
Cloud cost management has emerged as a critical challenge in modern infrastructure operations. As organizations increasingly adopt complex cloud architectures, the need for sophisticated cost anomaly detection mechanisms has become challenging. This technical analysis explores the methodologies, implementation strategies, and best practices for establishing effective cloud cost monitoring systems.
Cost Anomaly refers to unexpected or irregular patterns in spending related to cloud resources. These anomalies indicate deviations from typical usage or cost trends, often resulting in significant budget overruns or wasted resources. Identifying and addressing cost anomalies is crucial for effective cloud cost management.
What is Cost Anomaly Detection?
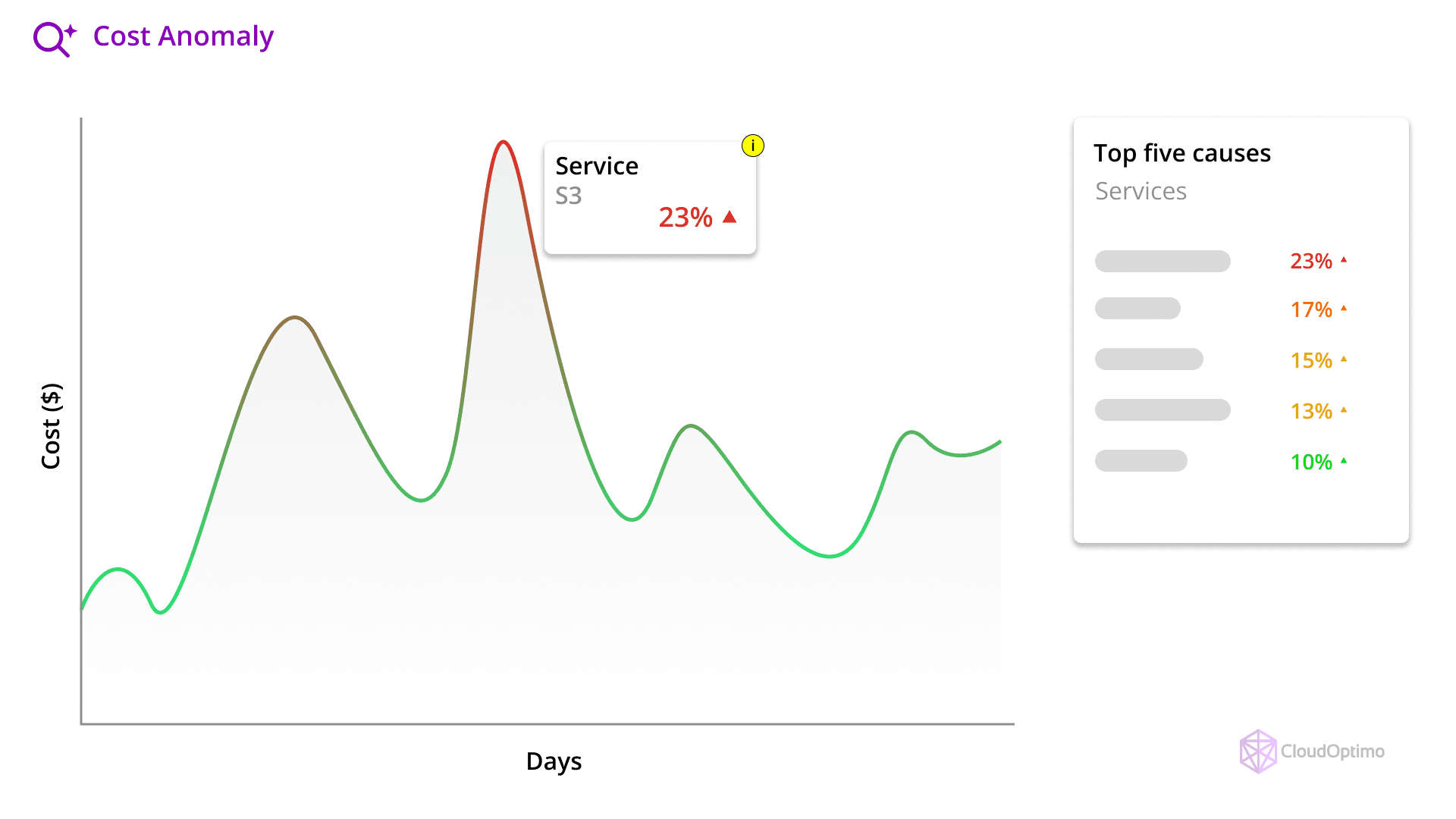
Cost anomaly detection in cloud computing refers to the automated identification of unusual or unexpected spending patterns in cloud resource usage. These anomalies can manifest as:
- Sudden spikes in resource consumption
- Gradual cost inflation over time
- Unexpected charges from unused or idle resources
- Irregular spending patterns across different services
Understanding how cost anomalies impact real businesses provides a deeper perspective on why anomaly detection is critical.
Visual Representation of Cost Anomaly Detection Process
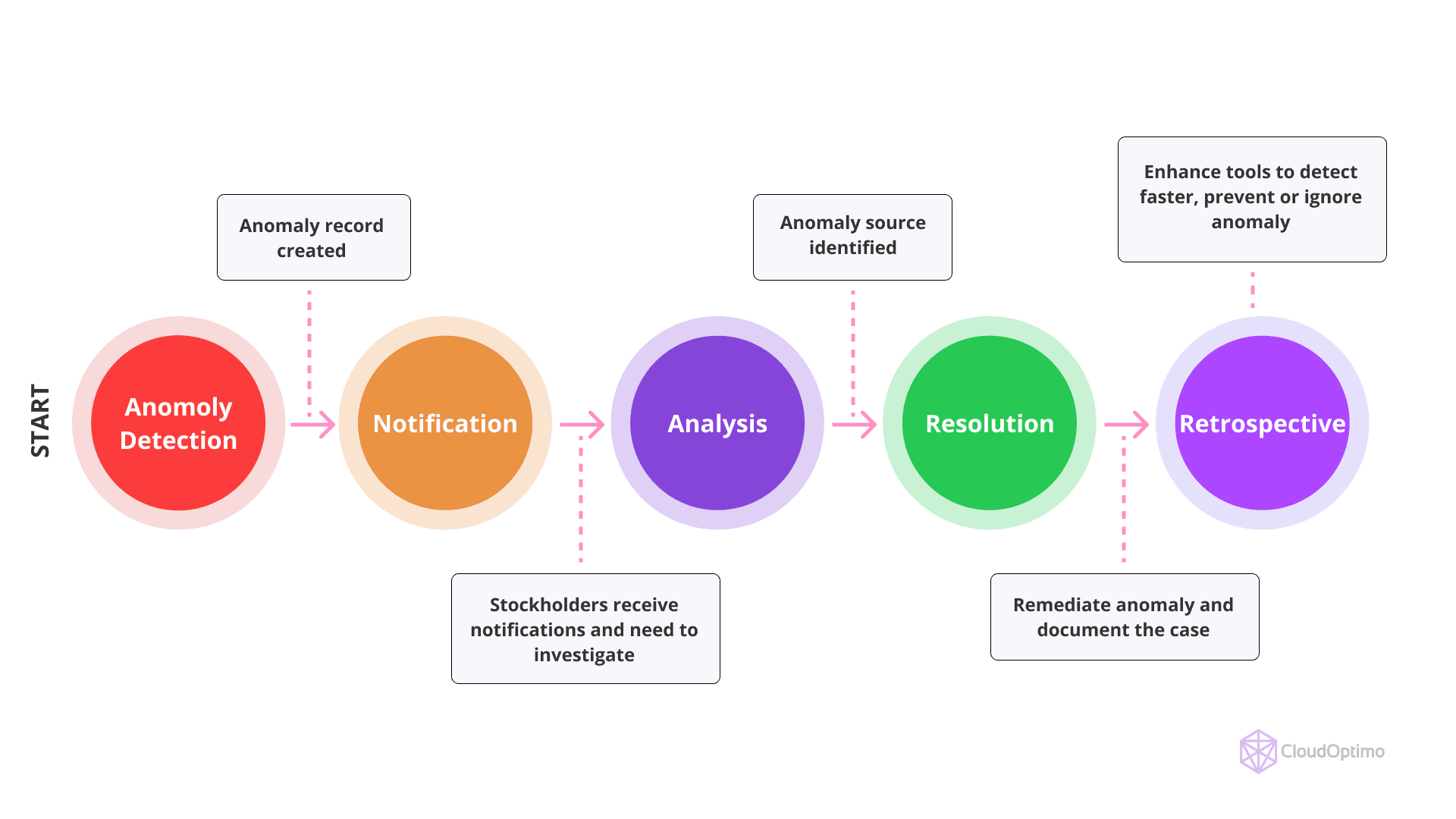
Consider the following scenarios where unexpected costs have had significant operational consequences
Real-World Impact Examples
Consider these scenarios:
- E-commerce Platform: A company experienced a $50,000 unexpected cost due to an infinite loop in a serverless function, triggering continuous executions.
- Data Analytics Firm: Misconfigured data transfer settings resulted in cross-region data movement, leading to $30,000 in unnecessary charges.
- Gaming Company: An auto-scaling configuration error during a viral game launch caused infrastructure costs to increase 10x overnight.
The examples above illustrate just a few of the many ways cost anomalies.
In a broader context, cost anomalies typically fall into three major categories: usage-based, configuration-based, and access-based anomalies. Let’s take a closer look at each.
Understanding the Problem Space
Common Anomaly Types
- Usage-Based Anomalies
- Compute Resource Spikes: Unexpected increases in CPU, memory, or storage utilization.
- Storage Explosions: Sudden growth in storage use due to data duplication or unoptimized retention policies.
- Network Traffic Surges: Increased data transfer costs from high ingress or egress network activity.
- Configuration-Based Anomalies
- Inadequate Instance Sizing: Provisioning instances that are either too large or too small for their workloads, leading to inefficiency.
- Unused Reserved Instances: Pre-purchased capacity that goes unused, wasting capital.
- Improper Auto-scaling Settings: Auto-scaling thresholds not properly tuned, leading to either over-provisioning or underutilization.
- Access-Based Anomalies
- Unauthorized Resource Creation: Instances or services spun up without approval, often leading to shadow IT issues.
- Credential Misuse: Unintended or malicious use of credentials resulting in the provisioning of expensive resources.
Identifying anomalies is just the first step. Understanding the potential impact on business operations, finances, and strategy is essential for justifying investments in cloud cost anomaly detection systems.
- Usage-Based Anomalies
Business Impact Scenarios
Understanding the business implications helps justify investment in anomaly detection:
- Financial Impact:
- Direct cost overruns beyond the estimated budget.
- Difficulty in forecasting accurate budgets due to unpredicted expenses.
- Uncovering hidden resource wastage (such as unused instances or data transfers).
- Operational Impact:
- Service reliability may suffer if resources are over- or under-provisioned.
- Optimization efforts may be delayed if anomalies go undetected.
- Resource utilization remains suboptimal, affecting business performance.
- Strategic Impact:
- Cost anomaly detection can help in cloud migration strategies by identifying inefficiencies.
- Anomalies can influence architectural decisions, especially in multi-cloud or hybrid environments.
- Financial Impact:
Emerging Challenges
Modern cloud infrastructures are highly dynamic, and new challenges have emerged in recent years. These challenges make cost anomaly detection more critical.
- Dynamic Resource Allocation:
- Auto-scaling architectures constantly adjust the number of instances or resources, making it difficult to track normal vs. abnormal patterns.
- Serverless computing models further obscure resource consumption patterns.
- Complex Pricing Models:
- Cloud providers offer variable pricing structures (on-demand, reserved instances, spot instances), making it challenging to predict costs accurately.
- Region-specific pricing differences add another layer of complexity to cost management.
- Distributed Architecture:
- Modern cloud infrastructures are often built on microservices architecture, where services are scattered across multiple regions and providers. This complicates cost attribution and anomaly detection.
- Multi-cloud and hybrid infrastructures increase the complexity of cost tracking and anomaly detection.
To address these challenges, organizations must establish a solid technical foundation that enables real-time detection and remediation of cost anomalies.
This involves a structured approach to data collection, analysis, and automated response mechanisms, ensuring that cloud environments remain cost-efficient and secure.
Technical Foundation Of Cost Anomaly Detection
To build an effective cost anomaly detection system, we need to break it down into three primary components:
- Data Collection Layer
- This layer is responsible for gathering essential cloud cost and usage data through APIs and log aggregation systems.
- Cloud provider APIs, like AWS Cost Explorer, Azure Cost Management, and Google Cloud Billing APIs, are the key data sources.
- Analysis Layer
- This is where the actual detection occurs. It involves applying statistical analysis, machine learning algorithms, or pattern recognition methods to historical data to find anomalies.
- Historical data helps establish baselines against which current usage can be compared.
- Response Layer
- Once anomalies are detected, this layer handles the response, such as alerting teams or automatically taking necessary action.
- Automated responses may involve scaling down resources or sending alerts to the operations team.
Data Collection Fundamentals
Data collection forms the foundation of cloud cost anomaly detection.
Here's a basic example of a Python class for collecting metrics:
| class CloudCostAssesss: def __init__(self): self.metrics = { 'resource_metrics': { 'compute_usage': ['cpu_utilization', 'memory_usage'], 'storage_metrics': ['iops', 'throughput'], 'network_metrics': ['ingress_bytes', 'egress_bytes'] }, 'cost_metrics': { 'hourly_costs': ['service_costs', 'resource_costs'], 'aggregate_costs': ['project_costs', 'team_costs'] } } def collect_metrics(self, timeframe): return { 'metrics': self.gather_resource_metrics(timeframe), 'costs': self.gather_cost_data(timeframe) } |
This collector class forms the foundation for gathering essential metrics. Each metric type serves a specific purpose:
- compute_usage: Tracks resource utilization patterns
- storage_metrics: Monitors data storage and access patterns
- network_metrics: Analyzes data transfer costs
- cost_metrics: Aggregates financial impact data
This example represents the core structure for collecting data related to cloud costs and resource usage. The compute usage, storage metrics, and network metrics are essential for tracking anomalies.
Within the technical foundation, the detection methodologies play a pivotal role. These are the algorithms and models that determine whether a given cost pattern qualifies as an anomaly. Let’s explore the most common approaches used in cloud cost anomaly detection.
Detection Methodologies
Algorithm Selection Criteria
When selecting an anomaly detection algorithm, various factors need to be considered:
- Data Characteristics:
- The volume of data, velocity (real-time or batch), and pattern complexity all affect the algorithm's performance.
- Certain cost patterns may be seasonal, requiring algorithms that can adjust accordingly.
- Performance Requirements:
- Detection latency: How quickly can anomalies be detected after they occur?
- Computational resources: Does the algorithm require significant processing power or memory?
- Scalability needs: Can the algorithm scale with increasing data volumes?
Statistical Analysis Framework
One simple approach to anomaly detection is based on statistical methods. Below is an example of a Statistical Detector class using the Z-score method to detect anomalies:
| class StatisticalDetector: def __init__(self, baseline_period=30): self.baseline_period = baseline_period self.threshold_multiplier = 3 def calculate_baseline(self, historical_data): return { 'mean': np.mean(historical_data), 'std_dev': np.std(historical_data), 'percentiles': np.percentile(historical_data, [25, 75, 95]) } def detect_anomalies(self, current_data, baseline): z_score = (current_data - baseline['mean']) / baseline['std_dev'] return abs(z_score) > self.threshold_multiplier |
The Z-score method uses historical data to establish a baseline of normal activity. Any deviations from this baseline, beyond a set threshold, are flagged as anomalies.
Machine Learning Implementation
For more advanced detection methods, machine learning algorithms are employed. Here’s an example of how time series forecasting using Facebook Prophet can be used for cost anomaly detection:
Advanced detection using time series analysis:
| class MLAnomalyDetector: def __init__(self): self.model = Prophet( yearly_seasonality=True, weekly_seasonality=True, daily_seasonality=True, interval_width=0.95 ) def train_model(self, historical_data): self.model.fit(historical_data) def predict_costs(self, forecast_period): future_dates = self.model.make_future_dataframe( periods=forecast_period, freq='H' ) return self.model.predict(future_dates) |
Machine learning-based detectors are highly effective in identifying more complex patterns, including seasonal spikes or gradual cost inflation, which can be challenging for statistical methods alone to identify.
Avoiding False Positives in Cost Anomaly Detection
In any cost anomaly detection system, false positives can lead to unnecessary alerts, wasted efforts, and potentially misguided corrective actions. To ensure accurate and meaningful anomaly detection, it’s essential to minimize false positives. Below are key considerations and strategies to avoid them:
Fine-Tune Sensitivity Levels
Different resources have different usage patterns. Ensure that anomaly detection sensitivity levels are customized for specific services like compute, storage, and network. Setting overly sensitive thresholds can flag normal usage as anomalous.
| "sensitivity_levels": { "compute": 0.8, "storage": 0.7, "network": 0.9 } |
Review historical data to establish realistic thresholds that accommodate natural fluctuations in usage while still detecting true anomalies.
Understand Normal Usage Patterns
Incorporate baseline data that accounts for seasonality, time-of-day usage spikes, and planned increases in resource usage, such as during product launches or marketing campaigns. By understanding what constitutes normal variability, you can reduce the likelihood of normal behaviors being flagged as anomalies.
Regularly Update Baseline Models
Cloud usage can evolve rapidly due to changing business needs. Regularly update your baseline models to reflect the current state of resource utilization, avoiding the trap of outdated models generating false positives when your architecture or usage patterns change.
| def update_baseline(self, new_data): # Code to update baseline model with fresh data |
Use Multiple Detection Methods
Combining statistical methods with machine learning models can improve detection accuracy. A hybrid approach helps cross-validate anomalies, ensuring that they are genuine rather than one-off statistical outliers.
Consider Business Context
Not every cost spike is an anomaly. In cases where new services are being introduced, or during expected traffic spikes, factor in business context to prevent legitimate increases in spending from triggering alerts.
Set Minimum Data Points for Anomalies
Establish a minimum data threshold before flagging an anomaly. Detecting an anomaly based on insufficient data can increase false positives. For example, requiring at least a full billing cycle’s worth of data (e.g., 30 days) ensures a more reliable analysis.
| "minimum_data_points": 720, # Number of hourly data points required |
Monitor and Adjust Post-Detection
Post-detection monitoring allows you to manually review flagged anomalies before taking automated action. Review any false positive alerts and adjust detection parameters as necessary to prevent recurring issues.
By implementing these strategies, you can significantly reduce false positives and improve the overall reliability of your cost anomaly detection system, allowing your team to focus on genuine issues that require attention.
Implementation Architecture
An effective cloud cost anomaly detection system requires a well-structured architecture.
- Data Collection: Leverage cloud APIs (like AWS CloudWatch or GCP Monitoring) to collect real-time data.
- ETL (Extract, Transform, Load) Process: Perform necessary transformations on collected data to make it suitable for anomaly detection algorithms.
- Data Storage: Use time series databases (like InfluxDB) to store and retrieve historical cost data.
- Anomaly Detection: Implement detection models, either statistical or machine learning-based, that operate on this data.
- Alerting and Automation: Use tools like PagerDuty or OpsGenie to notify relevant teams when an anomaly is detected. Automated workflows using AWS Lambda or Azure Functions can also be deployed to take corrective actions (e.g., scaling down an underutilized resource).
Implementation Recommendations
Phase 1: Foundation
- Establish baseline monitoring
- Implement basic alerting
- Define response protocols
Phase 2: Enhancement
- Deploy advanced detection algorithms
- Implement automated responses
- Establish continuous improvement processes
Phase 3: Optimization
- Refine detection accuracy
- Enhance response automation
- Implement predictive capabilities
Best Practices for Implementation
- Data Management
- Implement comprehensive data collection protocols
- Establish data retention policies
- Ensure data quality validation
- Detection Configuration
| { "detection_config": { "baseline_period": "30_days", "sensitivity_levels": { "compute": 0.8, "storage": 0.7, "network": 0.9 }, "minimum_data_points": 720, "update_frequency": "hourly" } } } |
- Response Automation
| class ResponseAutomation: def __init__(self): self.response_actions = { 'resource_shutdown': self.shutdown_unused_resources, 'scaling_adjustment': self.adjust_scaling_policies, 'notification': self.send_notifications } def execute_response(self, anomaly_type, context): if anomaly_type in self.response_actions: return self.response_actions[anomaly_type](context) |
Advanced Considerations
- Multi-Cloud Environment Management
| class MultiCloudManager: def __init__(self): self.providers = { 'aws': AWSCostManager(), 'azure': AzureCostManager(), 'gcp': GCPCostManager() } def normalize_costs(self, provider, cost_data): return self.providers[provider].normalize(cost_data) def aggregate_costs(self, timeframe): return { provider: self.providers[provider].get_costs(timeframe) for provider in self.providers } |
Performance Optimization
Strategies for maintaining system efficiency:
- Data Processing
- Implement efficient data storage mechanisms
- Optimize query patterns
- Utilize appropriate indexing strategies
- Analysis Optimization
- Parallel processing for large datasets
- Caching of frequent calculations
- Efficient algorithm implementation
- Data Processing
While current systems can effectively detect and manage cost anomalies, the future promises even more advanced tools and techniques. Emerging technologies such as predictive analytics, deep learning, and improved integration capabilities are set to revolutionize cloud cost management.
Future Developments
Emerging Technologies
- Advanced Analytics
- Deep learning models for pattern recognition
- Predictive analytics for cost forecasting
- Automated root cause analysis
- Integration Capabilities
- Enhanced API connectivity
- Improved cross-platform compatibility
- Standardized reporting frameworks
Effective cloud cost anomaly detection requires a systematic approach combining robust technical implementation with well-defined operational procedures. Success depends on careful consideration of system architecture, appropriate technology selection, and ongoing optimization efforts.






