
A healthcare company deploys an internal AI assistant on Kubernetes. Clinicians use it to review patient histories, summarize lab results, and draft referral letters. The platform team has done the right things: TLS everywhere, RBAC policies locked down, Kubernetes Secrets managed through a vault, network policies isolating namespaces, and image scanning on every container before deployment.
On paper, the platform looks secure.
But here is what happens during an inference request. A clinician types a question about a patient. That prompt, containing a real patient name and medical history, travels from the browser to the model-serving pod. Inside that pod, vLLM processes the prompt, retrieves relevant documents from a vector database, and generates a response. For a few hundred milliseconds, the patient's data exists in clear memory inside the model-serving process, inside the KV cache, and potentially inside logs, traces, temporary buffers, or observability paths if those systems are not carefully controlled.
The data was encrypted at rest in the object store. It was encrypted in transit over TLS. But while the model was actively processing it, the data was plain text in memory inside a shared Kubernetes cluster.
That is the gap. Traditional security protects data in two states. AI workloads introduce a third. Protecting the moment when sensitive data is being actively processed, what the industry calls data in use, is the core challenge of confidential AI on Kubernetes.
This article explains what that challenge looks like in production, why Kubernetes makes it harder, and how engineering teams are building inference architectures that account for this third state of data.
Why AI Workloads Change the Security Model
Standard web applications process predictable, structured requests. A user submits a form, the application validates input, queries a database, and returns a response. The sensitive data is well-defined and relatively easy to isolate.
LLM workloads are different in several ways that matter for security.
The prompt itself is the input. When a user submits a question to an enterprise AI assistant, the entire question, including any confidential context, becomes the input to the model. The OWASP LLM Top 10 for 2025 elevated sensitive information disclosure to the number two position, reflecting how broadly the security community views information leakage as a critical production risk.
RAG systems pull private documents into the processing pipeline. When an AI assistant retrieves documents from an internal knowledge base, those documents get concatenated into the prompt context before reaching the model. In multi-tenant environments where multiple applications share the same vector database, there is a risk of context leakage between users or queries.
Vector embeddings introduce a separate leakage risk. Research has shown that embeddings can sometimes leak information or be inverted under certain conditions, meaning numerical vectors should not be treated as safely anonymized versions of the original text.
AI agents call tools and external APIs. An agent that reads from a ticketing system, queries a database, and writes to a document store moves sensitive data across multiple services during a single inference chain. Each hop is another place where data exists in an unprotected state.
Model weights themselves may be proprietary. Organizations that fine-tune foundational models on internal data have intellectual property embedded in those weights. A model file is not just a large binary; it may encode training data patterns, internal terminology, and domain-specific knowledge.
The security model for AI systems needs to account for the full lifecycle of a request, not just its storage and transport.
The Runtime Gap: At Rest, In Transit, and In Use
Most engineering teams are familiar with two states of data that need protection.
Data at rest covers files, databases, object storage, and persistent volumes. Encryption at rest means that if someone gains unauthorized access to the physical storage, the data is unreadable without the encryption key.
Data in transit covers data moving over networks. TLS or mTLS is commonly used to protect traffic between clients and services, but Kubernetes does not automatically encrypt every pod-to-pod connection unless the platform, application, service mesh, or CNI layer is configured to do so.
Data in use is the third state, and it is the one that AI workloads expose in new ways. When a CPU or GPU processes data, that data must be in unencrypted form in memory. Traditional security tools have no visibility into what is happeninginsidea running process's memory.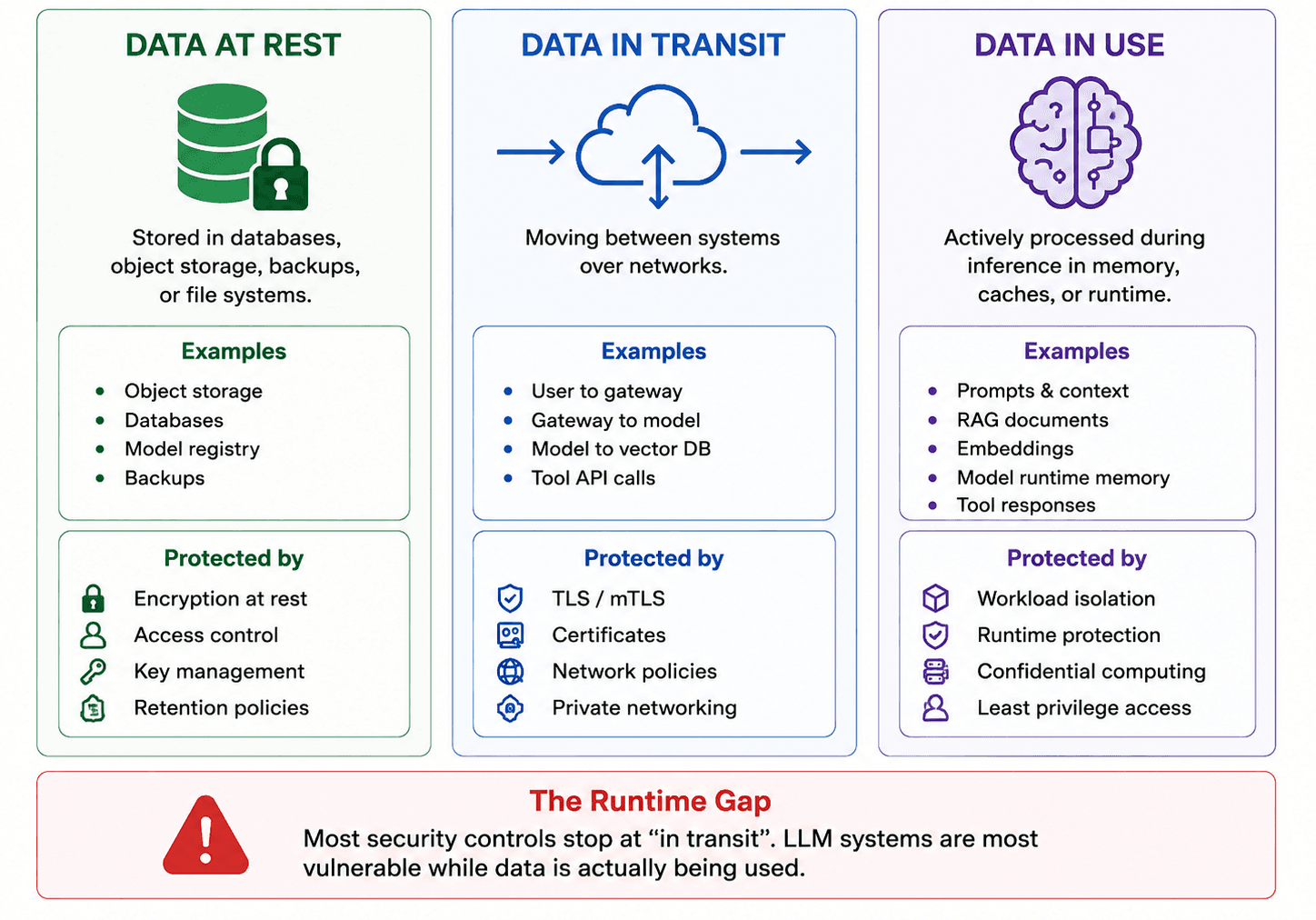
Diagram showing data at rest, data in transit, and data in use during LLM inference on Kubernetes
A practical example makes this concrete. A legal firm stores client contracts in encrypted object storage. When a contract is uploaded for AI-powered analysis, it gets encrypted at rest immediately. When the document travels from object storage to the model-serving pod, it is encrypted in transit over TLS. But inside the vLLM pod, when the model is summarizing clauses from that contract, the full document text exists in process memory. Depending on the node and pod configuration, host-level access, privileged containers, debug tooling, unsafe sidecars, or shared runtime paths can create ways for sensitive runtime data to be exposed.
Traditional security controls protect data at rest and in transit but fail to secure data and AI in use, leaving model weights, prompts, and inference workloads vulnerable to privileged access and infrastructure risks. Confidential AI is the practice of addressing this third state.
What Confidential AI Means in Simple Terms
Confidential AI refers to running AI workloads inside protected execution environments where sensitive data is harder to access from outside the workload while it is being processed.
The technology enabling this is called confidential computing, and it relies on hardware features built into modern CPUs and GPUs to create isolated, encrypted memory regions.
A Trusted Execution Environment (TEE) is a hardware-protected area of a processor designed to keep code and data isolated from the host operating system, hypervisor, and surrounding infrastructure while the workload is running. Intel Trust Domain Extensions (TDX) and AMD Secure Encrypted Virtualization-Secure Nested Paging (SEV-SNP) are the two primary CPU-based implementations in production today.
This does not remove every risk. Vulnerabilities inside the workload, unsafe logging, side channels, misconfigured key release, and denial-of-service risks still need separate controls.
NVIDIA extended this concept to supported GPUs. On platforms such as NVIDIA H100, GPU confidential computing can protect CPU-to-GPU communication paths and isolate GPU memory during accelerated inference. This helps reduce exposure of prompts, inference inputs, and model data while they are being processed on supported hardware.
Remote attestation is the mechanism that makes this verifiable. Before a workload sends sensitive data into a TEE, it can request a cryptographic proof, called an attestation report, from the hardware itself. This report confirms that the TEE is genuine, that the expected software is running, and that the environment has not been tampered with.
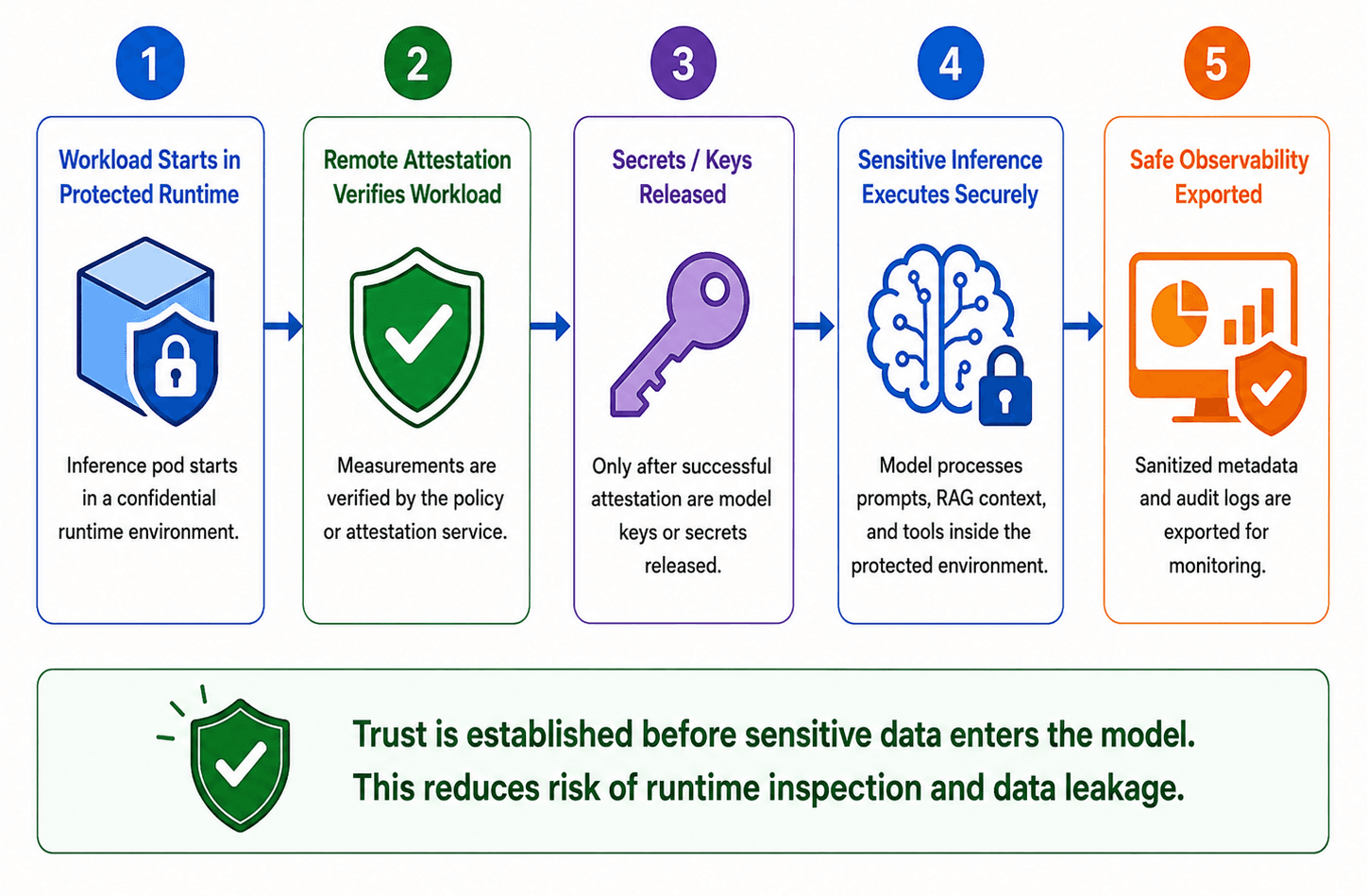 Confidential computing flow for LLM inference with TEE, attestation, and protected runtime processing
Confidential computing flow for LLM inference with TEE, attestation, and protected runtime processing
In Kubernetes, Confidential Containers helps teams run selected workloads with stronger runtime isolation. It is commonly used with Kata Containers and Kubernetes RuntimeClasses, so sensitive pods can run inside a more isolated environment while still being deployed with normal Kubernetes manifests. For LLM inference, this can be connected with attestation and key release, so model weights or secrets are decrypted only after the runtime environment is verified.
Teams evaluating this approach should verify current hardware availability in their target cloud environment before designing production architectures around specific TEE implementations, as availability varies by provider and region. |
Why Kubernetes Makes AI Runtime Security Harder
Kubernetes is an excellent platform for AI workloads, but its operating model introduces specific runtime security challenges.
Shared worker nodes are the most significant issue. By default, Kubernetes schedules multiple pods from multiple teams onto the same physical nodes. A model-serving pod processing sensitive patient data may share a node with a developer's experiment pod, a logging aggregator, and a background analytics job. These workloads share the same kernel and hardware resources.
Sidecars and agents present a specific concern for AI workloads. Service mesh sidecars, observability agents, and security scanners often run alongside the model-serving container in the same pod. Depending on how they are configured, sidecars and agents may handle traffic, collect metadata, mount shared volumes, or export traces. If they are over-privileged or misconfigured, they can become an unintended path for sensitive runtime data to leave the inference boundary.
Logs and traces carry a specific AI risk. Standard observability practice involves logging request bodies and response payloads for debugging. In an AI system, this means prompt text, retrieved document fragments, and model outputs can end up in log storage with much weaker access controls than the model-serving pod itself.
KV cache sharing is a newer risk specific to LLM infrastructure. Research presented at NDSS 2025 demonstrated prompt leakage risks from KV-cache sharing in multi-tenant LLM serving. When multiple users share the same serving infrastructure without proper isolation, cache behavior can create side-channel risks that expose sensitive prompt information.
Temporary files and debug artifacts accumulate in ways that are easy to overlook. Model-serving frameworks often write partial outputs, cache dumps, and checkpoint files to ephemeral storage during normal operation. If that storage is not explicitly cleared, sensitive data persists beyond the inference request.
Kubernetes provides strong controls, but many moving parts such as sidecars, shared nodes, observability pipelines, persistent volumes, service accounts, and runtime classes increase the surface area that must be accounted for in an AI security architecture.
What Must Be Protected in LLM Inference
A practical audit of an LLM inference pipeline surfaces more sensitive data than most teams initially expect.
- User prompts The raw text input from users often contains the most sensitive information in the system: patient symptoms, legal questions, financial situations, source code from internal repositories. Prompts should be treated as sensitive data from the moment they enter the cluster.
- Retrieved RAG documents Documents pulled from internal knowledge bases carry the same sensitivity as their source systems. A RAG retrieval that pulls a customer contract fragment into a prompt context should be treated with the same controls as direct access to that contract.
- Vector embeddings are not safely anonymized. The numerical representations can be inverted to reconstruct original content, making unprotected embedding storage a real leakage risk. OWASP added Vector and Embedding Weaknesses as a Top 10 LLM issue for 2025.
- Vector database queries The query sent to a vector database during RAG lookup reveals the topic and often the specific content of the prompt. Access to vector database query logs is effectively access to inference behavior.
- Model weights and LoRA adapters Model artifacts, especially fine-tuned weights trained on proprietary data, represent significant intellectual property. Unauthorized access can expose training data patterns and enable model theft.
- Tool credentials AI agents that call external tools require credentials for those systems. These must not be embedded in prompts, logged in traces, or accessible to other workloads.
- AI agent memory Stateful agent frameworks maintain conversation history, scratchpad notes, and retrieved context across multiple inference steps. This accumulated context can represent a full record of sensitive operations.
- Response logs and audit trails Model outputs may reproduce sensitive information from retrieved documents or training data. Storing full response logs without access controls creates secondary exposure.
- Temporary files and caches Model-serving frameworks write intermediate state to disk during inference. These must be handled with the same controls as the primary data.
Secure LLM Inference Architecture on Kubernetes
A production-grade secure inference deployment on Kubernetes incorporates security controls at multiple layers rather than relying on any single mechanism.
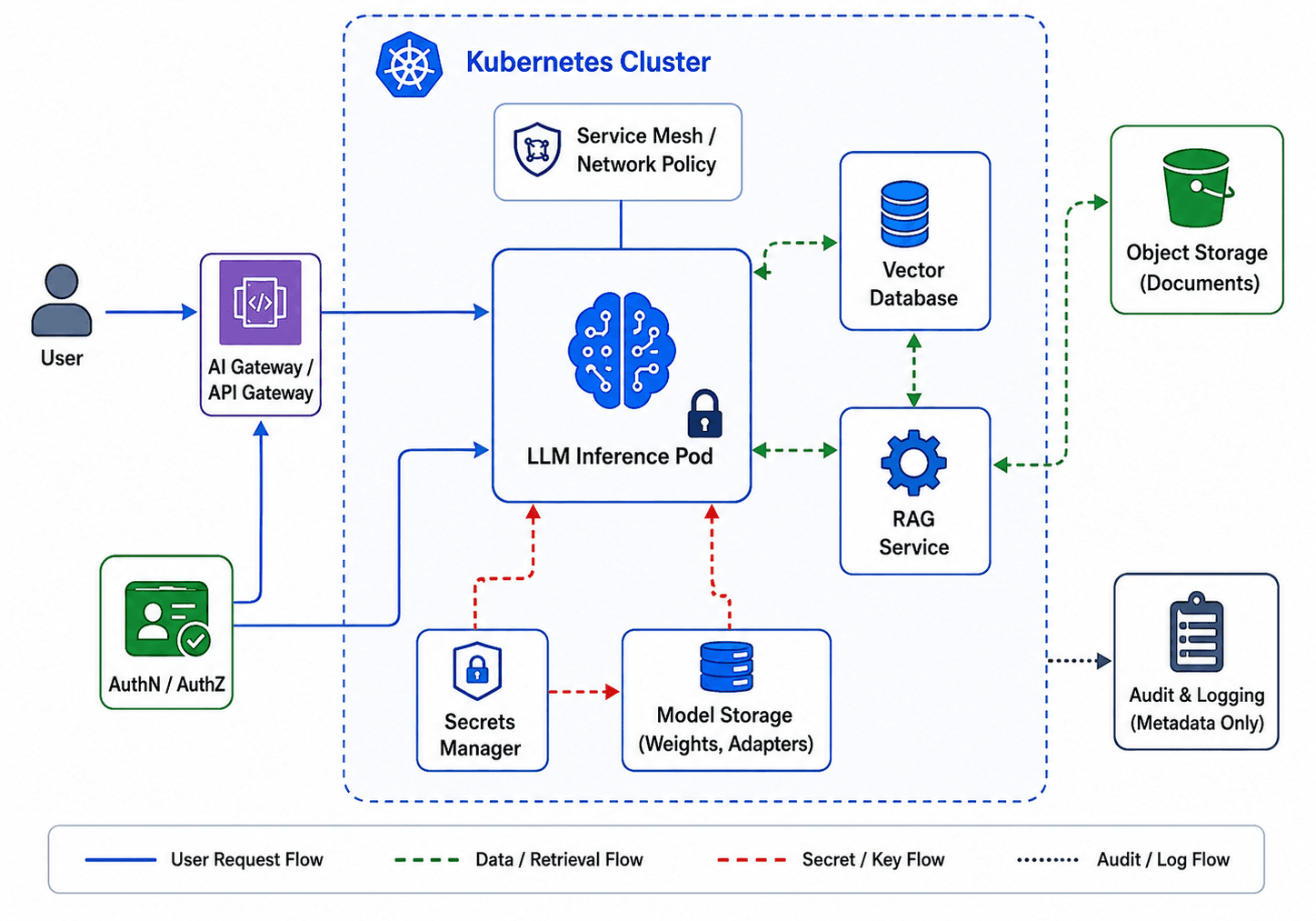 Secure LLM inference architecture on Kubernetes with API gateway, RAG, vector database, model storage, secrets manager, and audit logging
Secure LLM inference architecture on Kubernetes with API gateway, RAG, vector database, model storage, secrets manager, and audit logging
The request path follows this structure:
User request enters the cluster through an API gateway that enforces authentication and authorization. The gateway validates the user's identity, checks rate limits, and applies prompt filtering before the request proceeds further.
The authentication layer validates the service account and request scope. Workload identity, such as IRSA or EKS Pod Identity on EKS, Workload Identity on GKE, and Microsoft Entra Workload ID on AKS, ensures the model-serving pod has precisely scoped cloud permissions, not broad cluster-admin credentials.
Model-serving pod runs in an isolated namespace with a dedicated service account. The pod accesses model weights from encrypted storage and retrieves them only after attestation confirms the environment is trusted. For the most sensitive workloads, the pod runs inside a confidential container using Intel TDX or AMD SEV-SNP via Kata Containers.
Vector database access is restricted through a service account that limits access to the authorized data scopes for that application. The vector database runs in a separate namespace with its own network policies.
Secrets manager provides tool credentials and API keys at runtime. These credentials should not be baked into container images, committed to config files, or left as long-lived static values in pod specs.
Attestation layer (for confidential workloads) releases decryption keys only after verifying the attestation report confirms the expected TEE environment. No attestation, no key release.
Audit logging should capture inference request metadata, credential access, model version, and important security events. Raw prompts are not logged. Only metadata such as request ID, user identity, timestamp, model version, and token count is stored. The observability pipeline is kept explicitly separate from the prompt data path.
Kubernetes Controls That Still Matter
Confidential AI does not replace standard Kubernetes security. It adds a layer on top. Without the fundamentals, the additional isolation provides limited benefit.
RBAC should be scoped to the minimum permission required for each service account. Model-serving pods should not have cluster-wide read or write permissions.
NetworkPolicy should explicitly define which pods can communicate with which services. The model-serving pod should have outbound access only to the vector database, secrets manager, and model artifact storage.
Namespace isolation separates sensitive AI workloads from general cluster workloads. Dedicated namespaces for inference, vector storage, and model artifact management make policy enforcement cleaner.
Admission policies via Kyverno or OPA/Gatekeeper can enforce security standards at deployment time: requiring specific runtime classes for sensitive workloads, blocking privileged containers, and mandating resource limits.
Image scanning catches vulnerabilities in model-serving container images before they reach production. Supply chain attacks via compromised container images are a real and growing risk.
Kubernetes API audit logging can capture resource access, secret access attempts, and configuration changes, depending on the configured audit policy.
The security posture of a confidential AI workload is only as strong as the Kubernetes foundations underneath it.
Where Confidential Computing Fits
Confidential computing is valuable in specific scenarios rather than universally applicable.
The clearest use case is protecting sensitive inference workloads on shared infrastructure. When an organization runs AI workloads on cloud infrastructure they do not fully control, hardware-based memory encryption provides a meaningful additional guarantee. Customers can use attestation to verify that prompts are processed inside an approved protected environment before sending sensitive data. Model providers can reduce the risk of exposing weights to the platform running the workload.
Protecting proprietary model weights is another concrete application. When a fine-tuned model represents significant investment and contains patterns derived from confidential training data, running it inside a TEE helps ensure the weights are decrypted only within a protected runtime environment and reduces exposure to host-level access.
Regulated industries such as healthcare and finance often need strong evidence that sensitive data is handled with appropriate controls. Cryptographic attestation can support that evidence by proving that a workload ran in a verified protected environment. But it should be treated as one part of a broader compliance program, not a complete compliance solution by itself.
On Kubernetes specifically, the Confidential Containers project enables this through RuntimeClasses. When Kata Containers are installed, RuntimeClasses can be configured for Intel TDX, AMD SEV-SNP, or other supported confidential computing backends, depending on the platform and hardware. Workloads can request confidential isolation simply by specifying the appropriate runtime class in the pod specification.
Production Trade-offs
Confidential computing is not free. Engineering teams evaluating it for production workloads should understand the real costs.
Performance overhead is measurable, but it depends on the model, serving framework, batch size, hardware, and traffic pattern. Some benchmarks show modest overhead for confidential LLM inference, while GPU confidential-computing overhead can vary by workload. Teams should test their own model and deployment pattern before assuming the same numbers in production.
Hardware availability is a genuine constraint. Not every cloud region offers instances with Intel TDX or AMD SEV-SNP support. NVIDIA H100 Confidential Compute requires specific hardware configurations that may not be immediately available in preferred regions.
Debugging is harder inside a TEE. The isolation that protects data also makes it more difficult to attach debuggers, inspect memory, or use standard profiling tools. Troubleshooting performance issues inside a confidential container requires different tooling and more planning.
Observability is limited by design. The normal practice of collecting detailed traces, logging request bodies, and capturing metrics can conflict with the confidentiality goals. Engineering teams need to design observability pipelines that collect sufficient operational telemetry without capturing sensitive content.
The operational learning curve is real. Attestation infrastructure, key management integration, and confidential runtime management are specialized skills that most Kubernetes teams are building for the first time.
Confidential AI is worth evaluating for sensitive, regulated, or high-value AI workloads. It is not the right choice for every AI deployment.
When Confidential AI Is Worth the Investment
The following workload types justify the operational investment:
- Healthcare AI systems processing patient data are strong candidates. Inference pipelines that handle PHI, clinical notes, or diagnostic results can benefit from additional runtime protection and attestation evidence as part of a broader compliance program.
- Financial services AI processing transaction data, credit assessments, or trading information operates under strict regulatory requirements. Confidential inference environments can support stronger data-protection controls without forcing every AI workflow to rely only on sanitized data.
- Legal document analysis involving attorney-client privileged material, contracts under NDA, or litigation strategy represents information where teams may want stronger protection from infrastructure-level access.
- Internal code assistants with access to proprietary codebases expose intellectual property at runtime. Model weights fine-tuned on internal code repositories contain embedded knowledge that warrants protection.
- Enterprise copilots connected to internal systems ticketing, CRM, HR records, financial systems process a continuous stream of confidential business data.
- Proprietary model hosting for organizations running custom models for external clients who need cryptographic evidence that model weights are decrypted only inside approved protected environments.
When Standard Kubernetes Security May Be Enough
Confidential AI is not necessary for every LLM deployment. Standard Kubernetes security controls are sufficient when:
- Public-facing FAQ bots answer questions about publicly available information prompts and responses contain no private data requiring hardware-level protection.
- Non-sensitive summarization tools process internal non-confidential documentation such as public engineering content or publicly available reference material.
- Low-risk internal experiments evaluate model capabilities on synthetic or publicly available data and serve no regulated workloads.
- Simple prototypes and demos use no production data and serve no regulated workloads.
The decision framework is straightforward: classify the sensitivity of the data flowing through the inference pipeline, then match the security controls to that classification.
Secure AI Inference Checklist for Kubernetes
| Category | Check |
|---|---|
| Data classification | Classify AI workload sensitivity before deployment not all LLM workloads require the same controls |
| Prompt handling | Avoid logging raw prompts and full model responses log metadata only (request ID, user identity, timestamp, token count) |
| RAG security | Restrict vector database access to authorized service accounts only not open to all cluster pods |
| Embedding protection | Treat vector storage as sensitive apply access controls matching the source data classification |
| Namespace isolation | Run model-serving pods in dedicated namespaces separate from general workloads |
| Workload identity | Use workload identity (IRSA, Pod Identity) avoid static long-lived credentials in pod specs |
| Credential management | Rotate tool credentials and inject them via secrets manager at runtime not baked into images |
| Model artifact access | Encrypt model weights at rest; restrict storage access to model-serving service accounts only |
| Audit trail | Log request metadata not prompt content. Every inference access must be auditable |
| RBAC | Apply least-privilege RBAC to every service account in the inference pipeline |
| Network policies | Explicitly restrict model pod outbound connections to required services only |
| Observability pipeline | Review all tracing and logging pipelines for unintentional prompt content capture |
| Confidential runtime | Evaluate Kata Containers with Intel TDX or AMD SEV-SNP for regulated workloads |
| Attestation | Verify hardware attestation before releasing decryption keys for sensitive inference workloads |
| Temporary files | Configure model-serving pods to clear ephemeral storage between requests |
| KV cache isolation | Disable KV cache sharing in multi-tenant serving configurations to prevent cross-user context leakage |
| Admission policies | Enforce security requirements at deployment time via Kyverno or OPA not just at runtime |
Common Mistakes Teams Make
Logging full prompts in the name of debugging. Observability is important, but a log level change during incident response can accidentally write sensitive prompt content to a log aggregator with broader access than the model-serving pod. Define explicit log redaction rules before going to production.
Treating vector databases like regular caches. Vector databases store data that can be reconstructed into the original sensitive text. Many teams deploy vector databases without the access controls they would apply to the source documents.
Giving AI agents broad credentials. An agent that needs to read from a ticketing system and write to a project tracker does not need organization-wide admin credentials. Each tool integration should have the minimum permission required for that specific operation.
Assuming TLS is sufficient. TLS protects data in transit. It does not protect data while the model processes it, does not stop unsafe logging, and does not protect prompts or model weights from host-level or runtime-level exposure if the environment is misconfigured.
Running sensitive inference on shared nodes without isolation. Scheduling model-serving pods for regulated workloads on general-purpose node pools that also run developer experiments and internal tools expands the attack surface unnecessarily.
Forgetting temporary files and debug dumps. Model-serving frameworks may write checkpoint files, profiling artifacts, cache dumps, or temporary outputs to ephemeral storage. These artifacts should be reviewed and cleaned according to the serving framework, storage configuration, and pod lifecycle.
Exposing vector databases on internal cluster networks without authentication. Some vector database deployments are left open to broad cluster-internal access. In a multi-tenant cluster, weak network policy or authentication can allow unrelated workloads to query the same vector store used for sensitive document retrieval.
Sending sensitive prompts to unapproved external model providers. In organizations where employees have direct access to external AI APIs, there is a real risk that sensitive data ends up being processed outside the organization's security perimeter without visibility or consent.
Frequently Asked Questions (FAQs)
1. Is Kubernetes secure enough for LLM inference workloads?
Kubernetes can be secure for LLM inference, but only when the platform is configured with strong controls such as RBAC, network policies, workload identity, secrets management, image scanning, and audit logging.
For sensitive AI workloads, standard Kubernetes security may not be enough by itself because prompts, retrieved documents, embeddings, and model outputs are processed in memory during inference. This is where confidential AI and runtime isolation become important.
2. Why do LLM prompts need special protection?
LLM prompts often contain sensitive business, legal, healthcare, financial, or personal information. Unlike a normal API request, the prompt may include full context, private documents, source code, customer details, or internal instructions.
Because the model processes this text directly, prompts should be protected across the full inference path, from the user request to the model-serving pod, RAG pipeline, logs, traces, and temporary runtime storage.
3. What is the biggest security risk in AI inference on Kubernetes?
One of the biggest risks is sensitive data exposure during runtime. Data may be encrypted at rest and protected in transit, but it still becomes readable inside memory while the model is processing it.
Other common risks include prompt logging, overly broad service account permissions, weak vector database access controls, exposed model weights, insecure tool credentials, and shared node environments without proper workload isolation.
4. Can RAG systems leak confidential data?
Yes, RAG systems can leak confidential data if document retrieval, vector database access, prompt construction, or logging is not properly controlled.
A RAG pipeline may pull private documents into the model context. If access controls are weak, the wrong user or workload may retrieve information they should not see. This makes RAG security a critical part of secure LLM inference on Kubernetes.
5. Should vector databases be treated as sensitive systems?
Yes. Vector databases should be treated as sensitive systems because embeddings can still reveal information about the original data they represent.
Teams should apply access controls, namespace isolation, encryption, audit logging, and service-account-level permissions to vector databases. They should not be treated as simple caches or low-risk internal stores.

