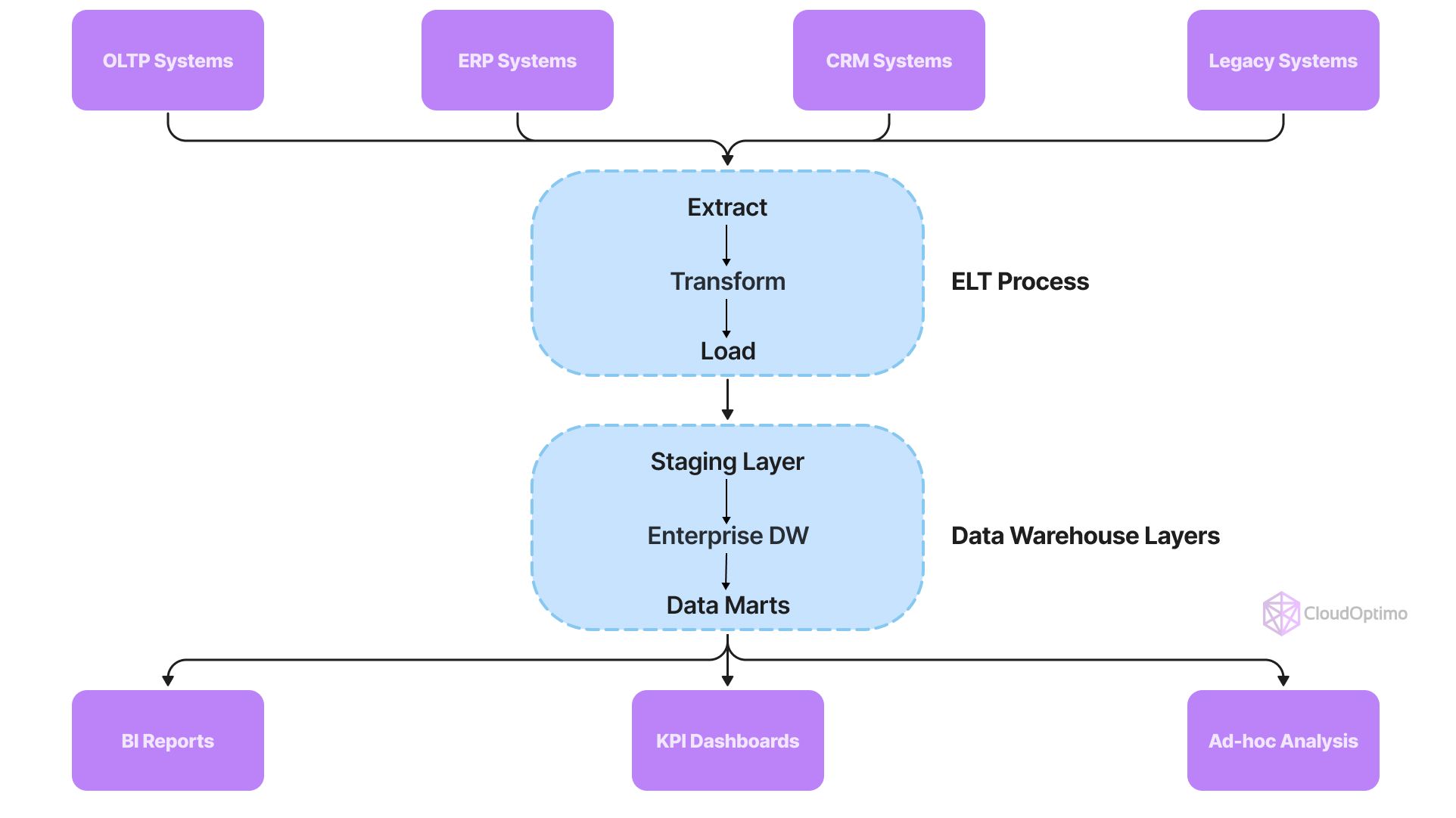
A data warehouse is a structured data repository designed to store, organize, and analyze large volumes of historical data from multiple sources. Typically, it is used to facilitate business intelligence (BI) and analytics by providing a combined view of data.
Data warehouses rely heavily on schema-on-write, meaning the data structure is predefined before storage. This structured format makes it easier to run complex queries quickly and generate reports, dashboards, and visualizations for decision-making.
Key Features of Data Warehouse:
- Structured data: Data warehouses store highly organized and relational data.
- Schema-on-write: Data must be transformed and cleaned before entering the warehouse.
- Optimized for querying: Built to support complex queries and reporting.
- Historical data: Often contains historical datasets for trend analysis.
Examples of Data Warehouse Platforms:
Real-World Case Study: Global Retail Chain
A leading retail chain implemented Snowflake as their data warehouse solution to consolidate point-of-sale data from 2,000+ stores worldwide.
Results:
- 70% reduction in report generation time
- 99.9% data accuracy
- $2M annual savings in operational costs
- Real-time inventory management across all stores
Data Warehouse Security Implementation
- Authentication
- Multi-factor authentication
- Role-based access control (RBAC)
- Single sign-on (SSO) integration
- Authorization
- Column-level security
- Row-level security
- Dynamic data masking
- Audit
- Query logging
- Access logging
- Change tracking
What is a Data Lake?
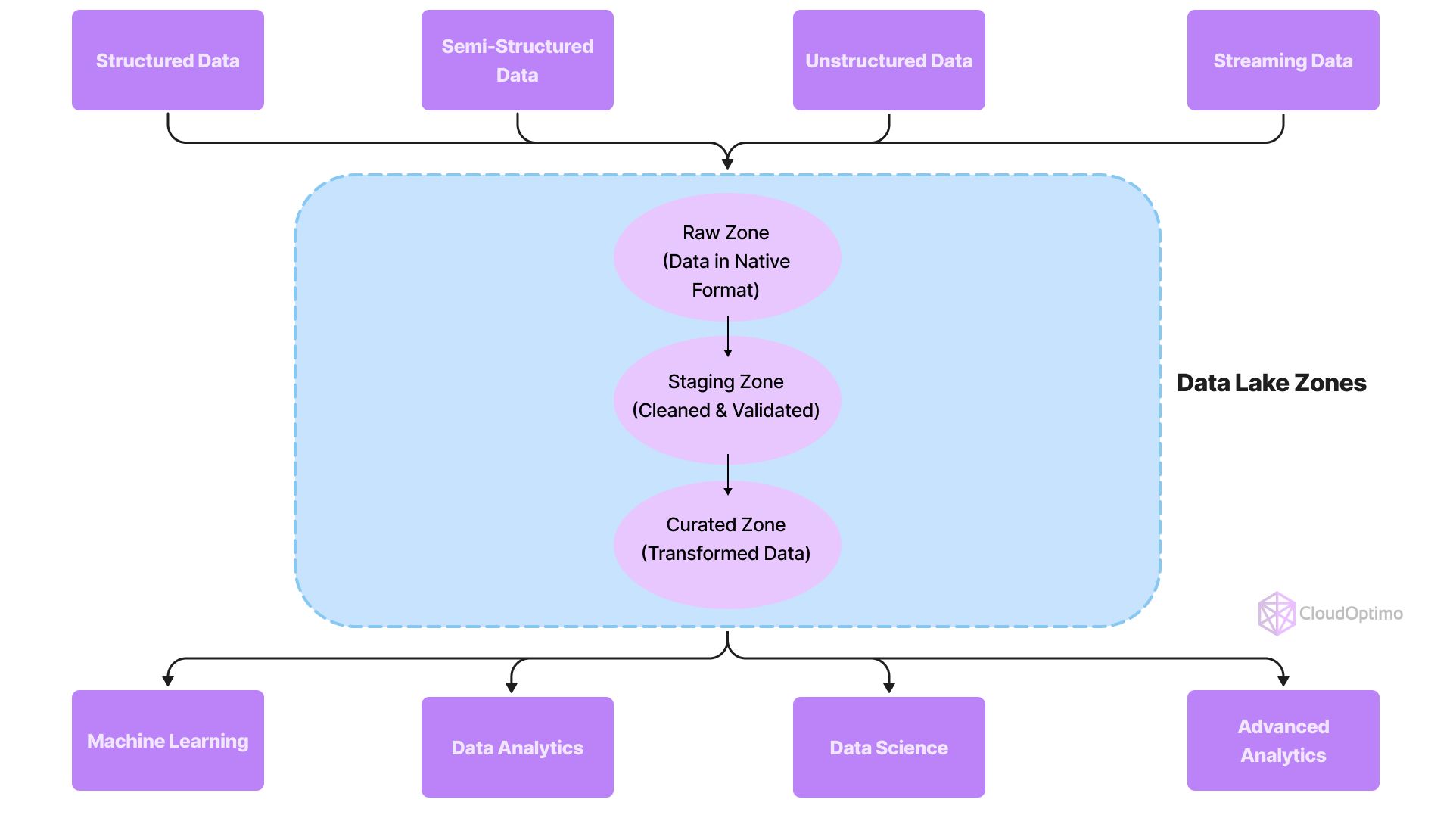
In contrast, a data lake stores raw, unprocessed data. It can handle various data types — from structured relational data to unstructured data such as logs, images, or audio files. Data lakes are built for big data analytics and exploratory analysis and use a schema-on-read approach, meaning the data is processed only when it is needed for analysis.
They are more flexible than data warehouses, allowing organizations to store data without worrying about its format or immediate use. However, this flexibility requires careful management to ensure data quality and consistency.
Key Features of Data Lake:
- Raw and unstructured data: Can store data in its original format without preprocessing?
- Schema-on-read: Data is transformed only when accessed for analysis.
- Supports multiple data types: Handles structured, semi-structured, and unstructured data.
- Scalable and cost-effective: Easily scales to store massive datasets at low costs.
Examples of Data Lake Platforms:
- Amazon S3 (Simple Storage Service)
- Azure Data Lake Storage
- Google Cloud Storage
- Hadoop Distributed File System (HDFS)
Architectural Deep Dive
As organizations move towards data-driven strategies, understanding how to structure data for different platforms becomes critical. Both data warehouses and data lakes offer unique architectures tailored to specific needs. Below, we explore the most common modeling practices to guide organizations in selecting the right approach.
Data Warehouse Modeling
Dimensional Modeling
Dimensional modeling structures data to simplify reporting and analytics by organizing it into facts (measurable metrics) and dimensions (descriptive attributes).
- Star Schema:
- Central fact table linked to multiple dimension tables.
- Best for simple queries and fast performance.
- Use Case: Financial reports requiring quick insights into revenue, sales, and expenses.
- Snowflake Schema:
- Dimensions are normalized into multiple related tables.
- Reduces data redundancy at the cost of slightly more complex queries.
- Use Case: Customer analytics where dimension data needs to be more granular and standardized.
- Galaxy Schema:
- Multiple fact tables sharing common dimension tables.
- Ideal for complex analytics across multiple business domains.
- Use Case: E-commerce platforms tracking sales and product data across different regions.
- Star Schema:
Data Vault 2.0
Data Vault is a modern approach focusing on scalability and flexibility, designed for fast-changing and complex environments.
- Hubs: Store unique business keys.
- Links: Define relationships between hubs.
- Satellites: Store descriptive data, enabling historical tracking.
- Use Case: Organizations with rapidly evolving datasets, such as retail chains or financial services, benefit from Data Vault for auditability and history tracking.
Current Trends
In recent years, the Data Vault 2.0 modeling approach has gained popularity due to its ability to handle complex and evolving data landscapes effectively. Organizations increasingly prefer this model as it allows for greater scalability and flexibility in integrating new data sources while ensuring robust historical tracking and accountability. However, traditional dimensional modeling methods remain widely used for their simplicity and efficiency in reporting, especially in more stable environments.
Data Lake Modeling
Delta Lake Architecture
Delta Lake enhances traditional data lakes by introducing ACID transactions and version control, ensuring reliable data pipelines.
- Bronze Layer (Raw Data): Contains raw ingested data in its native format.
- Use Case: Logs from IoT devices stored without processing.
- Silver Layer (Cleaned Data): Data that has been cleaned, deduplicated, and validated.
- Use Case: Cleaned sales data used for trend analysis.
- Gold Layer (Business-Ready Data): Aggregated and enriched data, ready for business use.
- Use Case: Data powering dashboards and business intelligence reports.
- Bronze Layer (Raw Data): Contains raw ingested data in its native format.
Medallion Architecture
This is another layered approach to data lake design, often used for large-scale big data solutions.
- Landing Zone: Temporary storage for newly ingested raw data.
- Use Case: Data arriving from third-party APIs or batch processes.
- Raw Zone: Stores unprocessed data in its original form.
- Use Case: Collecting clickstream data from web applications.
- Trusted Zone: Data that has passed basic validation and cleansing.
- Use Case: Transaction data ready for further analytics.
- Refined Zone: Fully processed and curated data, ready for consumption.
- Use Case: Data used to generate business insights and reports.
- Landing Zone: Temporary storage for newly ingested raw data.
Current Trends
Recently, the Delta Lake architecture has become increasingly preferred due to its robust features like ACID transactions and versioning, which enhance data reliability and governance in data lakes. This architecture allows organizations to maintain data integrity and streamline data operations, making it ideal for dynamic environments that require consistent data quality. However, the Medallion architecture remains popular among organizations focused on scalable big data solutions, providing clear staging areas for data processing and ensuring that analytics-ready data is efficiently curated.
Why Do These Architectures Matter?
Understanding these frameworks helps align data strategy with business needs. For example:
- Data warehouses benefit from dimensional modeling to ensure fast and reliable business intelligence.
- Data lakes require architectures like Delta Lake or Medallion to efficiently manage large datasets, enabling data science and AI projects.
- Data Vault 2.0 bridges the gap between historical tracking and scalability, supporting enterprises dealing with continuous data changes.
Core Differences Between Data Warehouse and Data Lake
Aspect | Data Warehouse | Data Lake |
Data Type | Structured and relational data | Structured, semi-structured, and unstructured data |
Schema | Schema-on-write | Schema-on-read |
Purpose | Business intelligence and reporting | Big data analytics and exploratory analysis |
Data Transformation | Data cleaned and transformed before loading | Data stored in raw format |
Cost | More expensive due to compute and storage | Cost-effective with scalable storage |
Performance | Optimized for fast querying | May require additional processing for queries |
Storage | Limited to structured data types | Capable of storing large, diverse datasets |
Technology Examples | Amazon Redshift, Snowflake, BigQuery | Amazon S3, Azure Data Lake, HDFS |
Comprehensive Comparison Matrices
Performance Metrics
This matrix compares the key performance attributes of data warehouses and data lakes to help you decide which platform aligns with your operational needs.
Metric | Data Warehouse | Data Lake |
Query Response Time | Sub-second for optimized queries | Varies (seconds to minutes, based on query complexity) |
Data Ingestion Speed | Slower due to data transformation processes | Fast, as raw data is ingested directly |
Concurrent Users | High (supports 100s of users) | Medium (supports 10s of users) |
Data Processing | Batch-optimized (ideal for reporting) | Supports both batch and streaming processing |
Maintenance Requirements
Data warehouses and data lakes have different management needs. This table highlights the level of effort required for maintenance.
Aspect | Data Warehouse | Data Lake |
Schema Management | High (predefined schema) | Low (schema-on-read) |
Data Quality | Continuous enforcement | As needed, often during query time |
Storage Management | Requires regular management | Minimal due to flexible data structures |
Performance Tuning | Frequent tuning required | Occasional, only for complex queries |
Scalability Aspects
This section compares how each architecture scales with data growth, user demand, and compute needs.
Feature | Data Warehouse | Data Lake |
Storage Scaling | Linear cost increase | Nearly linear cost, with cheaper options for bulk storage |
Compute Scaling | Step-function costs (manual scaling) | Pay-per-query (scalable on-demand compute) |
Query Complexity | Limited by rigid schema structure | Limited only by processing power and algorithms |
Data Type Support | Limited to structured, relational data | Extensive (supports structured, semi-structured, and unstructured data) |
When to Use a Data Warehouse?
A data warehouse is the preferred choice for structured, business-critical data. It’s well-suited for organizations with a need for consistent and reliable reporting, trend analysis, and business intelligence tools.
Ideal Use Cases:
- Financial Reporting: Accurate, consistent, and historical financial data is essential for quarterly or annual reports.
- Customer Analytics: When analyzing customer behavior with a structured dataset.
- Sales Dashboards: Business teams need instant access to key metrics, such as revenue, profits, or customer acquisition rates.
- Compliance Requirements: Industries like healthcare and finance benefit from data warehouses due to their structured and regulatory-compliant nature.
When to Use a Data Lake?
Data lakes shine when dealing with large, diverse datasets for use cases involving exploratory analysis, machine learning (ML), and AI. They are also valuable for organizations that need to store raw data for future processing or experimentation.
Ideal Use Cases:
- Machine Learning & AI: Data lakes store large datasets needed for model training.
- IoT Data Storage: Sensor data from IoT devices can be ingested without transformation.
- Log and Clickstream Data: Raw logs from applications and websites are ideal for data lakes.
- Data Archival: Store historical or unused data in a low-cost, scalable format
Challenges of Data Warehouses and Data Lakes
Data Warehouses:
- High Costs: Data warehouses require more expensive storage and compute resources.
- Limited Data Types: They are not ideal for handling unstructured data.
- Complex Setup: Building and maintaining a data warehouse involves significant effort.
Data Lakes:
- Data Quality Issues: With no mandatory data transformation, raw data can be messy.
- Slow Query Performance: Running queries on unprocessed data can be slow.
- Data Governance Challenges: Managing security and access control is more difficult.
Can Data Lakes and Data Warehouses Coexist?
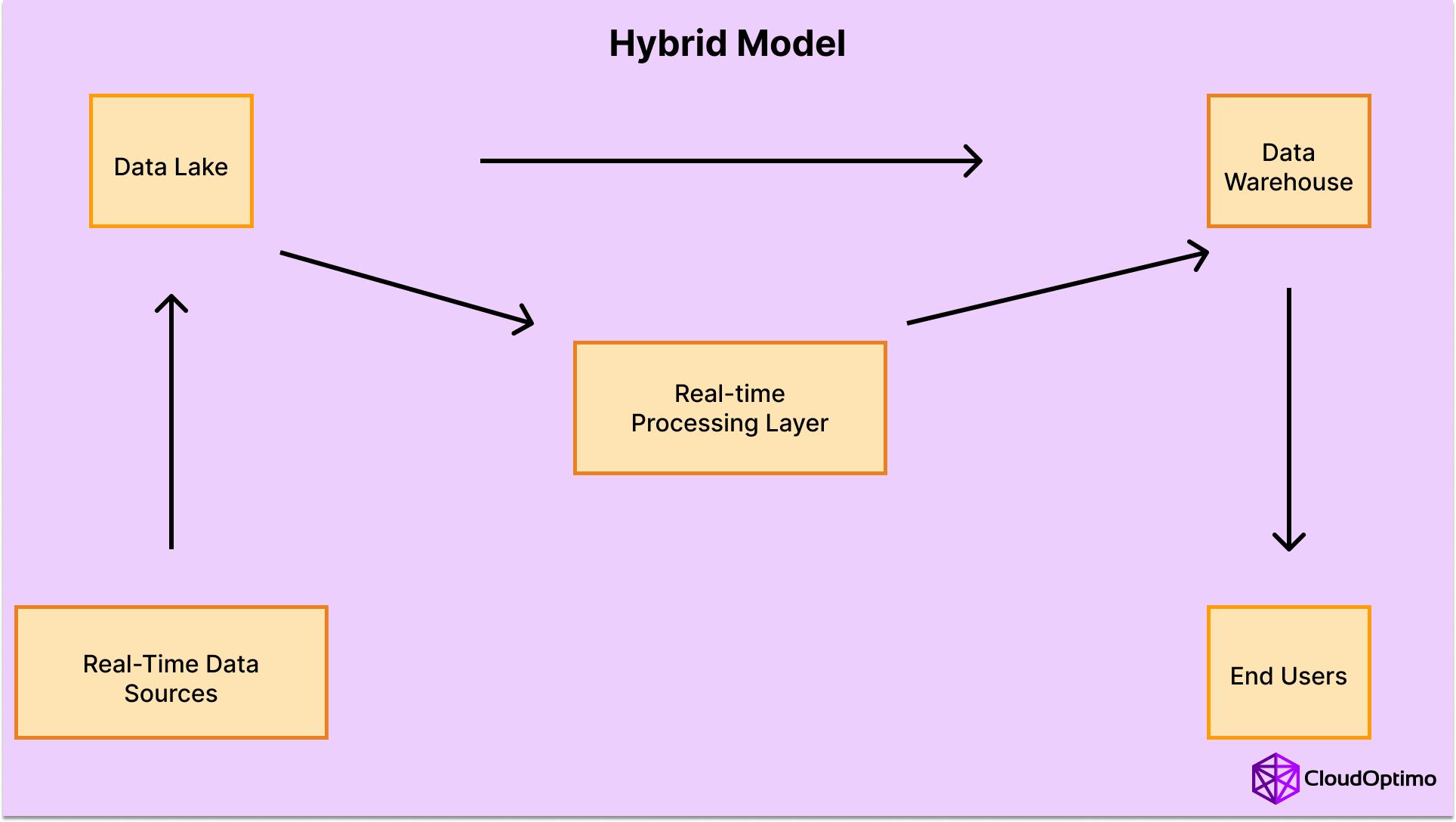
Many modern organizations adopt a hybrid approach, where both data lakes and data warehouses coexist to serve different purposes. This approach leverages the strengths of each system:
- Data Lake as Storage: Collects raw, unprocessed data from various sources.
- Data Warehouse for Analysis: Extracts and transforms data from the lake for business reporting and analytics.
This combination ensures scalable storage and high-performance querying, helping organizations maximize value from both structured and unstructured data.
Migration Strategies
Migrating to a data warehouse or data lake involves strategic planning to avoid disruptions, ensure data integrity, and improve performance. Different approaches can be adopted based on business goals, timelines, and risk tolerance.
Data Warehouse Migration Strategies
When migrating to a data warehouse, businesses usually consider two main approaches:
- Lift-and-Shift Migration
- What It Is: A straightforward transfer of data and schema from an existing system to the new data warehouse.
- Key Features:
- Minimal data transformation.
- Quick implementation with fewer modifications.
- Useful when you need to move fast or if the existing schema is already aligned with the new warehouse’s requirements.
- Challenges:
- Might not optimize the new platform’s full potential.
- Performance issues may arise if legacy structures are not optimized.
- Redesign and Migrate
- What It Is: A more sophisticated approach involving schema redesign and data model improvements.
- Key Features:
- Optimize schema for the target platform.
- Improve query performance and reporting capabilities.
- Ensure better alignment with business needs through data model enhancements.
- Challenges:
- Takes longer to implement.
- Requires expertise and thorough testing to avoid disruptions.
Data Lake Migration Strategies
Data lake migrations allow more flexibility but require careful management of large and diverse datasets.
- Parallel Implementation
- What It Is: A phased approach where the new data lake is built alongside the existing system.
- Key Features:
- Enables a gradual data migration with minimal risk.
- Phased cutover allows teams to verify functionality and performance before fully switching.
- Challenges:
- Requires maintaining two systems simultaneously.
- Can be resource-intensive over extended timelines.
- Big Bang Migration
- What It Is: A complete and immediate switch to the new data lake.
- Key Features:
- Shorter overall migration timeline.
- All data and workloads move at once, minimizing parallel operations.
- Challenges:
- Requires extensive pre-migration testing to prevent failures.
- Higher risks if issues arise post-migration, as there’s no fallback system.
Troubleshooting Guide
Managing data warehouses and data lakes can present operational challenges. Here's a list of common issues and their solutions, along with proactive steps to prevent them.
Common Data Warehouse Issues
- Poor Query Performance
- Problem: Queries take longer than expected, slowing down business reporting and analytics.
- Solution:
- Analyze execution plans to identify bottlenecks.
- Update statistics to reflect recent data changes.
- Optimize queries by indexing key columns.
- Prevention:
- Schedule regular maintenance windows to perform vacuuming, index rebuilding, and statistics updates.
- Implement query performance monitoring to catch issues early.
- Data Loading Failures
- Problem: Data fails to load properly, leading to missing or incomplete records.
- Solution:
- Implement error-handling mechanisms such as retries or notifications.
- Use staging areas to validate data before inserting into production tables.
- Prevention:
- Conduct data quality checks before ingestion.
- Automate schema validation to ensure consistency during data loading.
Common Data Lake Issues
- Data Swamp
- Problem: Without proper organization, a data lake can degrade into a data swamp, where data becomes unusable and untraceable.
- Solution:
- Implement data cataloging tools to document datasets and their metadata.
- Use data classification frameworks to label data by purpose and sensitivity.
- Prevention:
- Establish strong governance policies for data ingestion and management.
- Enforce access controls to limit who can add or modify datasets.
- Poor Query Performance
- Problem: Queries on raw data are slow due to large file sizes and suboptimal formats.
- Solution:
- Optimize file formats (e.g., Parquet or ORC) for better compression and querying.
- Partition data by key attributes (e.g., date) to speed up query execution.
- Prevention:
- Perform regular performance monitoring to detect query slowdowns.
- Ensure the data lake follows best practices for schema design and partitioning.
Performance Tuning Techniques
Data warehouses and data lakes require specific tuning strategies to ensure optimal performance. Here's a breakdown of key techniques to enhance query speed, resource management, and data organization.
Data Warehouse Performance Tuning
- Query Optimization
- Query Plan Analysis: Examine query execution plans to identify bottlenecks.
- Statistics Maintenance: Regularly update statistics to reflect changes in data distribution.
- Materialized Views: Pre-compute and store frequent query results to accelerate performance.
- Resource Management
- Workload Management: Prioritize workloads based on business needs to prevent resource contention.
- Concurrency Control: Limit the number of concurrent users to avoid overloading resources.
- Resource Allocation: Assign CPU, memory, and I/O resources dynamically to critical queries.
Data Lake Performance Tuning
- Data Organization
- Partitioning Strategy: Split datasets by relevant keys (e.g., date) to speed up filtering and retrieval.
- File Format Optimization: Use formats like Parquet or ORC for better compression and query performance.
- Compaction Jobs: Periodically merge small files into larger ones to reduce query overhead.
- Query Performance
- Caching Layers: Cache frequently accessed data to improve query response times.
- Query Acceleration: Use tools like Presto or Apache Spark to process data in parallel and accelerate queries.
- Data Skipping: Implement strategies to skip irrelevant data files during queries, enhancing performance.
Cost Optimization Strategies
Managing costs effectively is essential for both data warehouses and data lakes. Below are key strategies to optimize costs without sacrificing performance
Data Warehouse Cost Optimization
- Query Optimization
- Materialized Views: Pre-compute frequent queries to reduce redundant computations, improving both speed and cost-efficiency.
- Partitioning Strategies: Partition large tables to reduce query runtime and avoid unnecessary data scans, minimizing compute costs.
- Workload Management
- Query Scheduling: Run non-critical jobs during off-peak hours to take advantage of lower costs in cloud-based systems.
- Concurrency Limits: Control concurrent workloads to prevent overprovisioning of compute resources.
- Storage Optimization
Practical Monthly Cost Calculation Example
Here’s how monthly costs can add up for a 10TB data warehouse:
- Monthly Cost Formula:
Monthly Cost = Storage Cost + Compute Cost + Network Cost - Pricing Details:
- Storage: $40/TB per month
- Compute: $2 per credit
- Network: $0.12 per GB transferred
- Example Calculation:
- Storage: 10TB × $40 = $400
- Compute: 1000 credits × $2 = $2000
- Network: 500GB × $0.12 = $60
Total Monthly Cost = $2,460
This example highlights how quickly costs can accumulate, making it essential to adopt cost optimization strategies.
Data Lake Cost Optimization
- Storage Management
- Lifecycle Policies: Automatically move unused or stale data to cold storage tiers to minimize costs.
- Data Deduplication: Identify and remove duplicate data to avoid unnecessary storage consumption.
- Compute Cost Control
- Spot Instances: Use spot instances (or preemptible instances) for non-critical workloads, reducing compute costs significantly.
- Query Optimization: Use compact file formats and partitioning to lower query processing costs.
- Resource Optimization
- Auto-scaling Clusters: Use auto-scaling policies to dynamically allocate resources based on workloads, avoiding overprovisioning.
- Serverless Query Engines: Leverage Athena or BigQuery for pay-per-query models, eliminating infrastructure costs.
Practical Monthly Cost Calculation Example for a Data Lake
Here’s how monthly costs can accumulate for a 10TB Data Lake:
Monthly Cost Formula:
Monthly Cost=Storage Cost +Compute Cost + Data Transfer Cost
Pricing Details:
- Storage Cost: $20/TB per month (for cold storage)
- Compute Cost: $1.50 per credit (using serverless querying)
- Data Transfer Cost: $0.10 per GB transferred
Example Calculation:
- Storage Cost:
10TB×$20=$200 - Compute Cost:
Assuming 500 credits are used per month:
500 credits×$1.50=$750 - Data Transfer Cost:
Assuming 300GB is transferred per month:
300GB×$0.10=$30
Total Monthly Cost:
Total Monthly Cost=$200+$750+$30=$980
Choosing the Right Solution for Your Business
When deciding between a data warehouse and a data lake, consider the following factors:
- Nature of Data:
- If most of your data is structured and used for reporting, a data warehouse is the better option.
- If you deal with large volumes of raw, diverse data, a data lake is more appropriate.
- Use Case:
- Data warehouses are ideal for business intelligence and operational dashboards.
- Data lakes are suited for data science, AI, and exploratory analytics.
- Budget:
- Data lakes are more cost-effective for storing large datasets.
- Data warehouses can be more expensive but offer better query performance.
- Compliance and Security Needs:
- Data warehouses offer better governance and structured data management.
- Data lakes require additional governance tools to manage data quality and security.
- Query Performance:
- If fast, real-time querying is essential, go with a data warehouse.
- If you prioritize scalable storage over speed, a data lake will be enough.
Which One Fits Your Needs Best?
The choice between a data warehouse and a data lake ultimately depends on your organization’s specific needs, budget, and goals.
- Choose a Data Warehouse if your priority is to get structured insights from business-critical data through reliable and fast querying.
- Choose a Data Lake if you need a scalable, flexible repository for diverse datasets, especially for data science, AI, or IoT projects.
In many cases, organizations find value in integrating both systems, using a data lake for raw data storage and a data warehouse for structured reporting. With the right architecture, you can leverage the best of both worlds to enhance your analytics capabilities.
FAQs
Q: What's the typical data ingestion latency for a data warehouse vs. data lake?
A: Data warehouses typically have 10-30 minute latency, while data lakes can range from real-time to hours depending on the implementation.
Q: How do you handle late-arriving data in a data warehouse?
A: Use slowly changing dimensions (SCD) and implement merge operations for historical updates.
Q: How do you manage access control for temporary tables?
A: Apply the same security policies as permanent tables and implement automatic cleanup procedures.
Q: How do you handle data quality issues during ingestion?
A: Implement validation rules and create quarantine areas for rejected records.
Q: What's the recommended approach for handling small files in a data lake?
A: Implement file compaction jobs to merge small files into larger ones (target >100MB).






