

In today's digital world, data is no longer just a byproduct of business activities—it is the most valuable asset organizations have. Every day, businesses generate an enormous amount of data—around 2.5 quintillion bytes! While this data holds immense potential, managing it effectively is a major challenge.
The Challenges of Data Growth
Traditional storage solutions struggle to keep up with modern demands because of:
- Explosive Data Growth: More data is being created every second, requiring highly scalable storage solutions.
- Complex Data Sources: Businesses use structured data (like databases), semi-structured data (like JSON), and unstructured data (like videos and emails).
- Real-Time Analytics: Companies need insights instantly, not hours or days later.
- Strict Security and Compliance Requirements: Businesses must follow rules like GDPR, HIPAA, and PCI DSS to protect sensitive data.
Azure Data Lake: The All-in-One Solution
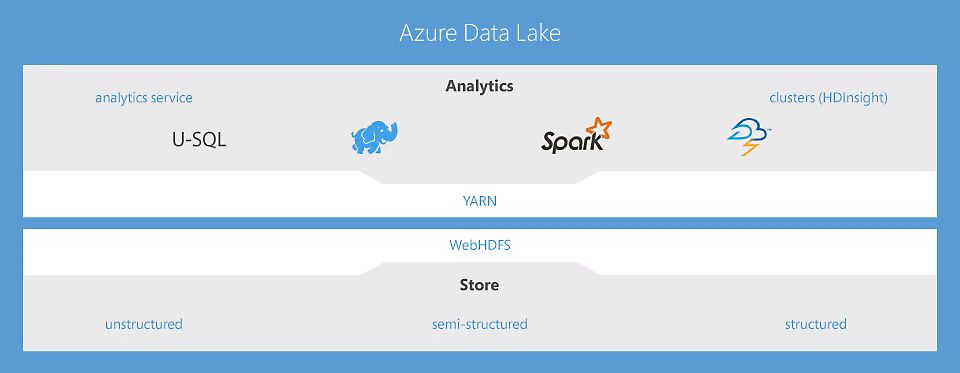
Source - Azure
Microsoft Azure Data Lake is more than just a cloud storage service—it’s a comprehensive data management platform designed to handle vast amounts of structured and unstructured data. It helps businesses store, analyze, and secure massive amounts of data efficiently.
Whether you’re dealing with real-time analytics, AI/ML workloads, IoT data, or enterprise reporting, Azure Data Lake offers the flexibility and power to meet modern data needs. But like any evolving technology, it has improved over time. Let’s explore how it has evolved from its first generation to its current, more advanced form.
Evolution of Azure Data Lake Storage
Azure Data Lake Storage Gen1: The Foundation
Azure Data Lake Storage Generation 1 (Gen1) was Microsoft’s first attempt at creating a cloud-native, big data storage solution tailored for advanced analytics. It was designed primarily for handling large-scale analytical workloads and worked well with the Apache Hadoop ecosystem.
Key Features of Gen1:
- Built specifically for big data analytics, it is ideal for large-scale workloads.
- Supported unlimited storage, allowing enterprises to store vast amounts of data without capacity concerns.
- Optimized for parallel processing using distributed computing frameworks like Apache Spark and Hadoop.
- Integrated with Azure’s big data and machine learning services, making it easy to run complex data processing jobs.
However, Gen1 had limitations—it was mainly optimized for analytics rather than general-purpose cloud storage. It lacked some of the advanced security, scalability, and cost-efficiency features that businesses demanded as cloud storage needs evolved.
Azure Data Lake Storage Gen2: A Major Leap Forward
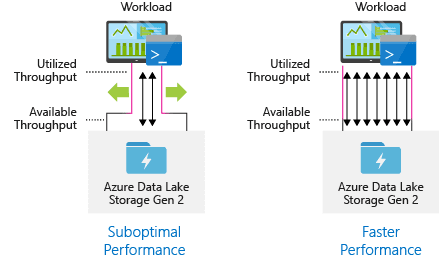
Source - Azure
To address the shortcomings of Gen1, Microsoft introduced Azure Data Lake Storage Gen2, which combined the strengths of Azure Blob Storage with the capabilities of a hierarchical file system. This made Gen2 faster, more scalable, and cost-efficient, making it an ideal solution for both big data analytics and general-purpose cloud storage.
Key Advancements in Gen2:
- Hierarchical Namespace (HNS): Unlike flat object storage in Gen1, Gen2 introduced folder structures similar to traditional file systems, improving file management, query performance, and metadata handling.
- Seamless Integration with Azure Blob Storage: This allowed businesses to store and manage all types of data (structured, semi-structured, and unstructured) within a unified storage platform.
- Better Performance & Cost Efficiency: Lower transaction costs, improved data processing speeds, and optimized storage pricing make Gen2 more affordable and scalable than Gen1.
- Advanced Security Features: Gen2 supports Access Control Lists (ACLs) and Role-Based Access Control (RBAC), allowing for fine-grained security policies at the file and folder level.
- Scalability for Enterprise Workloads: It is designed to handle petabyte-scale storage efficiently, making it a strong choice for enterprises dealing with large datasets.
With these enhancements, Gen2 is now the standard for modern cloud storage on Azure, providing a unified, high-performance, and secure platform for enterprises and data-intensive applications.
Core Architecture of Azure Data Lake
Azure Data Lake is designed to handle massive volumes of structured, semi-structured, and unstructured data. Understanding its architecture helps businesses leverage its full potential.
How Azure Data Lake is Structured?
Azure Data Lake consists of:
- Storage Layer – Azure Data Lake Storage (ADLS) serves as the backbone for data storage.
- Processing Layer – Tools like Azure Databricks and Azure Synapse Analytics process and analyze the data.
- Security & Governance Layer – Access controls, encryption, and compliance mechanisms protect data.
Understanding Hierarchical Namespace and Blob Storage Integration
- Hierarchical Namespace (HNS) allows directory and file structures, improving data organization and query performance.
- Unlike traditional flat Blob Storage, HNS supports directory-level security, fast lookups, and efficient metadata operations.
- ADLS Gen2 inherits features from Azure Blob Storage, making it highly scalable and secure.
Role of Data Lake Filesystem (ADLS Gen2)
- ADLS Gen2 is built on Azure Blob Storage, but with file system capabilities.
- It allows fine-grained access control (ACLs) and POSIX-style permissions.
- Supports massive-scale analytics with tools like Azure Synapse, Databricks, and Hadoop-based frameworks.
Key Features of Azure Data Lake
Azure Data Lake is designed to handle vast amounts of data with high performance, security, and cost efficiency. Whether your organization is dealing with structured databases, unstructured media files, or semi-structured logs and JSON data, Azure Data Lake provides the scalability and tools needed to store, manage, and analyze data effectively.
Scalability and High Performance
One of Azure Data Lake’s biggest strengths is its ability to store and process petabytes of data without performance degradation. As data grows, businesses can seamlessly scale their storage needs without worrying about speed or accessibility.
- Massive Data Storage Capacity – Handles structured (databases), semi-structured (JSON, CSV), and unstructured data (videos, logs, images, IoT data) in a unified platform.
- Parallel Processing for Fast Insights – Supports distributed computing frameworks like Apache Spark, Hadoop, and Azure Synapse to speed up large-scale data processing.
- Optimized for Big Data Workloads – Works efficiently with AI/ML, real-time analytics, and data lakes used in finance, healthcare, retail, and IoT.
- Elastic Scaling – Grows or shrinks as per business needs, ensuring that enterprises only use the storage they need at any given time.
Strong Security and Compliance Framework
With data security and privacy regulations becoming more stringent, Azure Data Lake is built with enterprise-grade security to protect sensitive information from unauthorized access and cyber threats.
- Data Encryption – Ensures security both at rest and in transit using AES-256 encryption and TLS protocols.
- Role-Based Access Control (RBAC) – Defines user permissions and ensures only authorized users can access, modify, or delete data.
- Azure Active Directory (AAD) Integration – Provides secure authentication, single sign-on (SSO), and multi-factor authentication (MFA) for enhanced protection.
- Granular Access Management – Uses Access Control Lists (ACLs) to provide fine-grained control over who can view or edit specific files and folders.
- Comprehensive Audit Logging – Tracks all data access and modifications for better compliance monitoring and governance.
- Regulatory Compliance – Meets global security and compliance standards such as GDPR, HIPAA, PCI DSS, and ISO 27001.
Cost-Efficient Data Management
Unlike traditional storage solutions, Azure Data Lake offers smart cost-saving options that help businesses optimize expenses without sacrificing performance.
- Tiered Storage – Automatically moves less frequently accessed data to lower-cost storage tiers.
- Lifecycle Management – Allows organizations to set rules for deleting or archiving old data, and optimizing storage usage.
- Pay-as-You-Go Pricing – Businesses only pay for the storage and compute resources they actually use.
- Cold and Archive Storage – Provides cost-effective options for storing infrequently accessed data at significantly lower prices.
- Predictive Cost Analytics – Helps organizations estimate and plan their storage costs based on usage patterns and future needs.
Seamless Integration with Azure Ecosystem
Azure Data Lake does not operate in isolation—it integrates with a wide range of Azure services to enhance data processing, analytics, and machine learning capabilities.
- Azure Synapse Analytics – Enables powerful querying and analytics across massive datasets.
- Azure Databricks – Provides a collaborative workspace for big data and AI-driven analytics.
- Power BI – Helps businesses create interactive reports and dashboards using data stored in Azure Data Lake.
- Azure Machine Learning – Supports advanced AI and ML workloads for predictive analytics and automation.
- IoT and Streaming Data Support – Works seamlessly with Azure IoT Hub and Azure Stream Analytics for real-time data ingestion and analysis.
Data Ingestion and Processing in Azure Data Lake
Azure Data Lake supports various ingestion methods to bring data from different sources, whether in real-time or batch mode.
How Data is Ingested, Transformed, and Processed?
When you work with data in Azure Data Lake, the journey begins with ingestion. This is where data enters the platform, often from a variety of sources—anything from on-premises databases to cloud applications, IoT devices, and APIs. At this stage, the data is typically in its raw, unprocessed form.
Once the data has entered the lake, the next steps are cleansing, transformation, and enrichment. Data cleansing involves filtering out errors and inconsistencies, ensuring that you only have accurate, usable information in your system. Transformation comes next—this is where data is reshaped or restructured according to business rules, so it’s in the right format for analytics or other uses. Finally, enrichment can bring in additional context from other sources, further improving the quality and usability of the data.
After the data has been cleaned, transformed, and enriched, it is then indexed and stored in a way that makes it easy to query and analyze later on. Whether for reporting, machine learning models, or business intelligence, this well-prepared data is ready to fuel your organization’s insights.
Common Tools for Data Ingestion
Azure offers several tools designed to help you manage data ingestion, each suited for different types of data flows.
- For instance, Azure Data Factory (ADF) plays a key role in orchestrating the movement of data across different environments—whether that’s from on-premises to the cloud or between various cloud platforms. ADF allows for seamless automation of data pipelines, saving time and reducing manual intervention.
- Then there are Azure Event Hubs and IoT Hub, both of which specialize in real-time data ingestion. These services are ideal when you’re dealing with streaming data—whether from sensors, logs, or live applications. Apache Kafka can also be leveraged for high-volume, real-time data streams, making it a solid option when you're working with large numbers of data sources producing continuous data flows.
These tools are incredibly flexible, enabling you to design an ingestion pipeline that works best for your specific needs, whether you're working with real-time events or batch processing.
Batch vs. Real-Time Data Processing
When dealing with data in Azure Data Lake, one of the primary decisions is whether to process your data in batch mode or real-time. Each approach has its advantages and is suited to different use cases.
Batch Data Processing
Batch processing involves handling large volumes of data at scheduled intervals—usually during off-peak hours. This method efficiently deals with massive datasets where immediate insights aren’t necessary. For example, you might use batch processing to generate daily reports or process weekly sales data. The primary benefit is that it’s highly efficient for large data uploads, but it doesn’t provide instant access to insights.
Real-Time Data Processing
On the other hand, real-time data processing is designed to deliver insights immediately, as data is ingested into the system. This is crucial for scenarios that require instant decision-making, such as fraud detection in financial transactions or monitoring sensor data for equipment failures. The processing happens as the data streams in, enabling near-instant responses to changes.
Here’s a table that further clarifies the differences between batch and real-time processing:
| Metric | Batch Data Processing | Real-Time Data Processing |
| Data Volume | Can handle petabytes of data in a single job (up to 5 PB per batch) | Typically handles GB to TB of data per second |
| Processing Speed | Processing can take hours (e.g., 6-12 hours) depending on data size | Processing happens in milliseconds to seconds (< 1-second latency) |
| Data Latency | Data is processed at scheduled intervals (e.g., daily/weekly) | Data is processed immediately as it arrives (real-time) |
| Cost Efficiency | More cost-effective for large volumes of historical data that don’t require immediate action | More expensive due to the need for faster processing and infrastructure, but critical for real-time insights |
| Use Case Examples | Monthly sales data, historical financial reports, log aggregation | Fraud detection, live sensor data analysis, financial transactions |
ETL vs. ELT Pipelines in Azure Data Lake
The choice between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) pipelines depends on the structure of your data and how you plan to process it in Azure Data Lake.
ETL Pipelines
In the ETL approach, data is first extracted from its source, then transformed into a desired format, and finally loaded into the data lake. This model works best when the data needs to be cleaned, validated, and reshaped before being stored. It’s a traditional method that ensures only structured, processed data enters the lake. However, it can slow down the data pipeline because of the transformations that happen before loading.
ELT Pipelines
In contrast, ELT loads raw data directly into the lake before performing any transformations. Once the data is in the lake, you can apply transformations based on business needs. The ELT model is becoming more popular as it allows for more flexibility in handling data after it’s been stored. With Azure’s powerful compute capabilities (like Azure Synapse or Databricks), this approach can be faster and more efficient, especially when dealing with large datasets.
Here’s a table that outlines the key differences between ETL and ELT pipelines:
| Metric | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
| Data Processing Time | Typically slower because transformations happen before loading (up to several hours for complex transformations) | Faster as data is loaded first, and transformations occur later (typically minutes) |
| Data Storage | Data stored is already structured and transformed (less storage space required) | Raw data is stored and transformed later (requires more storage space initially) |
| Cost of Storage | Generally lower as only transformed data is stored | Higher initial storage costs due to raw data storage, but cost-effective long-term |
| Scalability | Can be challenging with very large datasets (e.g., 10-50 TB) without proper optimization | Highly scalable for large volumes of data (up to petabytes) |
| Time to Insight | Slower, due to upfront data transformation and cleansing (up to 1-2 days) | Faster, with insights available shortly after loading the raw data (within hours) |
| Example Use Case | Data warehouses with highly structured data (e.g., customer profiles, order histories) | Big Data environments or scenarios requiring flexibility (e.g., IoT sensor data, social media streams) |
Industry-Specific Use Cases
Azure Data Lake is widely used across industries to store, process, and analyze vast amounts of data efficiently. From real-time analytics to AI-driven insights, organizations leverage its capabilities to enhance operations, improve decision-making, and drive innovation.
Financial Services
The financial industry deals with high volumes of transactions that require real-time processing, stringent security, and regulatory compliance. Azure Data Lake enables:
- Real-time fraud detection – Analyzing transaction patterns to identify fraudulent activities instantly.
- Regulatory compliance reporting – Storing and processing financial records in accordance with global regulations (GDPR, SOX, PCI DSS).
- Risk analysis and modeling – Running complex risk assessments and predictive models on large datasets.
- High-speed trading analytics – Processing stock market data in real-time to identify trading opportunities and risks.
Healthcare and Life Sciences
With vast amounts of sensitive medical data, the healthcare industry requires secure, scalable, and compliant storage solutions. Azure Data Lake supports:
- Genomic research and drug discovery – Storing and analyzing massive genomic datasets for precision medicine.
- Electronic Health Records (EHR) management – Securely managing and retrieving patient records.
- Clinical trial data analysis – Aggregating and analyzing multi-source data for medical research.
- AI-driven predictive healthcare models – Identifying disease patterns and recommending preventive care.
Manufacturing and IoT (Internet of Things)
Manufacturers and industrial enterprises leverage IoT-driven analytics to optimize operations and reduce downtime. Azure Data Lake helps with:
- Predictive maintenance – Analyzing sensor data from industrial equipment to predict failures before they occur.
- Real-time supply chain optimization – Improving logistics and inventory tracking using big data insights.
- IoT-enabled machinery monitoring – Capturing and processing real-time data from factory equipment to enhance efficiency.
- Quality control analytics – Using AI and data analytics to detect defects and improve production standards.
Data Access and Querying
Once data resides in Azure Data Lake, the focus shifts to efficient access and analysis. Microsoft provides several powerful tools for querying data, each with distinct advantages for different analytical scenarios.
Azure Synapse Analytics
Excels at running large-scale analytical queries across massive datasets. Its MPP (Massively Parallel Processing) architecture distributes query processing across multiple nodes, delivering exceptional performance for complex analytical workloads. Synapse integrates SQL and Spark engines, providing flexibility to work with both structured and unstructured data.
Azure Databricks
It creates an ideal environment for AI/ML-driven data exploration and predictive analytics. Built on Apache Spark, Databricks offers a collaborative notebook experience where data scientists can develop and deploy sophisticated machine learning models directly against data lake content.
Azure Data Explorer
Specializes in real-time telemetry and log analytics, making it perfect for IoT applications, system monitoring, and user behavior analysis. Its unique query language delivers lightning-fast analytics on streaming data, enabling real-time dashboards and alerts.
When working with Azure Data Lake, organizations can choose between two fundamental querying approaches:
- File-based querying works directly with data in raw formats like Parquet, JSON, or CSV using services like Synapse or Spark. This approach offers flexibility and works well with unstructured or semi-structured data.
- Table-based querying loads data into SQL-like tables, providing faster lookups and more familiar query patterns for users with SQL backgrounds. This approach excels at structured data analysis where performance is critical.
For organizations seeking enhanced query performance and data reliability, Delta Lake represents a significant advancement. Built on Apache Spark, Delta Lake adds crucial enterprise features to data lakes, including ACID transactions that ensure data consistency, schema enforcement that prevents data quality issues, and versioning that enables historical data analysis.
Delta Lake's time travel capabilities allow analysts to query historical versions of data—a powerful feature for compliance, audit, and trend analysis. Additionally, its auto-optimization features continuously tune data layout and indexing, resulting in progressively faster queries over time.
Cost Comparison and ROI
One of the biggest concerns for organizations considering Azure Data Lake is the cost-effectiveness of the solution. This section breaks down cost considerations, comparisons, and the expected return on investment (ROI).
Cost Components of Azure Data Lake
Azure Data Lake's pricing structure encompasses several key elements:
- Storage Costs:
- Hot Tier: Approximately $0.018 per GB per month.
- Cool Tier: Approximately $0.01 per GB per month.
- Archive Tier: Approximately $0.002 per GB per month.
These tiers allow organizations to optimize costs based on data access frequency.
- Transaction Costs:
- Write Operations: Range from $0.0228 per 10,000 operations for the Premium Tier to $0.13 per 10,000 operations for the Archive Tier.
- Read Operations: Range from $0.00182 per 10,000 operations for the Premium Tier to $6.50 per 10,000 operations for the Archive Tier
These costs vary depending on the storage tier and the nature of the operations performed.
Processing Costs:
Azure Synapse Analytics: Compute resources are billed at approximately $0.883 per hour for 100 Data Warehousing Units (DWUs). Storage is billed at approximately $23 per TB per month.
These costs are incurred when performing data processing and analytics tasks.
- Data Movement Costs:
- Ingress (Data In): Free of charge
- Egress (Data Out): The first 100 GB per month is free; beyond this, charges start at approximately $0.08 per GB, decreasing with higher usage volumes
Understanding these costs is essential for budgeting data transfer expenses.
| Cost Component | Service / Tier | Pricing Estimate |
Storage
| Hot Tier | ~$0.018 per GB / month |
| Cool Tier | ~$0.01 per GB / month | |
| Archive Tier | ~$0.002 per GB / month | |
| Write Operations | Premium Tier | ~$0.0228 per 10,000 writes |
| Archive Tier | ~$0.13 per 10,000 writes | |
| Read Operations | Premium Tier | ~$0.00182 per 10,000 reads |
| Archive Tier | ~$6.50 per 10,000 reads | |
Processing | Azure Synapse Analytics (Compute) | ~$0.883 per hour for 100 DWUs |
| Synapse Storage | ~$23 per TB / month | |
| Data Ingress | All Tiers | Free |
| Data Egress | First 100 GB / month | Free |
| After 100 GB | ~$0.08 per GB (decreasing with higher usage) |
Calculating ROI: How Azure Data Lake Saves Costs
Organizations that implement Azure Data Lake typically realize substantial cost benefits through several mechanisms:
- Storage optimization through tiered pricing and efficient compression formats significantly reduces raw storage costs compared to traditional approaches. Organizations can save 30-60% on storage expenses by implementing appropriate lifecycle policies and format optimization.
- Infrastructure consolidation eliminates the need for expensive on-premises hardware, reducing capital expenditures and ongoing maintenance costs. This shift from capital to operational expenses improves financial flexibility and reduces risk.
- Analytical acceleration delivers faster insights that drive better business decisions and improved operational efficiency. While harder to quantify, these benefits often represent the most significant source of ROI from data lake implementations.
- Operational automation through Azure's managed services reduces administrative overhead and allows IT staff to focus on higher-value activities rather than routine maintenance tasks.
By carefully mapping these cost factors against business outcomes, organizations can develop a comprehensive ROI model that demonstrates the compelling value proposition of Azure Data Lake. Most enterprises find that the platform not only reduces direct IT costs but also creates new revenue opportunities through enhanced data utilization and analytical capabilities.
Getting Started with Azure Data Lake
For those eager to start using Azure Data Lake, here’s a quick step-by-step guide to setting up and configuring the platform for immediate use.
Step 1: Set Up an Azure Data Lake Storage Account
- Sign in to Azure Portal.
- Navigate to Storage Accounts and click Create.
- Select Azure Data Lake Storage Gen2 as the account type.
- Choose the desired region, redundancy, and performance tier.
- Click Review + Create to deploy the storage account.
Step 2: Configure Access and Security
- Enable Hierarchical Namespace (HNS) for efficient data management.
- Set up Role-Based Access Control (RBAC) and Access Control Lists (ACLs) to define user permissions.
- Implement encryption (at rest and in transit) for data security.
Step 3: Ingest Data into Azure Data Lake
- Use Azure Data Factory for structured data pipelines.
- Stream real-time data via Event Hubs or IoT Hub.
- Migrate large datasets from on-premises using Azure Data Box.
Step 4: Process and Query Data
- Use Azure Synapse Analytics for running large-scale queries.
- Deploy Databricks for advanced machine learning and AI workloads.
- Utilize Azure Data Explorer for fast, interactive log analysis.
Step 5: Monitor and Optimize Performance
- Enable Azure Monitor for real-time insights.
- Configure alerts and diagnostics logs to track potential issues.
- Implement storage tiering to manage costs efficiently.
By following these steps, users can quickly start leveraging Azure Data Lake’s full potential without an overwhelming learning curve.
Best Practices for Implementing Azure Data Lake
Implementing Azure Data Lake effectively requires careful planning, governance, and optimization to ensure scalability, security, and high performance. Below are some key best practices to follow for a smooth and efficient deployment.
Establish a Robust Data Governance Strategy
A well-defined data governance strategy ensures that data is organized, secure, and compliant with industry regulations.
- Classify data properly for better organization – Categorize data based on its type, sensitivity, and usage (e.g., structured, semi-structured, unstructured). This makes it easier to manage and enforce security policies.
- Use metadata management to track data details – Implement Azure Data Catalog to maintain metadata, such as file origins, descriptions, and business terms, to improve discoverability and usability.
- Set up data lineage tracking to monitor data movement – Utilize Azure Purview to trace data flow across pipelines, ensuring transparency and compliance.
- Automate data quality checks to maintain accuracy – Leverage Azure Data Factory or Azure Databricks to implement data validation, deduplication, and anomaly detection before data ingestion.
- Implement scalable access control policies – Use Role-Based Access Control (RBAC) and Access Control Lists (ACLs) to ensure that only authorized users can access specific datasets, reducing security risks.
Performance Optimization Techniques
Optimizing Azure Data Lake for speed, efficiency, and cost-effectiveness ensures that queries and workloads run smoothly.
- Use partitioning strategies to speed up queries – Partition large datasets based on time-based, categorical, or hierarchical structures. For example, storing logs by year/month/day makes querying specific time ranges significantly faster.
- Implement data compression for efficient storage – Use Parquet and ORC formats instead of CSV or JSON to reduce storage costs and improve query performance. These formats support columnar storage and better compression rates.
- Optimize file sizes to improve parallel processing – Instead of storing too many small files (which slows down processing), combine small files into larger, optimal-sized files (between 256MB to 1GB per file) to improve parallelism.
- Leverage caching mechanisms to enhance performance – Use Azure Synapse Analytics caching or Databricks Delta caching to store frequently accessed data in memory for faster retrieval.
- Regularly monitor and fine-tune query execution – Utilize Azure Monitor and Log Analytics to analyze query performance, identify bottlenecks, and fine-tune execution plans.
Cost Management Best Practices
To keep costs under control while maintaining performance, businesses should adopt smart storage and processing strategies.
- Use tiered storage to optimize costs – Store frequently accessed data in hot storage and move infrequently used data to cool or archive tiers to reduce expenses.
- Implement lifecycle policies – Automate data deletion, archiving, or migration based on retention policies using Azure Storage Lifecycle Management.
- Monitor storage costs in real time – Enable Azure Cost Management to track spending patterns and optimize resource allocation.
Security and Compliance Considerations
Ensuring data security and regulatory compliance is critical for businesses handling sensitive data.
- Enable encryption by default – Use AES-256 encryption for data at rest and TLS for data in transit to protect sensitive information.
- Implement data masking and tokenization – Use Azure SQL Data Masking to obfuscate sensitive data, ensuring compliance with regulations like GDPR and HIPAA.
- Perform regular security audits – Conduct periodic access reviews, penetration testing, and compliance checks using Azure Security Center.
By following these best practices, businesses can maximize the efficiency, security, and scalability of Azure Data Lake while keeping costs under control. Proper implementation ensures that data remains accessible, well-governed, and optimized for analytics and decision-making.
Common Challenges and Solutions
Organizations often face implementation and operational challenges. Here’s a look at common pain points and how to address them effectively.
Challenge 1: Managing Unstructured and Semi-Structured Data
Problem: Storing vast amounts of raw data often leads to disorganization, making data discovery and retrieval difficult.
Solution:
- Implement Hierarchical Namespace (HNS) for structured organization.
- Use metadata tagging and indexing for better searchability.
- Adopt Delta Lake for schema enforcement and version control.
Challenge 2: Slow Query Performance on Large Datasets
Problem: As data volume grows, query execution can slow down.
Solution:
- Optimize data storage by using Parquet or ORC formats.
- Partition data by date, region, or category to improve access times.
- Implement Azure Synapse caching and Databricks Delta caching.
Challenge 3: Ensuring Data Security and Compliance
Problem: Sensitive data must be protected while adhering to global regulations.
Solution:
- Enforce RBAC and ACLs for fine-grained access control.
- Enable encryption at rest and in transit to prevent unauthorized access.
- Use Azure Purview for data governance and regulatory compliance.
Challenge 4: Cost Management and Budget Control
Problem: Without proper cost monitoring, storage expenses can escalate quickly.
Solution:
- Enable Lifecycle Management to move infrequently accessed data to cool and archive tiers.
- Monitor real-time costs with Azure Cost Management.
- Use pay-as-you-go pricing and reserved storage options for long-term savings.
Addressing these challenges early ensures a smooth, cost-effective, and high-performance Azure Data Lake implementation.
Monitoring, Logging, and Troubleshooting
To keep your Azure Data Lake environment performing at its best, you need more than just solid infrastructure—you need visibility, insight, and the ability to act fast when things go wrong. Microsoft offers a powerful set of tools to help you stay ahead of performance issues and ensure smooth, reliable operations.
Azure Monitor is your go-to for real-time visibility. It tracks key metrics like storage usage, data throughput, and system latency. This data helps you spot trends early—such as growing workloads or emerging bottlenecks—so you can take proactive steps before users feel the impact.
Alongside it, Log Analytics dives deeper into what’s happening under the hood. If a query fails or performance dips, the detailed execution logs can help pinpoint exactly where things went wrong. Whether it's a syntax error, resource contention, or unexpected data patterns, having this level of detail speeds up resolution and reduces downtime.
It’s important to configure alerts for high-priority events. That means getting notified if your storage nears capacity, a critical query fails, or a security anomaly is detected. With alerts in place, your team can act immediately instead of discovering issues after the fact.
Turning on diagnostic logging adds another layer of protection. These logs capture a complete trail of system behavior and errors, making them a goldmine for investigating complex or intermittent issues that aren't easy to replicate.
When performance lags, a few targeted strategies can make a big difference:
- Optimizing partitioning helps large datasets stay manageable by reducing how much data needs to be scanned for each query. Reviewing how your data is divided can lead to major speed improvements.
- Switching file formats—for example, moving from CSV or JSON to Parquet or ORC—can significantly boost performance, especially for analytical workloads that process large volumes of data.
- Analyzing query performance reveals where slowdowns are happening. From rewriting inefficient queries to creating materialized views or applying better indexing strategies, small changes can have a big impact.
With the right tools and a proactive approach, keeping your Azure Data Lake environment optimized becomes less about reacting to problems and more about building a system that runs smoothly and scales confidently.
The Future of Azure Data Lake
Technology is evolving, and so is Azure Data Lake. Expect to see:
- AI and Machine Learning Integration for smarter insights.
- Edge Computing Capabilities for real-time data processing at the source.
- Enhanced Real-Time Analytics to get instant business intelligence.
- Improved Cross-Cloud Data Mobility for seamless movement between cloud providers.
- Stronger Security and Compliance Features for even better data protection.
Azure Data Lake is more than just a storage solution—it’s a game-changer for enterprise data management. With its scalability, security, cost efficiency, and integration with powerful analytics tools, it enables organizations to unlock the true value of their data.
Next Steps
- Assess your data needs and challenges.
- Explore Azure Data Lake’s features and pricing models.
- Plan an implementation strategy that aligns with your business goals.
- Work with Azure experts or consultants to deploy the best solution.
- Continuously optimize performance and security to stay ahead.
By leveraging Azure Data Lake, businesses can not only store data efficiently but also extract meaningful insights that drive success in today’s data-driven world.






