
1. Strategic QoS Classes: Controlling the Blast Radius During Node Pressure
The transition from diagnostic profiling to architectural prevention requires understanding how the Linux kernel and the Kubernetes Kubelet negotiate resource scarcity. At enterprise scale, localized memory exhaustion is inevitable. The objective is not to eliminate memory pressure entirely, but to rigorously control the blast radius. The primary mechanism for this is the deterministic application of Quality of Service (QoS) classes and their direct influence on the oom_score_adj parameter.
The Calculus of Node Pressure
Kubernetes assigns every scheduled Pod to one of three QoS classes: Guaranteed, Burstable, and BestEffort. This class dictates the oom_score_adj value passed to the container's processes, which the Linux kernel uses to modify the final Out-Of-Memory (OOM) score.
When a node experiences sudden memory exhaustion bypassing the Kubelet's graceful eviction polling intervals it relies entirely on the kernel's OOM killer. The kernel calculates a baseline oom_score based on the percentage of total node memory a process consumes, then adds the oom_score_adj. The highest score is terminated with a SIGKILL.
The Kubelet assigns oom_score_adj using strict rules based on QoS class :
| QoS Class | Resource Criteria | oom_score_adj Value | Eviction Priority |
| Guaranteed | Requests equal Limits for both CPU and Memory across all containers. | -997 | Evicted last. |
| BestEffort | No CPU or Memory Requests or Limits defined for any container. | 1000 | Evicted first. |
| Burstable | Pod has at least one Request defined, but does not meet Guaranteed criteria. | Calculated dynamically. | Evicted second (if exceeding request) or last (if below). |
A Guaranteed pod (-997) is effectively immunized from the kernel OOM killer, while BestEffort pods (1000) act as the immediate sacrificial layer. The operational complexity, however, resides within the Burstable class.
The Burstable Formula and the "Low Request" Penalty
For Burstable pods, the Kubelet calculates the oom_score_adj using a highly specific, inverse-proportional formula :
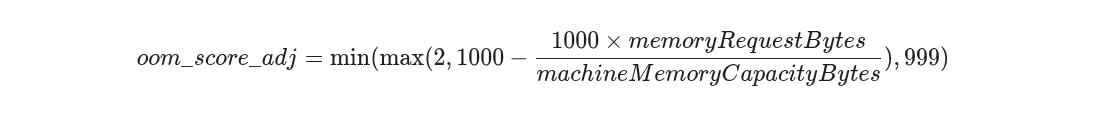
The architectural implication here is frequently misunderstood: the smaller the memory request relative to the node's total capacity, the higher the oom_score_adj assigned to the container.
Consider a 128GB worker node hosting two Burstable pods:
- Pod A (Microservice): Requests 1GB. Formula evaluates to: $1000 - (1000 \times 1 / 128) = 992$.
- Pod B (Database): Requests 60GB. Formula evaluates to: $1000 - (1000 \times 60 / 128) = 531$.
Despite Pod B consuming vastly more memory, Pod A is heavily penalized simply for having a conservative request relative to the machine size. PriorityClass annotations (like system-cluster-critical) are entirely ignored by the kernel OOM killer within this class. A critical daemonset pod with a small memory request will be relentlessly OOM-killed before a low-priority batch worker that requested a massive chunk of memory.
Key Takeaway: Small memory requests on large nodes can make a Burstable pod significantly more vulnerable to kernel-level OOM termination than larger, higher-consuming workloads during sudden node-level memory exhaustion.
Strategic Implications for Multi-Tenant Clusters
Relying on decentralized developer teams to configure arbitrary resource requests guarantees non-deterministic failure domains. Platform architecture mandates the enforcement of rigid QoS policies to establish a predictable blast radius:
- Enforce Guaranteed QoS: Critical data path components (Ingress controllers, service mesh sidecars) must be programmatically forced into the Guaranteed class.
- Embrace BestEffort Sacrifices: Background asynchronous tasks should be deliberately configured without memory requests, acting as shock absorbers.
- Align Node Sizing: Because the Burstable calculation divides by machine capacity, the same pod specification yields different vulnerabilities depending on the instance type. Segregate workload types into specialized node pools to prevent massive monolithic applications from artificially depressing their own scores at the expense of surrounding microservices.
2. Vertical Pod Autoscaler (VPA): Dynamic Memory Scaling and Startup Spikes
While QoS classes control the failure state, accurate resource allocation is the primary mechanism for preventing memory exhaustion. Static allocation is incompatible with highly variable enterprise traffic, making the Kubernetes Vertical Pod Autoscaler (VPA) essential for dynamically adjusting CPU and memory requests. However, improper VPA implementation is a leading cause of platform instability due to component conflicts and language runtime behaviors.
The Architectural Conflict Between HPA and VPA
Kubernetes autoscaling relies on independent controllers. The Horizontal Pod Autoscaler (HPA) adds or removes pod replicas based on metric thresholds, changing topology. The VPA resizes pods, changing geometry. When both govern the same dimension (memory), they inherently conflict and produce aggressive feedback loops. If a sudden memory spike occurs, HPA scales out replicas. Simultaneously, VPA observes elevated usage and increases the deployment's requests. This combined action rapidly exhausts cluster capacity. Once the spike subsides, HPA scales down, but VPA's historical percentile buffer remains elevated, leaving the cluster permanently over-provisioned. To prevent this "death spiral," architectural standards dictate that HPA and VPA should not control the same resource dimension simultaneously.
VPA Thrashing and JVM Startup Spikes
VPA poses severe operational hazards for applications running on heavy virtual machines, most notably the Java Virtual Machine (JVM). During initialization, the JVM's Just-In-Time (JIT) compilation generates massive, transient spikes in CPU and native memory allocation. If VPA manages a JVM workload, the Recommender records this initialization spike as the baseline required capacity. The Updater then evicts the pod to apply the inflated requests. When the resized pod starts, JVM configurations that derive heap sizing from container limits may expand heap allocations after VPA-driven resizing, amplifying this startup spike. VPA observes this and evicts the pod again, resulting in a continuous loop of restarts known as VPA thrashing.
Stabilizing VPA: RequestsOnly
To stabilize VPA for memory-managed runtimes, decouple request optimization from limit enforcement using the controlledValues parameter. By default, VPA operates in RequestsAndLimits mode, meaning it dynamically adjusts requests and blindly escalates limits to maintain the original request-to-limit ratio. For Java or Go applications sizing internal memory based on cgroup visibility, proportional escalation is catastrophic, as the runtime consumes the expanding limit until the node OOMs.
The mandatory configuration for these runtimes is controlledValues: RequestsOnly. This mode allows VPA to right-size requests based on actual long-term usage improving request accuracy while leaving memory limits rigidly pinned by platform engineers.
Seamless Vertical Scaling: In-Place Pod Resizing
Historically, VPA required evicting pods to apply new requests, causing unacceptable latency. The stabilization of Kubernetes In-Place Pod Resizing (GA in v1.35) fundamentally alters this. It allows the Kubelet to dynamically alter a container's cgroup boundaries without restarting the process, provided the node has capacity.
VPA 1.4+ introduced the InPlaceOrRecreate mode. When configured, the VPA Updater leverages the /resize subresource to patch the running pod directly. Setting the resizePolicy to NotRequired ensures the cgroup updates while the process continues uninterrupted. However, while Kubernetes expands the memory cgroup in-place, traditional JVMs do not automatically consume it since maximum heap size (-Xmx) is locked at initial calculation. Thus, in-place memory resizing yields maximum value for Node.js, dynamically managed Golang applications, or workloads relying on off-heap native caches.
3. Dynamic Node Provisioning: Balancing Bin-Packing with Necessary Node-Level Overhead
Optimizing pod-level requests via VPA must pair with highly efficient node-level scheduling. The industry is shifting from static Auto Scaling Groups (ASGs) to dynamic provisioners like Karpenter. Karpenter bypasses ASGs entirely, observing pending pod requests and provisioning exactly sized instances in real-time.
While aggressive bin-packing reduces cloud spend, the margin for error in node-level memory overhead calculations shrinks to zero. Miscalculated overhead triggers node memory starvation, causing kernel OOMs or unreachability before applications reach defined limits.
The Capacity Calculus: Reserved Resources vs. Allocatable Space
To prevent instability, engineers must understand how the Kubelet divides physical memory into strict partitions. The sum of resources that pods can actually request is not the physical capacity of the machine, but the Allocatable capacity.
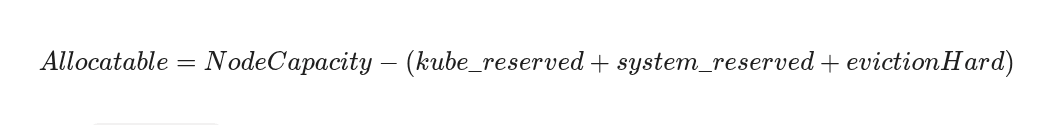
- kube-reserved: Captures resource reservations for Kubernetes system daemons critical to cluster operations, such as the kubelet process and container runtime. It scales linearly with pod density.
- system-reserved: This allocation captures resources required for all remaining OS-level host components. This includes foundational daemons such as sshd, systemd, NetworkManager, and monitoring agents.
- evictionHard: This is the non-negotiable floor of memory that the Kubelet refuses to let pods consume. Configured via Kubelet launch flags such as --eviction-hard=memory.available<500Mi, this establishes a defensive buffer. If available memory drops below this specific threshold, the Kubelet places the node into a NodePressure state, halting new pod scheduling and initiating the rapid eviction of BestEffort and over-request Burstable pods until the buffer is restored.
Consider a 32GiB node. If kube-reserved is configured to 1GiB, system-reserved to 1.5GiB, and the evictionHard threshold is set to 500MiB, the maximum total memory requests the Kubernetes scheduler will allow on that node is 29GiB. If platform engineers fail to enforce kube-reserved and system-reserved, the scheduler defaults to assuming all 31.5GiB is safely available for pod placement. When system daemons consume their required 2.5GiB alongside pods utilizing 31.5GiB, total usage exceeds physical capacity. This plunges the node into a catastrophic OOM failure state, rendering the Kubelet unresponsive before graceful evictions can occur.
Karpenter Consolidation and the Overhead Percentile Trap
Unlike static node groups where operators manually hardcode reservations, Karpenter abstracts node creation and calculates these programmatically. Karpenter injects nodes based on the precise sum of pending pod requests plus its own computed overhead.
By default, Karpenter calculates this overhead using the vm-memory-overhead-percent setting, which defaults to 0.075 (7.5%). This parameter subtracts a flat percentage from the physical memory of an instance type to account for hypervisor and OS overhead before Karpenter evaluates the node for pod scheduling.
While a flat percentage simplifies initial deployments, it becomes a severe architectural anti-pattern at the extremes of instance sizing:
- Massive Instances: For a heavily memory-optimized 256GiB instance, a 7.5% overhead reserves an astonishing 19.2GiB of memory strictly for the OS. This massive over-allocation results in wasted cloud spend, as standard Linux system daemons do not require 19GB.
- Small Instances: Conversely, on a small 4GiB instance, 7.5% only reserves 300MiB. This is critically insufficient to safely run modern container runtimes alongside the OS networking stack, leading to rapid pod evictions or node lockups shortly after launch.
| Karpenter Setting | Default Value | Architectural Implication |
| vm-memory-overhead-percent | 0.075 (7.5%) | Subtracted from total memory. Requires override for heterogeneous environments. |
| reserved-enis | 0 | Excludes reserved ENIs from kube-reserved calculations. Critical for VPC CNI setups. |
| systemReserved / kubeReserved | Computed via AMI | If overriding defaults in Karpenter NodeClass, exact alignment with Kubelet arguments is mandatory. |
Architects must tune Karpenter provisioners based on workload topologies. When utilizing Karpenter's consolidation feature which continuously evaluates the cluster to evict pods and repack them onto fewer, cheaper nodes the precision of these reservations is paramount. If memory limits are not rigidly enforced on compressible workloads, and Karpenter aggressively packs the node to exactly 100% of its allocatable space, any minor spike in memory pressure across those pods immediately triggers the evictionHard threshold, causing the disruption the provisioner was meant to avoid.
4. Architectural Refactoring: Flattening the Application Memory Curve
While VPA and Karpenter optimize infrastructure around memory consumption, this section focuses on reducing memory demand at the application layer itself. Loading entire files, multi-gigabyte database payloads, or massive JSON arrays into memory simultaneously results in an O(n) memory curve, where the footprint scales linearly and aggressively with input size. As inputs naturally grow over the lifecycle of a product, the application eventually and inevitably breaches its cgroup limits. The architectural solution is transitioning from stateful, heavy batch paradigms to streaming and chunking architectures.
Escaping the Batch Processing Trap: Chunking Architectures
Chunking architectures ensure that data is divided into manageable blocks, maintaining a constant O(1) or strictly bounded memory footprint regardless of the total payload size. This is no longer just a requirement for video streaming; it is mandatory for data processing and Generative AI contexts.
- Fixed-size chunking: The most straightforward approach, ideal for file storage systems, byte-stream processing, and basic ETL pipelines where data is read in specific byte intervals (e.g., 4KB or 1MB blocks).
- Logical and Content-based chunking: Vital for intelligent parsing, where data is split based on logical boundaries rather than arbitrary sizes. In systems like GenAI Retrieval-Augmented Generation (RAG), page-level chunking or form-based specialized extraction pipelines allow the system to maintain semantic context without loading massive document trees into active memory.
- AI-Driven Dynamic Chunking: Advanced architectures leverage specialized neural models to detect natural breakpoints and adjust chunk sizes dynamically based on query patterns, balancing semantic coherence with strict memory constraints.
While fixed-size chunking is highly memory efficient, testing demonstrates that extreme chunk sizes yield diminishing returns in data processing systems; extreme minimums (e.g., 128 tokens) and massive maximums (e.g., 2048 tokens) frequently underperform medium-sized, logically bounded chunks, proving that memory optimization must be balanced with processing efficacy.
Reactive Streams and Bounded Buffers
To execute chunking effectively across network boundaries without overloading downstream consumers, modern platforms must adopt Reactive Streams architectures utilizing frameworks like Project Reactor, RxJava, or Pekko Streams.
The core operating principle of a reactive stream is boundedness the non-negotiable guarantee that the memory buffer holding in-flight elements is strictly limited. This is achieved through backpressure, a dynamic pull/push protocol where the subscriber explicitly signals to the upstream publisher exactly how many items it currently has the memory capacity to process.
If a highly optimized database query emits 1 million rows to a slow HTTP client process, a traditional synchronous application buffers all 1 million rows in an unbounded memory queue, resulting in an immediate OutOfMemoryError as the heap explodes. In a backpressure-enabled stream, the slow consumer requests a finite number of elements. The upstream publisher suspends execution until the consumer is ready for the next batch, flattening the application's memory curve entirely.
Careless implementation of reactive operators can bypass these safeguards. The flatMap operator, frequently used to merge asynchronous streams, defaults to requesting Long.MAX_VALUE from its upstream source in certain framework iterations, effectively disabling backpressure. Software architects must explicitly configure concurrency limits and backpressure handling strategies to prevent internal buffers from overwhelming the container's memory limit.
Language-Level Memory Release Strategies
Flattening the memory curve also requires instructing the application runtime to return unused memory to the host OS, enabling increased node density and allowing VPA RequestsOnly configurations to safely scale down.
The JVM and ZGC Uncommit: Historically, Java Garbage Collectors aggressively reserved memory but rarely returned it to the OS. This forces Kubernetes operators to massively over-provision nodes. The Z Garbage Collector (ZGC) changes this paradigm, targeting sub-millisecond pauses regardless of heap size. Crucially, ZGC introduces the ability to uncommit unused memory and return it to the operating system. By utilizing the -XX:+ZUncommit flag and configuring the -XX:ZUncommitDelay (e.g., 300 seconds), the JVM continuously analyzes heap utilization. If pages remain unused for the specified duration, the JVM actively releases them back to the Linux kernel.
Golang GOMEMLIMIT and sync.Pool: For Go-based microservices, memory footprint optimization hinges on limiting allocation cycles. GOMEMLIMIT acts as a soft memory cap. Without it, Go can OOM in containers even with tuned GC settings. Setting GOMEMLIMIT to 80-90% of the container's memory limit forces the Go scheduler to aggressively execute a garbage collection cycle when approaching the limit, drastically reducing hard OOM kills. Simultaneously, Go architectures must reduce GC pressure by reusing allocations via sync.Pool, caching allocated but unused objects (like byte buffers) for future reuse, ensuring that hot-path execution flattens the allocation rate entirely.
By combining deterministic QoS assignment, constrained autoscaling parameters with in-place resizing, precise node overhead mathematics, and backpressure-driven application architectures, platform engineering moves firmly beyond reactive debugging. Memory management transforms from a series of disparate fire-fighting exercises into a predictable, cohesive, and resilient global architecture.






