
In an era where data drives decisions, choosing the right platform is crucial to maintaining a competitive edge. Traditional data solutions, however, often struggle to meet the demands of modern data operations. As data volumes grow and business requirements become more complex, these platforms face critical limitations in performance, scalability, and integration.
Limitations of Traditional Data Platforms
Traditional data platforms often experience performance bottlenecks, difficulty scaling, and integration challenges. As data complexity grows, these limitations restrict an organization’s ability to gain timely and accurate insights. As organizations try to use their data fully, these problems make it harder to get fast insights and respond quickly to changes in the market. This growing need for more flexible, scalable, and efficient solutions has led to the development of platforms like Snowflake and Databricks, designed to solve these challenges differently.
Founding Goals and Visions
Snowflake: Simplifying Cloud Data Warehousing
Snowflake was founded in 2012 by Benoit Dageville, Thierry Cruanes, and Marcos Desalvo, engineers with decades of experience in database management. Their vision was to overcome the inherent limitations of traditional data platforms and design a solution that was specifically built for the cloud. Traditional data warehouses often struggled with rigid architectures and costly infrastructure that couldn’t scale easily with growing data demands. Snowflake’s founders recognized this gap and aimed to create a platform that provided seamless scalability, ease of use, and the flexibility needed for modern data workloads.
The breakthrough behind Snowflake’s architecture lies in its separation of compute and storage, allowing organizations to scale each independently. This ensures better resource management and cost control, where businesses only pay for the resources they use. Snowflake’s cloud-native design also simplifies data management and enhances performance, making it easier for organizations to run complex queries and manage large datasets without worrying about infrastructure limitations. Snowflake has since become an essential tool for companies looking for a scalable, high-performance data warehousing solution, enabling better analytics and data-driven decision-making.
Databricks: Unifying Data Engineering and AI
Databricks was founded in 2013 by the creators of Apache Spark: Ali Ghodsi, Matei Zaharia, and their colleagues at the University of California (UC) Berkeley. The idea behind Databricks was to unify the traditionally separate worlds of data engineering, analytics, and artificial intelligence (AI) on a single platform. By doing so, they aimed to simplify complex workflows and improve collaboration among teams working with big data.
The platform is built on Apache Spark, which was designed to handle large-scale data processing efficiently. Databricks extended Spark’s capabilities, offering a unified environment for data engineers, scientists, and analysts to work collaboratively. It combined big data processing with advanced analytics, creating a streamlined solution for organizations focused on AI, machine learning, and real-time analytics. This integration helps teams break down silos, build end-to-end pipelines, and deliver actionable insights faster. Databricks has quickly become a go-to platform for businesses looking to leverage big data for advanced AI and machine learning applications.
Purpose of the Comparison
Given the distinct goals behind Snowflake and Databricks, it’s important to evaluate how each platform meets the needs of modern organizations.
The purpose of this comparison is to help organizations navigate the complexities of choosing the right platform for their data operations. With the ever-growing volumes of data, companies need solutions that not only scale but also integrate seamlessly with other systems, ensure data security, and enable real-time insights. This comparison highlights how Snowflake and Databricks approach these challenges differently, offering businesses the tools they need to unlock the full potential of their data.
Overview of Snowflake and Databricks
Snowflake: A Data Warehousing Solution
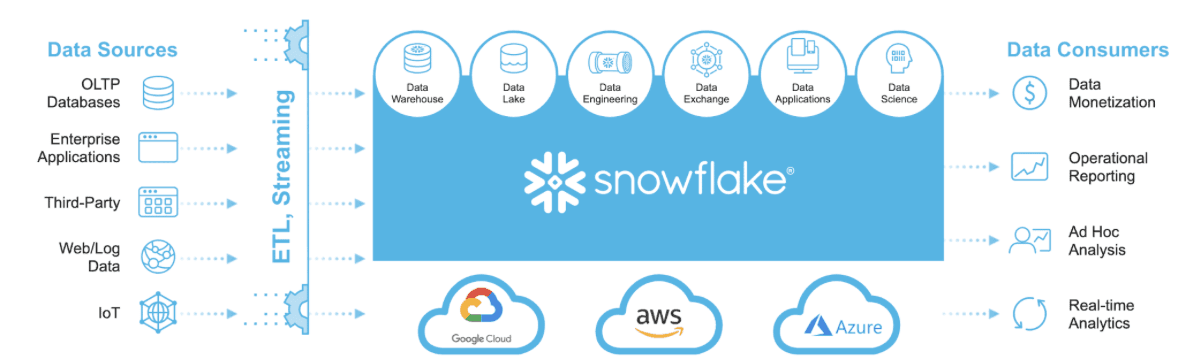
Source - Medium
Snowflake’s architecture is built to support cloud-native data warehousing, offering high scalability and flexibility. Unlike traditional data warehouses, Snowflake separates compute and storage, which allows users to scale each component independently based on their needs. This enables businesses to avoid over-provisioning resources, which can lead to unnecessary costs. The platform’s multi-cluster architecture also ensures consistent performance even when handling massive data workloads, allowing businesses to run complex queries and store large datasets with ease.
Snowflake’s features extend beyond simple data warehousing. It allows for secure data sharing, making it easier for organizations to collaborate across departments or with external partners without compromising on security. Snowflake’s support for semi-structured data (e.g., JSON, XML) and structured data also adds to its versatility, making it a powerful solution for diverse data types and analytical needs.
Databricks: A Unified Data Analytics Platform
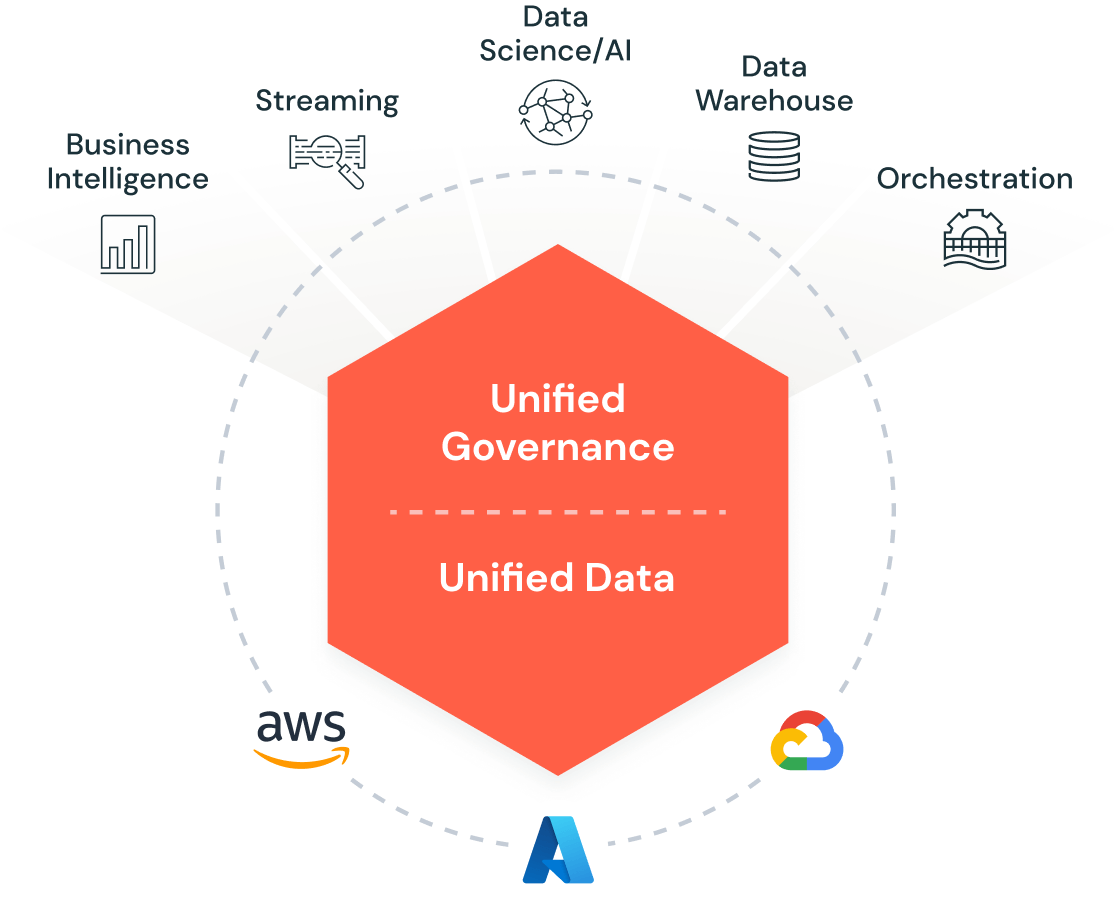
Source - Databricks
In contrast, Databricks offers a unified platform that integrates data engineering, data science, and machine learning. Built on the Apache Spark engine, it is optimized for big data processing and can handle large-scale data operations efficiently. Databricks goes beyond traditional analytics by providing an end-to-end solution that facilitates the creation, training, and deployment of machine learning models, all within a single environment.
The platform also offers strong collaborative features, allowing data engineers, scientists, and analysts to work together in real time on shared projects. This reduces bottlenecks, enhances productivity, and ensures that teams can quickly move from data preparation to model training and deployment. Databricks’ capabilities in real-time analytics and AI-powered insights make it a key player for companies investing in AI-driven solutions and machine learning models.
Key Evaluation Criteria
To provide a comprehensive comparison, the following criteria will be assessed:
- Performance
- Scalability
- Cost Management
- Security and Compliance
- Usability and Integration
Let's dive deeper into each criterion to explore how Snowflake and Databricks perform and where they excel.
Performance Comparison
Performance is a critical factor when selecting a cloud data platform, directly impacting query speed, data processing efficiency, and overall system responsiveness. Let’s explore how Snowflake and Databricks measure up in these areas:
Snowflake Performance
Snowflake is designed to deliver fast query processing and maintain consistent performance, especially in data warehousing scenarios.
- Query Speed:
Snowflake can process large datasets—such as a 10-billion-row table—in under 10 seconds when the virtual warehouse (compute resource) is appropriately sized. This speed is crucial for data warehousing and business intelligence (BI) applications, where rapid query responses translate to timely insights. - Latency:
Snowflake’s latency performance excels with structured and semi-structured data. Simple queries with optimized indexing typically yield results in less than 5 seconds. Caching mechanisms further enhance performance by reducing redundant I/O operations, especially when queries access frequently used data. - Workload Management:
Snowflake's auto-scaling clusters ensure consistent performance during peak usage. Multiple virtual warehouses can run concurrently without interfering with each other, making it ideal for organizations with multiple teams or workloads. For instance:- BI teams can run analytical queries.
- Data engineering teams can load new data.
All without impacting each other's performance
Databricks Performance
Databricks, built on Apache Spark, is optimized for big data processing, making it a robust choice for handling large-scale data transformations and machine learning tasks.
- Processing Speed:
Databricks efficiently process massive datasets—up to 1 petabyte (PB)—using parallel execution. Its distributed computing framework ensures quick processing, even for complex data transformations. - Latency:
For streaming data, Databricks typically maintains a latency of less than 1 second. This low latency is critical for real-time analytics use cases, such as fraud detection or IoT data processing. - Optimization Features:
Databricks includes powerful optimization features like:- Adaptive Query Execution (AQE): Adjusts query plans at runtime, improving efficiency by 20-40%.
- Catalyst Optimizer: Enhances query performance by generating efficient execution plans, ensuring maximum resource utilization.
| Feature | Snowflake | Databricks |
| Query Speed | Processes 10-billion-row datasets in ~10 seconds | Efficiently handles up to 1 PB datasets |
| Latency | <5 seconds for simple queries | <1 second for streaming data |
| Workload Management | Auto-scaling clusters with independent workloads | Horizontal scaling with adaptive resource allocation |
| Optimization Techniques | Query caching, workload isolation | Adaptive Query Execution, Catalyst Optimizer |
Key Takeaways:
- Snowflake: Ideal for structured data and BI applications requiring rapid query responses. Its auto-scaling capabilities ensure consistent performance across multiple workloads.
- Databricks: Best suited for big data processing, real-time streaming, and machine learning tasks. Apache Spark optimizations provide significant performance boosts for large-scale data transformations.
Scalability Analysis
Scalability is essential for ensuring that data platforms can handle increasing workloads without performance degradation. Let’s explore how Snowflake and Databricks manage scalability and support dynamic business needs:
Snowflake Scalability
Snowflake’s architecture is designed for flexible and efficient scaling, allowing independent control over compute and storage resources.
- Independent Scaling:
Compute and storage can be scaled separately, ensuring that you only use resources as needed. This flexibility helps businesses optimize costs while maintaining performance. - Multi-Cluster Warehouses:
- Snowflake supports running multiple concurrent queries without performance drops.
- Each virtual warehouse operates independently, so workloads can run in parallel without resource contention.
- Elastic Scalability:
Snowflake automatically scales up or down based on demand. During peak periods, resources increase dynamically, ensuring that performance remains consistent without manual intervention.- Example: Multiple teams can run intensive queries simultaneously without impacting each other’s work.
Databricks Scalability
Databricks leverages its distributed computing framework to deliver powerful horizontal scaling, making it ideal for big data environments and machine learning workflows.
- Horizontal Scaling:
Databricks distributes data processing tasks across multiple nodes, ensuring efficient handling of large datasets. This approach minimizes processing time for complex transformations. - Auto-Scaling Clusters:
- Compute resources adjust dynamically based on workload demands.
- Databricks can automatically add or remove nodes, optimizing resource usage without manual oversight.
- Large Dataset Processing:
Designed to handle petabyte-scale data, Databricks ensures smooth performance even with massive datasets. Complex data transformations and machine learning tasks can be executed without bottlenecks.- Example: Processing IoT data streams or running extensive predictive analytics models.
| Feature | Snowflake | Databricks |
| Scaling Type | Independent scaling of compute and storage | Horizontal scaling with distributed computing |
| Concurrency Management | Multi-cluster warehouses for parallel workloads | Dynamic node allocation for parallel processing |
| Auto-Scaling | Elastic scaling based on demand | Automatic cluster scaling based on workload |
| Ideal Use Case | Fluctuating workloads with independent query loads | Large-scale data processing and machine learning tasks |
Key Takeaways:
- Snowflake: Perfect for organizations with fluctuating query workloads and a need for independent resource scaling. Multi-cluster support ensures smooth performance across parallel workloads.
- Databricks: Best suited for large-scale data processing and analytics that require horizontal scaling. Its auto-scaling clusters provide flexibility and efficiency in managing big data tasks.
Cost Management and Pricing Models
Snowflake Pricing
Snowflake operates on a pay-as-you-go pricing model, with separate charges for compute and storage. Here are the key elements of its pricing structure:
- Compute Charges:
- Virtual Warehouses: Snowflake charges based on the size and usage of virtual warehouses (compute resources). Pricing varies by region and depends on the warehouse size (x-Small, Small, Medium, Large, etc.).
- Pricing Tiers:
- x-Small: Around $0.00056 per second (approx. $1.00 per hour)
- small: Around $0.00112 per second (approx. $2.00 per hour)
- medium: Around $0.00224 per second (approx. $4.00 per hour)
- large: Around $0.00448 per second (approx. $8.00 per hour)
- On-Demand Scaling: You only pay for compute resources when the virtual warehouse is running, with the ability to scale up or down based on workload demands.
- Auto-Suspend and Auto-Resume: Virtual warehouses automatically suspend after inactivity, preventing unnecessary charges. They automatically resume when needed.
- Storage Charges:
- Data Storage: Storage costs are based on the amount of data stored.
- Standard Storage: $40 per TB per month for active data storage.
- Long-Term Storage: For data not modified in 90 days or more, it is charged at a lower rate—around $23 per TB per month.
- Additional Costs:
- Data Transfer Costs: Moving data in or out of Snowflake (across regions or cloud platforms) incurs additional fees, generally ranging from $0.01 to $0.12 per GB, depending on the cloud provider.
- Marketplace Data: Accessing third-party data from Snowflake’s marketplace incurs separate fees, typically based on the data source and the volume of data being accessed.
- Key Snowflake Pricing Features:
- Flexible Scaling: Resources for compute and storage scale independently, which optimizes costs based on actual usage.
- Predictable Costs: Transparent pricing with clear breakdowns for storage, compute, and data transfers, helping businesses forecast costs accurately.
- Data Caching: Frequently accessed data is cached in Snowflake, which helps reduce compute costs for repeated queries.
Note - For more pricing details refer to this blog
Databricks Pricing
Databricks also follows a consumption-based pricing model but uses Databricks Units (DBUs) to calculate charges, making it well-suited for dynamic workloads like big data processing, machine learning, and streaming analytics.
- Compute Charges:
- Databricks Clusters: Compute is billed based on the virtual machine (VM) or instance type used for the clusters, with the DBU linked to the processing power of the cluster.
- Pricing Tiers: Databricks offers multiple pricing tiers to match different organizational needs:
- Standard: The basic package with essential features and compute capabilities.
- Premium: Offers enhanced features like advanced security, collaborative workspaces, and performance tuning.
- Enterprise: For larger-scale operations, providing enterprise-grade features like full access to machine learning tools, Delta Lake, and support for complex workflows.
- Pricing per DBU (Databricks Unit): A DBU is a unit of processing capability. The cost depends on the type of cluster:
- Standard Cluster: Around $0.15 per DBU per hour.
- Premium Cluster: Around $0.30 per DBU per hour.
- Storage Charges:
- Cloud Storage Integration: Databricks integrates with popular cloud storage providers like AWS, Azure, and Google Cloud. Pricing for storage is based on the cloud provider’s rates (e.g., AWS S3, Azure Blob Storage).
- Data Lake Storage: Databricks typically uses a data lake architecture, which may be priced according to cloud storage provider rates (e.g., $0.023 per GB per month for S3 standard storage).
- Delta Lake: Storage costs for Delta Lake are based on the cloud provider’s object storage pricing (typically aligned with S3 or Azure Blob).
- Data Processing Costs:
- Batch and Streaming: Databricks charges differently for batch and streaming workloads:
- Batch Processing: Based on the size of the cluster and the duration of its usage.
- Streaming Data: Typically charged at a lower rate per DBU but may have additional costs depending on the volume and frequency of the data being processed in real-time.
- Batch and Streaming: Databricks charges differently for batch and streaming workloads:
- Additional Costs:
- Jobs and Workflows: Running complex jobs, workflows, or notebooks in Databricks incurs additional charges. These are billed based on cluster usage and execution time.
- Premium Features: Features like machine learning, enhanced security, and custom integrations are available at higher pricing tiers, especially within the Premium and Enterprise plans.
- Key Databricks Pricing Features:
- Auto-scaling: Databricks clusters automatically scale up or down based on workload demands. This ensures you only pay for what you use.
- Workload Optimization: Databricks allows you to optimize resource usage for different types of workloads, offering separate pricing models for batch and streaming tasks.
Note - For more pricing details refer to this blog
| Feature | Snowflake | Databricks |
| Billing Model | Pay-as-you-go (separate compute and storage) | Consumption-based with tiered plans (Standard, Premium) |
| Compute Charges | Billed by virtual warehouse size (x-Small to x-Large) | Billed by Databricks Units (DBUs) for clusters |
| Storage Charges | $40 per TB (Standard), $23 per TB (Long-term) | Charges based on cloud provider (e.g., $0.023/GB/month) |
| Auto-scaling | Auto-suspend and auto-resume based on activity | Auto-scaling of clusters based on workload demands |
| Data Transfer Costs | $0.01 - $0.12 per GB (depending on region) | Charges for external cloud storage and networking |
| Data Sharing | Additional costs for sharing live data | Supports integration with external data sources and platforms |
| Discounts | Volume discounts and reserved instances | Discounts for long-term or large-scale commitments |
| Premium Features | Additional charges for features like data sharing and data marketplace | Premium tiers include advanced features like ML and enhanced security |
Key Takeaways
- Snowflake offers a predictable pricing model where you pay for what you use, with separate charges for compute and storage. This flexibility works well for businesses with fluctuating workloads.
- Databricks uses a consumption-based model with DBUs, making it suitable for dynamic workloads, particularly for big data processing, machine learning, and streaming tasks. It also offers tiered pricing based on features and support.
- Both platforms offer auto-scaling to optimize resource usage, but Snowflake has a stronger focus on compute and storage separation, whereas Databricks focuses on compute-intensive workloads, especially in data engineering and machine learning.
Security and Compliance Features
Both Snowflake and Databricks emphasize robust security and compliance frameworks, offering features that ensure data protection and regulatory compliance. However, each platform has distinct approaches to addressing these aspects.
Snowflake Security
Snowflake focuses heavily on data protection and compliance with a variety of industry standards. The following are key features of its security model:
Encryption:
Snowflake ensures that all data is encrypted both at rest and in transit using advanced encryption methods like AES-256 and TLS encryption, ensuring that sensitive data is protected from unauthorized access during storage and transfer.
Role-Based Access Control (RBAC):
Snowflake offers fine-grained access control through RBAC, where administrators can define user roles and assign them specific permissions. This ensures that users only have access to the data they need, reducing the risk of unauthorized access.
Multi-Factor Authentication (MFA):
Snowflake provides MFA to add an extra layer of security for user logins, which helps safeguard against unauthorized access.
Compliance:
Snowflake adheres to a wide range of industry standards and regulations, including GDPR, HIPAA, SOC 2, and PCI DSS. This makes it suitable for industries that require strict data governance and privacy protection.
Data Masking and Dynamic Data Protection:
Snowflake supports dynamic data masking and data classification, which allows businesses to protect sensitive information by hiding it from unauthorized users while maintaining access control.
PrivateLink:
Snowflake offers PrivateLink for secure, private connectivity between services, avoiding exposure to public internet networks.
Databricks Security
Databricks, built around Apache Spark, also has strong security features that are integral to its platform, especially given its focus on big data processing and machine learning environments.
Data Encryption:
Databricks ensures that data is encrypted throughout its lifecycle, including in transit and at rest. It supports encryption protocols such as AES-256 to ensure data remains secure.
Role-Based Access Control (RBAC):
Similar to Snowflake, Databricks implements RBAC, enabling administrators to define user roles and permissions for resources, notebooks, jobs, and clusters. This minimizes the risk of unauthorized access and ensures secure management of collaborative environments.
Audit Logging:
Databricks provides comprehensive audit logs for tracking access and usage patterns. These logs help organizations comply with auditing and monitoring requirements, ensuring transparency and accountability.
Identity and Access Management (IAM):
Databricks integrates seamlessly with cloud providers’ IAM systems (such as AWS IAM and Azure Active Directory), allowing businesses to extend their identity policies to Databricks.
Compliance:
Databricks is compliant with several industry standards, such as SOC 2, GDPR, and HIPAA, enabling organizations to handle sensitive data in regulated environments securely.
Secure Network Connectivity:
Databricks supports VPC peering and private IPs for secure networking, ensuring that workloads run in isolated environments and minimizing potential security risks from public networks.
Cluster and Job Security:
Databricks enables security configurations at the cluster level, allowing administrators to control access to clusters and jobs. This ensures that compute resources are used securely and efficiently.
| Feature | Snowflake | Databricks |
| Encryption | Data encrypted at rest and in transit with AES-256 and TLS | Data encrypted at rest and in transit with AES-256 |
| Role-Based Access Control (RBAC) | Granular access control with user roles and permissions | Comprehensive RBAC to manage user access to notebooks, jobs, clusters |
| Multi-Factor Authentication (MFA) | Supports MFA for added security | Supports MFA (via integration with cloud IAM services) |
| Audit Logging | No specific logs, but supports monitoring and auditing | Detailed logs for audit trails and monitoring compliance |
| Compliance | GDPR, HIPAA, SOC 2, PCI DSS, and more | SOC 2, GDPR, HIPAA, and more |
| Data Masking & Protection | Dynamic data masking and data classification | No native data masking, relies on cloud infrastructure |
| Private Network Connectivity | PrivateLink for secure connectivity | VPC peering and private IPs for secure networking |
Key Takeaways
- Snowflake provides a more extensive range of data protection features, including dynamic data masking, PrivateLink for secure connections, and native MFA for additional security layers.
- Databricks offers a robust security framework but is more tailored towards big data and machine learning environments, with comprehensive audit logs, IAM integrations, and secure networking through VPC peering.
- Both platforms comply with critical regulations such as GDPR and SOC 2, making them suitable for industries that require strict data governance.
Usability and Integration Capabilities
Usability and integration are critical factors when comparing platforms for data management. Both Snowflake and Databricks offer unique advantages depending on the intended use case and user requirements. Snowflake is designed for ease of use, while Databricks provides an interactive, collaborative environment suited for data science and machine learning teams.
Snowflake Usability
Snowflake's design focuses on simplicity and accessibility, making it easy for both technical and non-technical users to interact with the platform. The key aspects of Snowflake's usability include:
- Easy-to-Use Console:
- Snowflake provides an intuitive web interface that simplifies data management tasks, including data loading, querying, and monitoring. The platform's SQL-based interface is familiar to many users, reducing the learning curve and enabling fast adoption.
- SQL-Based Querying:
- Snowflake leverages standard SQL for querying, which is an industry-standard language familiar to most data analysts and engineers. This ensures ease of use and smooth adoption for teams who already use SQL in their workflow.
- Integration with BI Tools:
- Snowflake integrates with popular Business Intelligence (BI) tools such as Tableau, Looker, Power BI, and others. This seamless integration allows for real-time data visualizations and reporting without the need for complex configurations.
- Cloud Service Integration:
- Snowflake works seamlessly with all major cloud providers, including AWS, Azure, and Google Cloud Platform (GCP). This enables businesses to connect their Snowflake instance to their cloud ecosystem and leverage existing cloud-based services.
- Zero Management:
- Snowflake's fully managed architecture eliminates the need for manual maintenance or tuning. Users can focus on extracting insights from data instead of managing infrastructure, enhancing overall usability.
Databricks Usability
Databricks, built around Apache Spark, is designed to cater to data engineering, data science, and machine learning teams. Its usability features emphasize collaboration, flexibility, and scalability:
- Collaborative Notebooks:
- Databricks offers collaborative notebooks that allow teams to work together in real-time. These notebooks support different languages, including Python, SQL, R, and Scala, enabling collaborative analysis, experimentation, and model development.
- Language Support:
- Databricks supports multiple programming languages, such as Python, Scala, SQL, and R, making it an ideal platform for teams working on data engineering, machine learning, and data analysis. The versatility in language support ensures that users can work in the language they are most comfortable with.
- Unified Analytics Platform:
- The platform integrates data engineering, machine learning, and analytics workflows within a single unified environment. This streamlines collaboration across teams and reduces the complexity of managing separate tools for different tasks.
- Interactive Workspace:
- Databricks provides an interactive environment that allows users to run and debug code in real time, which is especially beneficial for data scientists and machine learning practitioners who require quick iterations and testing.
- Third-Party Integrations:
- Databricks easily integrates with BI tools, such as Power BI, Tableau, and Looker, as well as cloud platforms like AWS, Azure, and GCP. These integrations enable users to extend the functionality of Databricks and connect with the broader enterprise ecosystem.
| Feature | Snowflake | Databricks |
| User Interface | Intuitive, SQL-based console | Interactive, collaborative notebooks for real-time teamwork |
| Language Support | SQL-based (with some extensions for semi-structured data) | Python, Scala, SQL, R, and others |
| BI Tool Integration | Integrates with Tableau, Looker, Power BI, etc. | Integrates with Tableau, Power BI, Looker, and others |
| Cloud Service Integration | Supports AWS, Azure, GCP | Supports AWS, Azure, GCP |
| Collaboration Features | Limited collaboration features, focus on data management | Real-time collaborative notebooks for teams |
| Data Science & ML Capabilities | Primarily data warehousing, less focus on data science | Optimized for data science, machine learning, and analytics |
| No-Code/Low-Code Features | Zero management, auto-scaling features for simplified usage | Requires more technical skills, optimized for experienced users |
Key Takeaways
- Snowflake is best suited for organizations that prioritize ease of use and data management. It excels at SQL-based querying, integration with BI tools, and requires minimal maintenance, making it ideal for business intelligence and analytics teams.
- Databricks offers a more collaborative environment that is optimized for data science and machine learning teams. It provides real-time collaboration, supports multiple programming languages, and integrates well with both BI tools and cloud platforms.
Use Case Comparisons
Snowflake Use Cases
Snowflake is an excellent choice for organizations focused on data warehousing, business intelligence, and analytics. Its architecture is optimized for managing large volumes of structured and semi-structured data, making it perfect for industries like finance, healthcare, and retail. With its scalability, high performance, and easy integration with BI tools, Snowflake excels in situations where fast query performance and streamlined data storage are paramount.
Key use cases for Snowflake include:
- Data Warehousing: Handling large datasets across multiple cloud environments.
- Business Intelligence: Seamlessly integrating with BI tools like Tableau and Power BI for real-time analytics and reporting.
- Advanced Analytics: Supporting complex analytical workloads, from data preparation to reporting.
Databricks Use Cases
Databricks is designed for organizations looking to leverage big data processing, machine learning (ML), and artificial intelligence (AI). With its Apache Spark-based infrastructure, Databricks excels in processing massive datasets and supporting advanced analytics models. It's ideal for industries like technology, manufacturing, and telecommunications, where real-time data processing, machine learning pipelines, and collaborative development environments are critical.
Key use cases for Databricks include:
- Machine Learning & AI: Building, training, and deploying ML models at scale.
- Big Data Analytics: Processing and analyzing vast amounts of data in real-time.
- Collaborative Data Science: Facilitating collaboration among data scientists, engineers, and analysts within a unified platform.
Real-World Use Cases: Matching Platforms to Needs
| Use Case | When to Choose Snowflake | When to Choose Databricks |
| Primary Goal | Business intelligence, data warehousing, and reporting | Data science, machine learning, and AI applications |
| Data Processing | Structured and semi-structured data | Big data processing, real-time streaming |
| Approach | SQL-based querying, traditional analytics | Collaborative development with flexible programming languages |
| Team Expertise | SQL-proficient teams | Teams using Python, Scala, R, or multiple languages |
| Data Governance | Strong governance, compliance, and data sharing | Less focus on governance, more on processing and analysis |
| Data Scalability | Large-scale data warehousing, real-time analytics | Scalable ML and AI model training, big data processing |
| Industry Fit | Finance, healthcare, retail, and other BI-heavy industries | Technology, manufacturing, telecommunications, data science |
| Real-Time Data | Limited real-time processing capabilities | Robust real-time processing and stream analytics |
| Collaboration | Simple reporting and data sharing | Team collaboration on models, analytics, and development |
Both Snowflake and Databricks offer powerful solutions for modern data challenges, but they cater to different needs. Snowflake excels in cloud data warehousing and business intelligence, while Databricks focuses on big data processing and AI. Understanding the strengths and capabilities of each platform is essential for organizations to select the solution that best aligns with their goals and requirements.






