
What is Azure Synapse Analytics?
Azure Synapse Analytics is a service from Microsoft that helps businesses work with large amounts of data quickly and efficiently. It combines several powerful tools in one platform, making it easier to manage and analyze data. Synapse allows you to gather, prepare, and store data for things like business reporting, machine learning, and real-time analysis.
It brings together SQL Data Warehousing, Apache Spark (a tool for big data processing), and Azure Data Lake Storage to help you work with both structured and unstructured data. This means you can query, transform, and analyze data without needing to use many different tools.
Synapse is built to handle large-scale data operations, making it perfect for businesses that need powerful and flexible analytics. Whether you’re creating reports, dashboards, or building machine learning models, Synapse can help you do it all in one place.
Evolution of Data Analytics in the Cloud
The landscape of data analytics has drastically changed in the past decade. On-premises data centers were once the go-to solution for managing and processing data, but as data volumes exploded and computing needs became more complex, cloud-based analytics emerged as a more scalable and cost-efficient alternative.
Azure Synapse represents a new era in cloud data analytics. It consolidates a range of data processing services into one platform, improving collaboration and reducing the need for multiple disparate tools. With the rise of cloud computing, companies can scale their operations quickly, reduce costs, and increase agility—key benefits that traditional on-premises solutions couldn’t offer.
Key Benefits of Azure Synapse
Azure Synapse offers a number of powerful benefits for both developers and business users:
| Benefit | Description |
| Unified Analytics | Combines data warehousing, big data analytics, and data integration in one platform. |
| Scalability | Scalable compute and storage capabilities, allowing organizations to scale resources based on workload requirements. |
| Cost Efficiency | Pay-as-you-go pricing models that help optimize costs. Optimized resource management ensures that you only pay for what you use. |
| Ease of Use | With Synapse Studio, users can manage and interact with data in an intuitive, browser-based interface. |
| Integration with Azure | Native integration with Azure Data Lake, Power BI, Azure Machine Learning, and more. |
| Security and Compliance | Robust security features, including data encryption, role-based access control (RBAC), and integration with Azure Active Directory (AAD). |
Overview of Features
Azure Synapse provides a broad range of features that cover all aspects of modern data analytics:
- Data Warehousing: With dedicated SQL pools, Synapse offers high-performance data warehousing capabilities that are ideal for handling large-scale structured data.
- Big Data Analytics: By leveraging Apache Spark, Synapse supports big data processing, allowing users to analyze large datasets in real-time.
- Data Integration: Synapse simplifies data ingestion, transformation, and orchestration with features like Azure Synapse Pipelines and Data Flows.
- Advanced Analytics: It also supports running machine learning models and running Python and R scripts for advanced data science workloads.
Core Components of Azure Synapse
Azure Synapse Analytics is composed of several key components that work together to provide a comprehensive analytics platform. These components cater to different aspects of data analytics—from storage to computation, transformation, and visualization.
Azure Synapse Studio
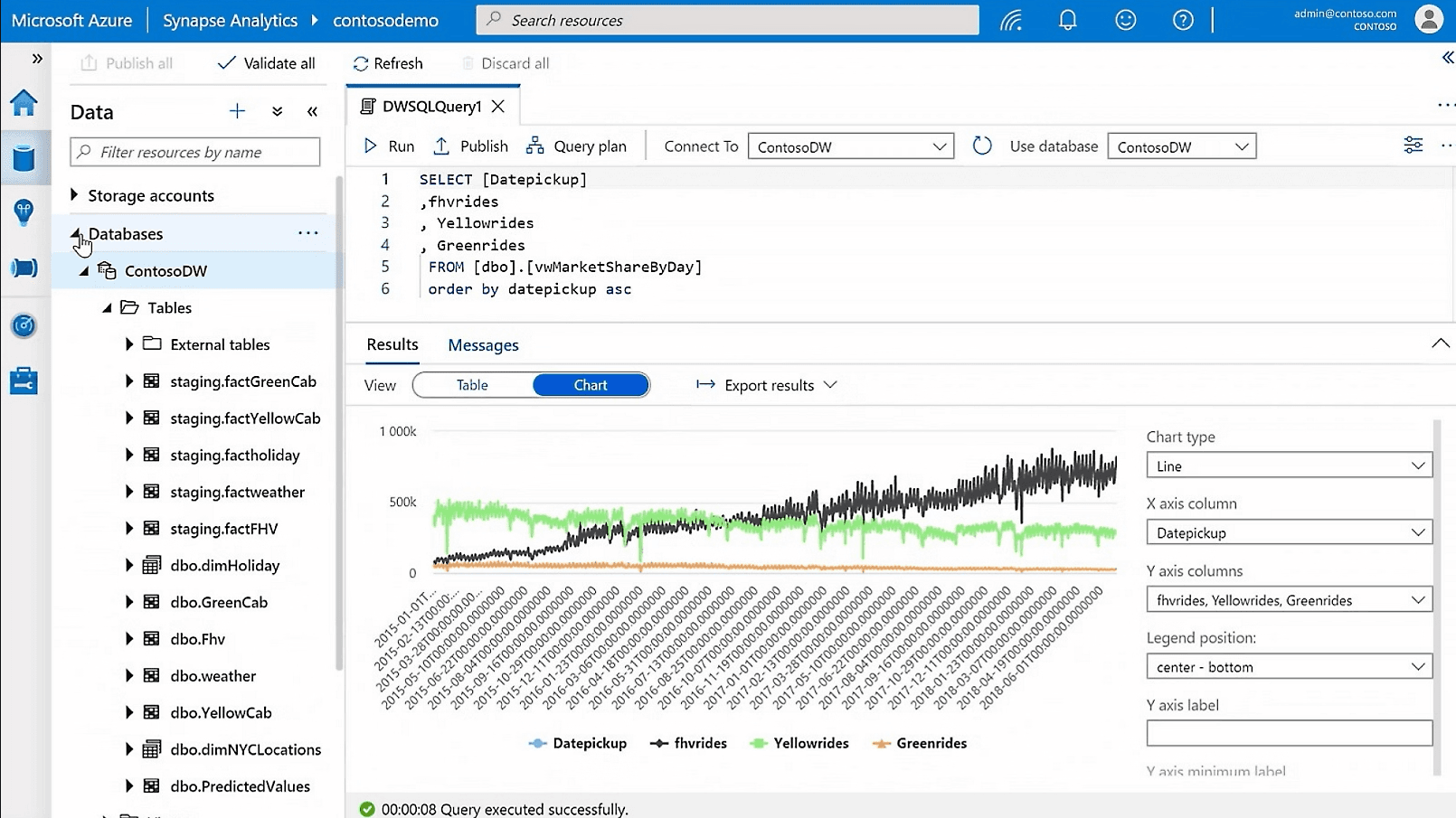
Source : Azure Synapse Analytics
What is Synapse Studio?
Synapse Studio is the integrated development environment (IDE) for managing and orchestrating data workflows in Azure Synapse. It is a web-based tool that allows you to interact with your data and manage various operations within Synapse Analytics. Whether you're working with SQL Pools, Apache Spark, or Data Lake storage, Synapse Studio is the primary interface through which you can manage all of these elements.
How to Navigate and Use Synapse Studio
Synapse Studio provides an intuitive interface that’s organized into different hubs:
- Home Hub: Displays an overview of your Synapse workspace and recent activity.
- Data Hub: Allows you to view and manage datasets, linked services, and data lakes.
- Develop Hub: The place to write and execute SQL queries, Spark scripts, and Data Flows.
- Monitor Hub: Provides a centralized view of pipeline executions, activity runs, and logs for monitoring data workflows.
- Manage Hub: Offers configuration options for security, access control, and workspace settings.
Dedicated SQL Pools (Formerly SQL Data Warehouse)
What are Dedicated SQL Pools?
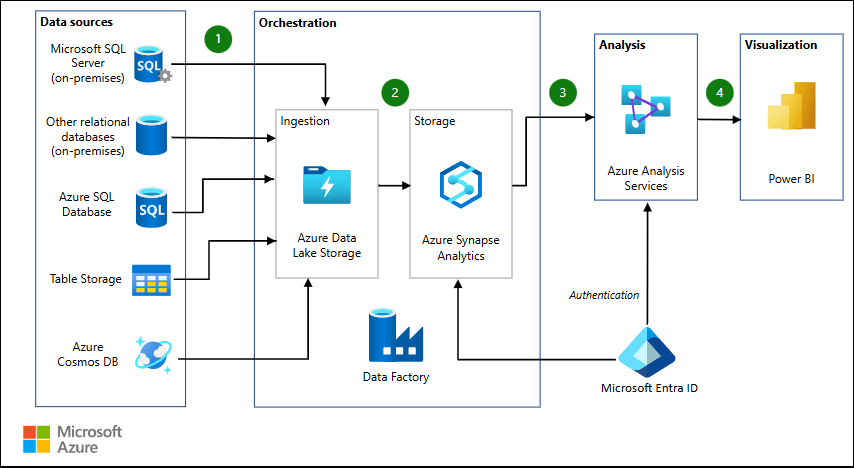
Source: Data warehousing and analytics
Dedicated SQL Pools in Azure Synapse are high-performance, scalable, and fully-managed data warehouses that enable you to store and analyze large datasets. Unlike traditional databases, a dedicated SQL pool can scale up and down depending on the workload, ensuring high performance and cost efficiency. Dedicated SQL Pools are ideal for complex queries and large batch processing of structured data.
Use Cases and Benefits
Dedicated SQL Pools are commonly used for:
- Data Warehousing: Storing and managing large datasets for reporting and BI.
- Business Intelligence: Enabling fast query performance for Power BI dashboards and reports.
- ETL/ELT Workflows: Performing large-scale transformations and data loads.
Performance Tuning Tips
| Tuning Technique | Description |
| Partitioning | Partition large tables based on commonly queried columns to improve query performance. |
| Indexing | Create appropriate indexes (e.g., clustered, non-clustered) to speed up retrieval times. |
| Materialized Views | Use materialized views to cache frequently accessed query results, reducing the need to re-run expensive queries. |
Serverless SQL Pools
Understanding Serverless SQL Pools
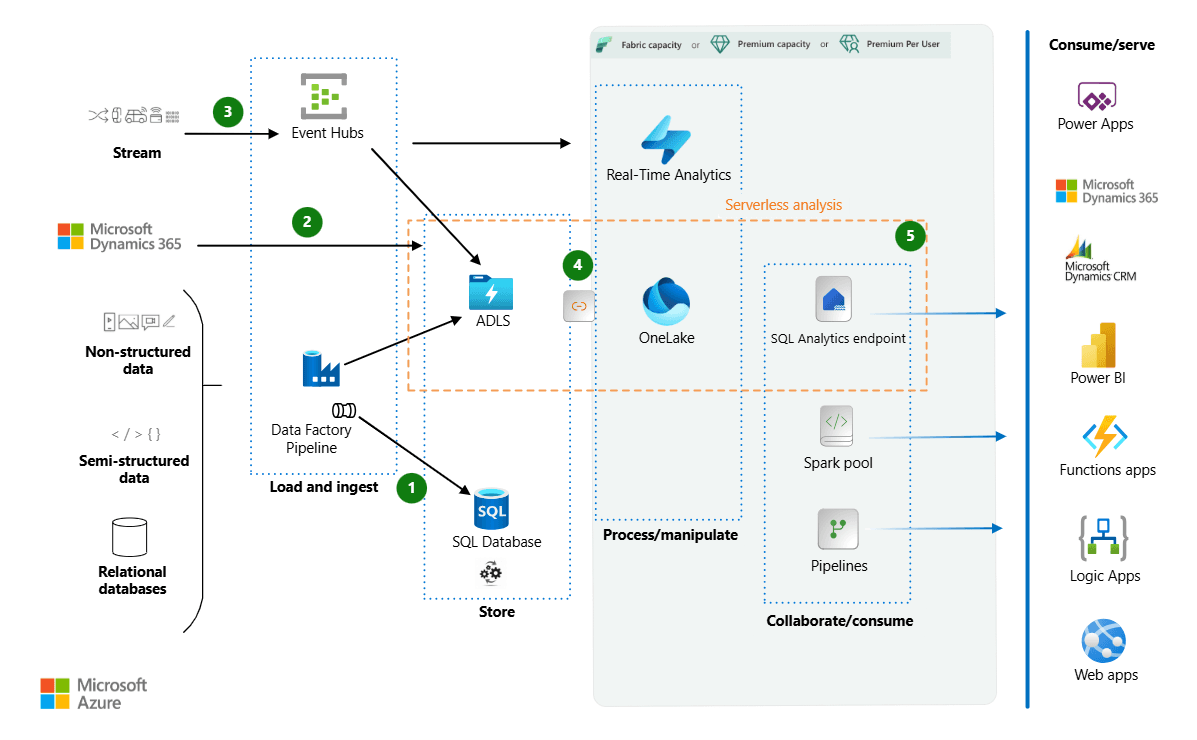
Source: Modern data warehouses for small and midsize-sized businesses
Serverless SQL Pools in Synapse allow you to query data in Azure Data Lake or Blob Storage directly without the need to provision dedicated resources. This is a cost-effective solution for infrequent queries and large datasets where you don’t need a full dedicated SQL pool. Serverless SQL Pools use a pay-per-query model, meaning you only pay for the queries you execute.
When to Use Serverless SQL Pools
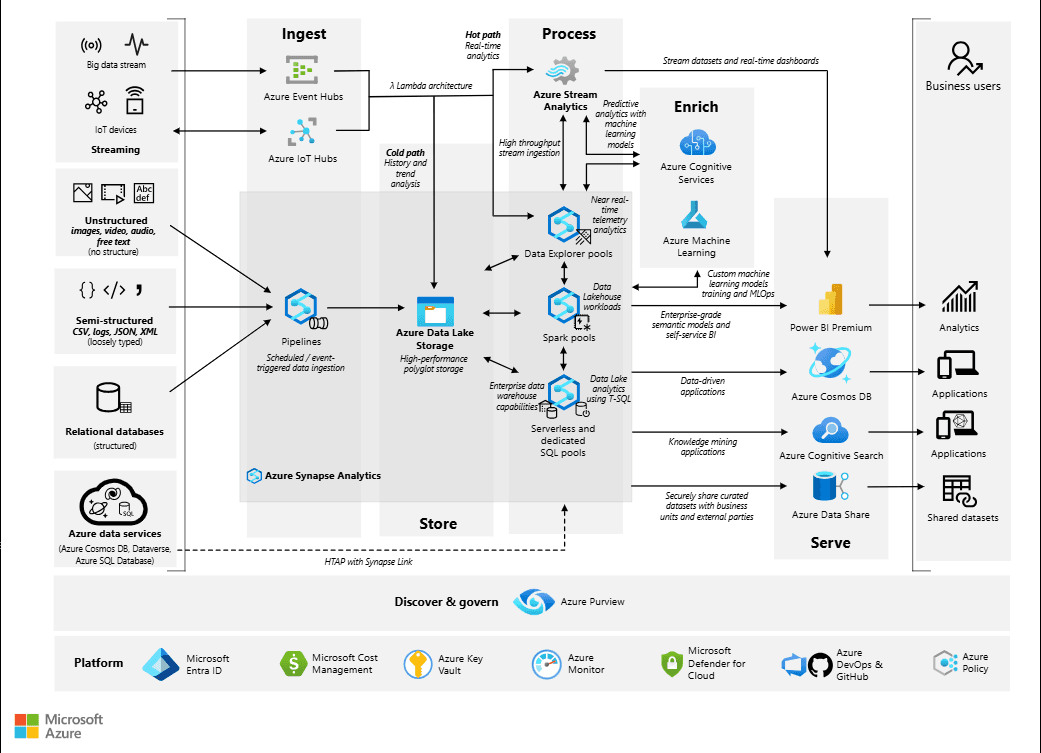
Source: Analytics end-to-end with Azure Synapse
Serverless SQL Pools are ideal for scenarios where:
- On-demand Queries: You need to run ad-hoc queries without maintaining a dedicated SQL pool.
- Exploratory Data Analysis: When you need to explore data stored in Azure Data Lake or Blob Storage without setting up a full warehouse.
- Cost Optimization: When query frequency is low, serverless SQL Pools offer a cost-effective solution by only charging for the compute resources used during query execution.
Apache Spark Pools
Introduction to Apache Spark in Synapse
Apache Spark Pools in Azure Synapse enable distributed data processing for big data workloads. Spark is particularly suited for real-time analytics, machine learning, and processing large datasets that cannot be handled by traditional databases. With Spark Pools, you can leverage both Spark SQL and Spark DataFrames for data analysis, transformation, and machine learning in a highly scalable environment.
Setting up and Configuring Spark Pools
Setting up Spark Pools in Synapse Studio is straightforward:
- Navigate to the Manage Hub in Synapse Studio.
- Select Apache Spark Pools and click New Pool.
- Configure the pool by specifying the number of nodes, node size, and scaling options based on your workload.
- Once set up, you can run Spark jobs using either Notebooks or Spark SQL.
Data Integration in Azure Synapse
Azure Synapse Analytics offers comprehensive capabilities for integrating data from various sources, transforming it to suit your analytics needs, and storing it in a secure, scalable environment. Whether you're dealing with structured or unstructured data, Synapse provides tools for data ingestion, transformation, storage management, and even advanced analytics—all in a unified platform.
Data Ingestion
Supported Data Sources (Structured & Unstructured Data)
Azure Synapse supports a wide range of data sources, both structured and unstructured. The platform is designed to work seamlessly with Azure-native services like Azure Data Lake, Azure Blob Storage, and Azure SQL Database, as well as on-premises and third-party systems. This makes it easy to ingest data from multiple sources for unified analytics.
Structured Data includes relational databases (SQL Server, MySQL, PostgreSQL), flat files (CSV, Excel), and cloud-based data warehouses (e.g., Azure SQL Data Warehouse, Amazon Redshift).
Unstructured Data includes JSON, Parquet, Avro, and other file formats commonly used for big data processing. Additionally, Synapse integrates easily with Azure Data Lake and Azure Blob Storage to handle vast amounts of unstructured data efficiently.
| Data Type | Examples | Ingestion Methods |
| Structured Data | SQL Server, Azure SQL Database, CSV files | Copy Data, PolyBase, ADO.NET |
| Unstructured Data | JSON, Parquet, Avro, Text files, Log files | Data Flows, Spark Pools |
Methods of Data Ingestion (Copy Data, Data Flows, etc.)
Azure Synapse provides several methods for ingesting data into your environment:
- Copy Data: This method is ideal for bulk data transfers from various sources (e.g., databases, storage accounts) into Synapse. You can perform these operations using Synapse pipelines or the Azure Data Factory interface.
- Data Flows: For more complex transformations during ingestion, Data Flows allow you to visually design data transformation pipelines, including filtering, aggregations, joins, and more.
- PolyBase: This method enables you to directly query external data stored in Azure Blob Storage or Azure Data Lake without ingesting it into Synapse first.
- Spark Pools: For unstructured data (like logs, JSON, Parquet), you can use Apache Spark for scalable ingestion and transformation.
Data Transformation
ETL vs ELT in Synapse
Data transformation in Azure Synapse can be approached using two primary paradigms: ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform).
- ETL: In traditional ETL processes, data is extracted from the source, transformed, and then loaded into the data warehouse. This method is used when complex transformations are required before loading the data.
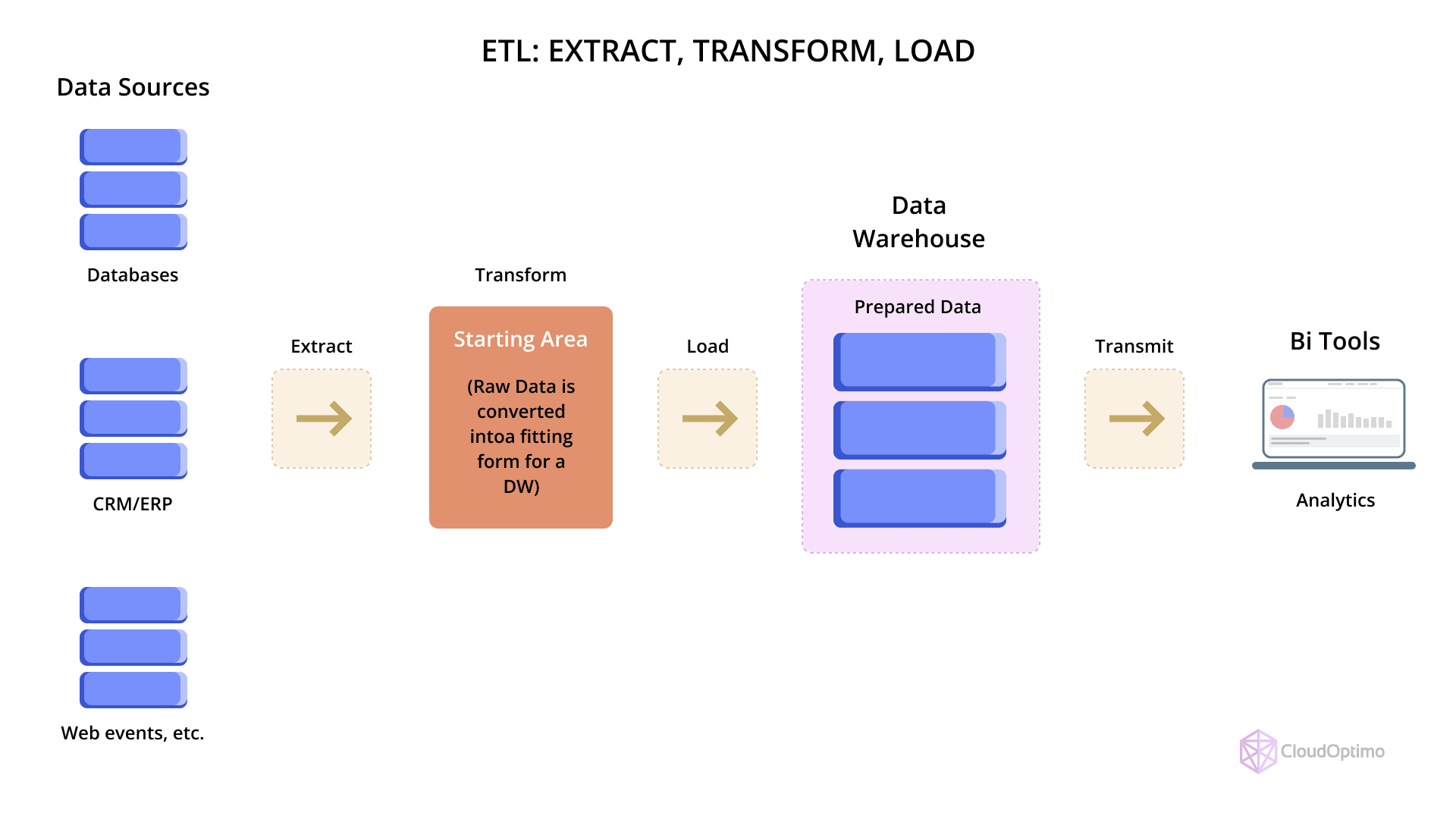
- ELT: With ELT, data is first loaded into the data warehouse, and then transformations are applied within the data warehouse itself. Azure Synapse typically favors ELT, as it allows for faster processing, particularly with large datasets, thanks to its scale-out capabilities.
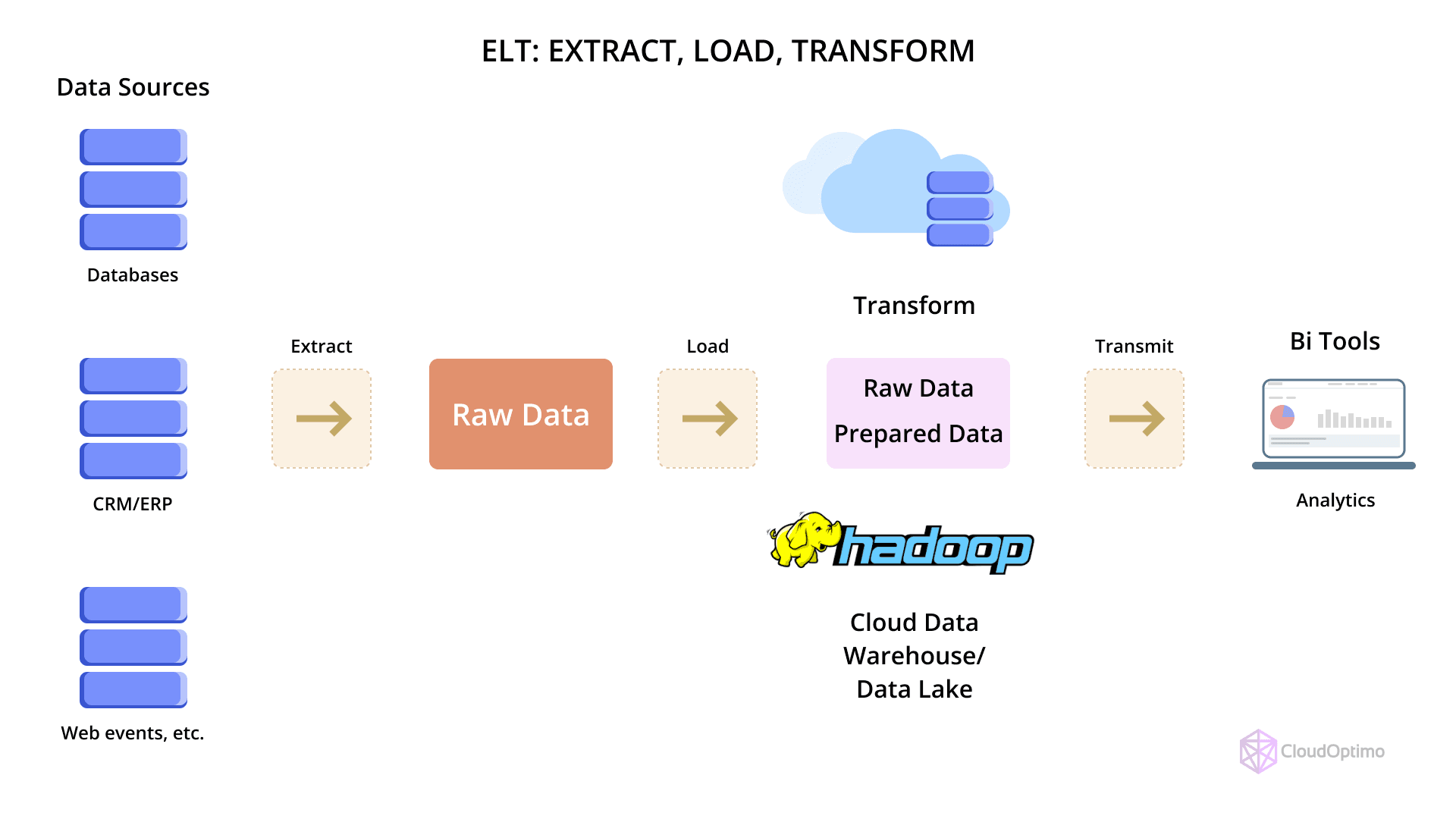
| Metrics | ETL | ELT |
| Process | Extract, Transform, Load | Extract, Load, Transform |
| Use Case | Complex data transformations before loading | Fast processing and transformation within the warehouse |
| Performance | May be slower with large datasets | Faster with scalable compute in Synapse |
Using Data Flows for Transformation
Azure Synapse Data Flows allow you to design data transformation logic visually, making it easier to process and transform data without writing code. You can design complex transformations such as:
- Data Cleaning: Removing duplicates, filtering, and replacing missing values.
- Aggregations: Summarizing data at various levels.
- Joins and Merges: Combining data from multiple sources.
- Lookup Transformations: Enriching data by looking up additional information from reference datasets.
Data Flows are especially useful when building data pipelines for large-scale transformation tasks. They provide scalability, with Synapse automatically scaling compute resources to handle large volumes of data.
Azure Synapse Pipelines Overview
Azure Synapse Pipelines are orchestration tools that allow you to automate and schedule data workflows. They provide a unified interface for managing data ingestion, transformation, and movement across various services.
- Creating Data Pipelines in Synapse Studio: You can build, monitor, and manage data pipelines within Synapse Studio, which allows you to visually design the sequence of activities involved in data processing. Pipelines support activities like copying data, executing stored procedures, invoking Azure functions, and more.
- Automation and Scheduling: Synapse Pipelines can be scheduled to run at specific times or triggered by events, ensuring that data is processed automatically and consistently.
| Pipeline Activity | Description | Examples |
| Copy Activity | Copy data from source to destination. | SQL Database to Data Lake |
| Execute Activity | Run stored procedures, SSIS packages, or scripts. | Trigger Python Script for ML models |
| Data Flow Activity | Apply transformations to the data during ingestion. | Data cleansing, aggregation, or merging |
Data Wrangling and Preparation
Working with Data Wrangling (Data Prep)
Azure Synapse includes a powerful tool for data wrangling, also known as data prep, which allows users to cleanse and shape data before performing analysis. Using the Data Wrangling interface in Synapse Studio, you can perform tasks such as:
- Removing or replacing missing values.
- Converting data types and formatting.
- Filtering and transforming data into a desired shape.
This is an ideal tool for data engineers or analysts who need to quickly prepare data for downstream processes like analysis, reporting, or machine learning.
Data Storage and Management
SQL-Based Storage Options
In Synapse, there are two primary types of SQL-based storage options:
- Dedicated SQL Pool: High-performance, scalable data storage optimized for large-scale analytical workloads. Perfect for complex queries and large data volumes.
- Serverless SQL Pool: Provides on-demand querying of data without pre-allocating storage or compute resources. Ideal for infrequent querying or small datasets.
| SQL Storage Option | Dedicated SQL Pool | Serverless SQL Pool |
| Use Case | Large-scale data warehousing and reporting | On-demand queries, especially on Data Lake |
| Cost | Fixed cost based on provisioned compute | Pay-per-query |
| Performance | Optimized for large, complex queries | Ideal for ad-hoc queries |
Big Data Storage with Azure Data Lake
Azure Synapse integrates tightly with Azure Data Lake Storage (ADLS), a scalable and secure repository for big data. ADLS supports storing unstructured and semi-structured data, such as log files, JSON, and Parquet, making it an essential component for big data workloads. With Synapse, you can directly query this data using either Spark Pools or Serverless SQL Pools, enabling seamless analytics over both structured and unstructured data.
Managing and Securing Data
Azure Synapse provides robust security features to help protect your data. These include:
- Data Encryption: Data is encrypted both at rest and in transit, ensuring confidentiality.
- Role-Based Access Control (RBAC): Fine-grained access controls to ensure that only authorized users can access or modify data.
- Managed Identity: Synapse supports managed identities for accessing other Azure resources securely, without needing credentials.
Advanced Analytics in Azure Synapse
Running Data Science and Machine Learning Models
Azure Synapse integrates with Azure Machine Learning (Azure ML) to enable data scientists to build, train, and deploy machine learning models directly within the Synapse environment. You can use Python and R scripts for statistical analysis and model training, and then run them in a scalable environment using Spark pools.
Using Synapse with Azure Machine Learning
Azure Synapse allows you to leverage Azure Machine Learning for model training, experimentation, and deployment, all within the same ecosystem.
Spark for Big Data Processing
Apache Spark pools in Synapse are optimized for large-scale data processing, enabling real-time analytics and machine learning.
Using Spark Notebooks for Analytics
Spark Notebooks in Synapse provide an interactive, code-driven interface to explore and analyze data, run machine learning models, and visualize results.
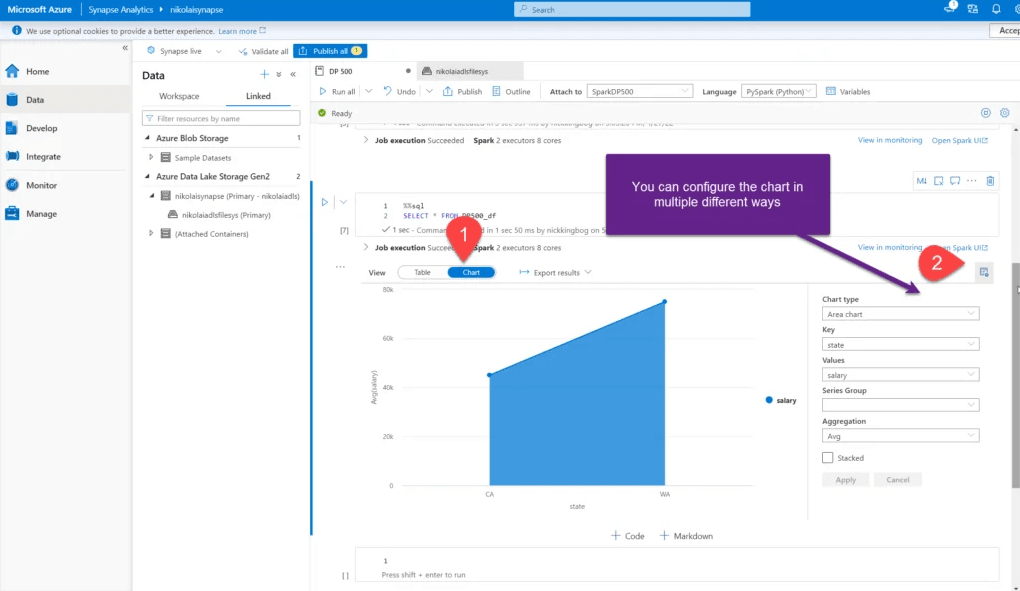
A screenshot of a Spark Notebook within Synapse Studio, showing code execution and data visualizations.
Source: data-mozart.com
Integrating Power BI with Azure Synapse
Azure Synapse integrates natively with Power BI for data visualization and reporting. You can easily create dashboards and reports by connecting Power BI directly to Synapse's SQL Pools or Apache Spark for real-time analytics.
Performance Tuning and Optimization
Azure Synapse Analytics is a powerful platform designed to handle large-scale data workloads and analytics. However, like any robust system, achieving optimal performance requires careful tuning and a proactive approach to optimization. Whether you’re running large-scale queries, building data pipelines, or working with Spark pools, performance tuning is essential for minimizing costs, speeding up query execution, and improving overall efficiency.
Let’s dive into some best practices and tips for performance optimization in Azure Synapse.
Best Practices for Query Performance
To get the most out of your Synapse Analytics environment, optimizing query performance is critical. Here are some best practices to consider:
- Partitioning Data for Faster Queries
One of the most effective ways to optimize query performance is by partitioning large tables. Partitioning divides your data into smaller, more manageable chunks based on a specific column, such as date or region. This enables Synapse to read only relevant data, reducing I/O operations and speeding up query times. - Leverage Data Distribution
Azure Synapse allows you to distribute data across multiple nodes. For tables with large datasets, using hash distribution or round-robin distribution can significantly improve query performance by distributing the data more evenly and minimizing data movement during query execution. - Optimize Queries by Avoiding Cross Joins and Subqueries
Cross joins and subqueries can be expensive in terms of performance, especially on large datasets. Instead, use joins with appropriate filters and ensure that queries are written efficiently by avoiding unnecessary complexity. - Use Columnstore Indexes for Faster Aggregations
Columnstore indexes are designed for analytical queries and can improve query performance, especially when performing aggregations or scans on large tables. Columnstore indexes compress data and reduce the amount of I/O required during query execution. - Analyze and Rewrite Inefficient Queries
Review query execution plans and look for opportunities to simplify or optimize your queries. For example, avoid unnecessary computations in SELECT clauses or complex WHERE conditions that might slow down the query processing.
Tips for Optimizing SQL Query Performance
- Tune SQL Query Execution Plans
Azure Synapse provides insights into query performance through execution plans. Always check the execution plan of slow queries. Identifying operations like table scans or nested loops can help you rewrite queries to make them more efficient. - Consider Using Caching for Frequent Queries
Caching frequently queried data or using materialized views can dramatically reduce response times for high-volume, repetitive queries. This approach ensures that the system doesn’t need to perform the same time-consuming calculations or data scans multiple times. - Manage Resource Utilization with Query Priorities
When dealing with concurrent workloads, consider configuring query priorities or resource governance. By setting resource limits, you can ensure that critical queries get the resources they need, while non-essential tasks do not consume excessive resources.
Managing Indexes and Partitioning
Proper indexing and partitioning are crucial to ensuring optimal performance in Azure Synapse. Here’s how to manage them effectively:
- Use Clustered Columnstore Indexes for Large Tables
For large tables, using clustered column store indexes ensures fast query performance for read-heavy workloads. These indexes help compress the data and store it in an optimized format for analytics workloads. - Partition Tables Based on Usage Patterns
Partitioning is not just about dividing data randomly; it’s about understanding the query patterns and aligning them with your partitioning strategy. For example, partitioning by date works well if most queries are time-based (e.g., monthly or yearly reports). - Monitor Index Usage
Over time, indexes can become fragmented, especially with frequent updates or deletes. Regularly monitor the health of indexes and rebuild or reorganize them as needed to maintain optimal performance.
Monitoring Performance in Azure Synapse
Monitoring your Synapse environment is crucial for identifying bottlenecks and optimizing resources. Azure Synapse provides a suite of tools to help you keep track of query performance, workloads, and resource utilization.
- Using Synapse Studio to Monitor Queries and Workloads
Synapse Studio offers built-in monitoring tools that give you real-time insights into query performance and workload execution. You can monitor the status of queries, view execution details, and drill into specific resource consumption metrics to pinpoint performance issues. - Performance Insights and Query Optimization Techniques
Azure Synapse integrates with Azure Monitor and SQL Analytics to provide deeper insights into your data processing and workloads. Use SQL Insights to gather information about query duration, wait times, and resource utilization, which can guide your optimization efforts. Analyzing query execution statistics and resource consumption patterns can help you identify areas where you can improve query performance or optimize resource allocation.
Scaling and Cost Management in Azure Synapse Analytics
Azure Synapse allows you to scale your resources based on the needs of your workload, but managing the cost of these resources is just as important. Ensuring that your environment is both scalable and cost-effective requires careful planning and monitoring. Below are strategies for scaling and managing costs efficiently.
Managing Compute Resources
- Choose the Right Pool for the Right Task
Synapse offers both dedicated SQL pools and serverless SQL pools. For large, complex queries, dedicated SQL pools provide optimized resources. On the other hand, serverless pools are ideal for on-demand queries with no long-term resource commitment. Understanding the right pool for your workload is essential to controlling costs and performance. - Scale Resources Dynamically
Azure Synapse enables you to scale compute resources up or down based on demand. For example, you can increase the size of your dedicated SQL pool during periods of high demand and scale it down during off-peak times. This flexibility helps manage both performance and cost. - Monitor Resource Usage with Synapse Studio
Synapse Studio offers integrated monitoring features that allow you to track resource consumption across dedicated SQL pools, Spark pools, and serverless environments. Regularly monitoring resource usage can help identify opportunities to reduce unnecessary costs, such as idle resources or underused clusters.
Managing Costs with Azure Synapse
- Use Cost Management Tools
Azure provides several cost management tools, such as Azure Cost Management + Billing and Azure Advisor, to help you track and optimize your spending. These tools provide recommendations for cost reduction and allow you to set budgets and alerts to prevent overspending. - Optimize Storage Costs
Storage can become a significant cost in Azure Synapse. Use Azure Data Lake Storage to store large datasets in an affordable and scalable manner. Additionally, consider using data compression techniques and removing unused datasets to optimize storage costs. - Leverage Serverless Features for On-Demand Workloads
By using serverless SQL pools for ad-hoc or infrequent queries, you can avoid paying for idle resources, which helps keep costs low. Serverless pools allow you to pay only for the queries you run, making them a cost-effective option for specific tasks.
Security and Compliance in Azure Synapse Analytics
As an enterprise-grade analytics platform, Azure Synapse places a strong emphasis on security and compliance. Protecting your data and ensuring it is handled according to industry regulations is vital for any organization working with sensitive information.
Identity and Access Management
- Authentication Methods (Azure Active Directory, Managed Identities)
Azure Synapse integrates with Azure Active Directory (Azure AD) for identity and access management. You can authenticate users using Azure AD accounts, ensuring a secure and centralized authentication process. Managed identities are another useful feature, allowing resources to securely access other Azure services without requiring explicit credentials. - Access Control (RBAC, Security Policies)
Azure Synapse employs Role-Based Access Control (RBAC), which allows you to assign permissions based on user roles, ensuring that only authorized users can access specific datasets and services. Security policies help you control the flow of data and define access rules at a granular level.
Network Security
- Virtual Networks and Private Endpoints
Synapse supports secure connections via virtual networks (VNets) and private endpoints, which provide an additional layer of security by isolating traffic from the public internet. This ensures that your data is transferred securely between services and reduces the risk of external threats. - Data Encryption (At Rest and In Transit)
All data in Azure Synapse is encrypted, both at rest and in transit. This ensures that sensitive information is protected from unauthorized access. Azure uses industry-standard encryption protocols to safeguard your data throughout its lifecycle.
Compliance Certifications
Azure Synapse complies with numerous industry standards and regulations, such as GDPR, HIPAA, and SOC 2, ensuring that your organization meets the necessary compliance requirements for storing and processing data.
Best Practices for Secure Data Handling
- Implement Fine-Grained Access Controls
Always implement the principle of least privilege (PoLP) when assigning permissions. Grant only the necessary access required for each user to perform their tasks, and regularly review and update access controls. - Encrypt Sensitive Data
Always encrypt sensitive data, both in transit and at rest, to prevent unauthorized access. Make use of built-in encryption options available in Azure Synapse, such as Transparent Data Encryption (TDE).
Real-World Use Cases and Scenarios
Azure Synapse Analytics serves a variety of use cases, ranging from data warehousing to big data analytics, business intelligence, and machine learning. Let's dive into a few key scenarios:
1. Data Warehousing Use Case
Migrating from On-Premises Data Warehouses to Azure Synapse:
Organizations moving from on-premises data warehouses (like SQL Server or Oracle) to Azure Synapse benefit from enhanced scalability, cost savings, and better performance. The migration process involves:
- Assessment: Understand data structure and performance needs.
- Migration: Use tools like Azure Data Factory or PolyBase for data transfer.
- Optimization: Leverage performance features like indexing and partitioning.
Benefits:
- Scalability: Dynamic scaling to handle growing data.
- Cost Savings: Pay-as-you-go model.
- Performance: Faster analytics with distributed compute and storage.
2. Big Data Analytics Use Case
Analyzing Large Datasets with Apache Spark:
Apache Spark within Azure Synapse is ideal for processing large datasets, offering real-time analytics and distributed computation.
How It Works:
- Data Ingestion: Ingest data via Synapse’s Copy Data or Spark Pools.
- Data Processing: Use Spark for real-time or batch processing.
- Integration with Data Lake: Process unstructured data stored in Azure Data Lake.
Benefits:
- High Performance: Efficient processing via distributed computation.
- Cost Efficiency: Scale up or down based on workload demands.
3. Business Intelligence (BI) Use Case
Integrating Synapse with Power BI for Reporting:
Synapse integrates seamlessly with Power BI for real-time data analysis, enabling interactive dashboards and reports.
How It Works:
- Direct Query: Power BI connects to Synapse’s SQL or Spark Pools.
- Dashboards: Create interactive visualizations for insights.
Benefits:
- Real-Time Analytics: Live querying and up-to-date reports.
- Scalability: Synapse handles large datasets while Power BI visualizes them efficiently.
4. Machine Learning and AI Use Case
Implementing AI/ML Models with Azure Synapse:
Azure Synapse supports machine learning workflows, integrating with Azure Machine Learning (Azure ML) for model training, deployment, and predictions.
How It Works:
- Data Preparation: Prepare data using Synapse’s data wrangling tools.
- Model Training: Train models with Azure ML integration.
- Inference: Run predictions using deployed models.
Benefits:
- End-to-End Workflow: From data preparation to model deployment.
- Scalability: Leverage Spark’s distributed power for large-scale models.
Azure Synapse Pricing and Cost Management
One of the key factors when adopting Azure Synapse Analytics is understanding how its pricing works. Azure Synapse offers a flexible, consumption-based pricing model, where you only pay for what you use. However, it’s essential to optimize costs to get the most out of your Synapse environment.
Understanding Pricing Models
Azure Synapse pricing is primarily based on the following components:
- SQL Pools (Dedicated and Serverless):
- Dedicated SQL Pools: Charged based on the provisioned compute resources (data warehouse units or DWUs). You pay for the compute capacity, whether you're using it or not, so scaling up or down can impact your costs.
- Serverless SQL Pools: Charged based on the amount of data processed by queries. Since there’s no pre-provisioned compute, you only pay for the data scanned during the queries.
- Apache Spark Pools:
- Spark Pools are charged based on the number of Spark nodes used and the duration for which they are running. The longer the cluster is running, the higher the cost.
- Data Storage:
- Storage costs are based on the amount of data stored in Azure Data Lake and SQL Pools. Azure offers scalable storage options, so the more data you store, the more it will cost. However, Azure provides multiple tiers of storage (Hot, Cool, and Archive) to help optimize storage costs based on access frequency.
- Other Components:
- Data Pipelines are charged based on pipeline execution frequency and the activities performed.
- Power BI integration may add additional costs based on the amount of data queried and visualized.
| Component | Pricing Model | Key Considerations |
| SQL Pools (Dedicated) | Pay for provisioned compute (DWUs) | Scale up/down as needed. |
| SQL Pools (Serverless) | Pay for data processed (per query) | Ideal for ad-hoc, on-demand queries. |
| Apache Spark Pools | Charged by nodes and runtime duration | Costs are based on cluster size and duration. |
| Data Storage | Pay for data stored (Azure Data Lake, SQL Pools) | Different tiers (Hot, Cool, Archive) for cost optimization. |
| Data Pipelines | Charged based on execution and activities | Monitor and optimize pipeline usage. |
Cost Optimization Strategies
- Scale Resources Appropriately:
- For SQL Pools, consider scaling down during off-peak hours to reduce costs. With Serverless SQL Pools, ensure that you query only the necessary data to avoid unnecessary data scans.
- Data Compression and Archiving:
- Use data compression techniques and archive old data to lower storage costs in Azure Data Lake.
- Optimize Spark Jobs:
- Reduce Spark cluster runtimes by optimizing Spark jobs and removing unnecessary steps.
- Monitor and Control Resource Usage:
- Use Azure Synapse Studio’s monitoring tools to track resource usage. Set up alerts to notify you if resource consumption exceeds a certain threshold.
Best Practices for Minimizing Costs
- Use Serverless Pools for On-Demand Queries: If you only run occasional queries, use serverless SQL Pools. These are cost-effective as you only pay for the data processed.
- Leverage Reserved Capacity for SQL Pools: If you have predictable workloads, consider committing to reserved capacity for SQL Pools to save up to 65% compared to pay-as-you-go pricing.
- Monitor Storage Usage Regularly: Regularly monitor and manage your storage usage, using tiered storage for infrequent access data.
Azure Cost Management and Budgeting Tools
Azure provides several tools to help monitor and manage costs:
- Azure Cost Management and Billing: This allows you to track your costs and usage in real-time. You can set budgets and receive alerts when approaching budget limits.
- Azure Pricing Calculator: This helps you estimate the cost of using Azure Synapse based on your expected usage.
- Azure Advisor: Provides personalized best practice recommendations for cost optimization based on your usage patterns.
By understanding pricing and leveraging cost optimization techniques, you can ensure that your Azure Synapse environment remains cost-effective while meeting your business needs.






