
Introduction:
When your startup starts growing, the application running on a single node(monolithic app) starts facing degraded performance. The reason is a limit that every technology stack has to serve a certain number of concurrent requests/ tasks per second. This limit could be due to the amount of resources available to the application. This issue could be resolved by doing two things:
- Case for Vertical Scaling: Adding more resources(like CPU, Memory, Disk, Network speed etc.) to the current machine.
- Case for Horizontal Scaling: Adding multiple machines which could split the load and handle it properly.
How has scaling worked traditionally?
Companies used to follow vertical traditionally. Vertical scaling simply means adding more resources(like CPU, Memory, Disk, Network speed, etc.) to the existent host machine. This is also traditionally known as Scaling Up. This traditionally had been the norm until Google came up with two of its famous papers.
- "The Google File System" by Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (2003): This paper describes the Google File System (GFS), a distributed file system designed for scalability and reliability. GFS was one of the foundational technologies that enabled Google to scale its search engine and other services to handle the massive amount of data it processes.
- "MapReduce: Simplified Data Processing on Large Clusters" by Jeffrey Dean and Sanjay Ghemawat (2004) This paper introduces MapReduce, a programming model and software framework for processing large datasets on clusters of computers. MapReduce simplified the development of distributed applications at Google and had a profound impact on the field of big data processing.
Both papers were published in prominent conferences and have been highly cited, making them significant contributions to the field of distributed systems. GFS focused more on the system design and implementation, while MapReduce introduced a new programming paradigm for distributed computing.
History Behind Popularity of Horizontal Scaling or Distributed Architecture:
The stories behind GFS and MapReduce are intertwined and reflect Google's rapid growth and need for scalable solutions in the early 2000s. Here's a glimpse into their origins:
GFS:
- Scaling Challenges: In the late 1990s, Google's search engine was growing rapidly, and existing file systems couldn't handle the massive amount of data efficiently. They were prone to failures, slow reads/writes, and couldn't scale horizontally.
- Distributed Design: Faced with these limitations, Google engineers set out to build a new file system from scratch. The key idea was to distribute data across commodity servers (cheap and readily available) and replicate it for fault tolerance. GFS was born, offering scalability, reliability, and high throughput for large files.
- Impact: GFS became the backbone of Google's infrastructure, supporting critical services like Search and Gmail. It paved the way for distributed storage systems and influenced open-source projects like Hadoop Distributed File System (HDFS).
MapReduce:
- Data Processing Bottleneck: While GFS solved the storage issue, processing the massive datasets efficiently became the next challenge. Traditional parallel programming models were complex and error-prone for large-scale tasks.
- Simplifying Distributed Computing: Enter MapReduce, designed to simplify parallel processing on clusters of machines. It broke down complex tasks into smaller, independent "map" and "reduce" functions, allowing them to be distributed across machines and efficiently processed in parallel.
- Revolutionizing Big Data: MapReduce made it easy for developers to write distributed applications without worrying about low-level details like data distribution and fault tolerance. This sparked the Big Data revolution, making it feasible to analyze massive datasets for insights.
Intertwined Paths:
The development of GFS and MapReduce wasn't linear. They influenced each other. GFS provided a reliable storage foundation for MapReduce, while MapReduce's processing power helped analyze data for optimizing GFS performance.
What is Vertical Scaling?
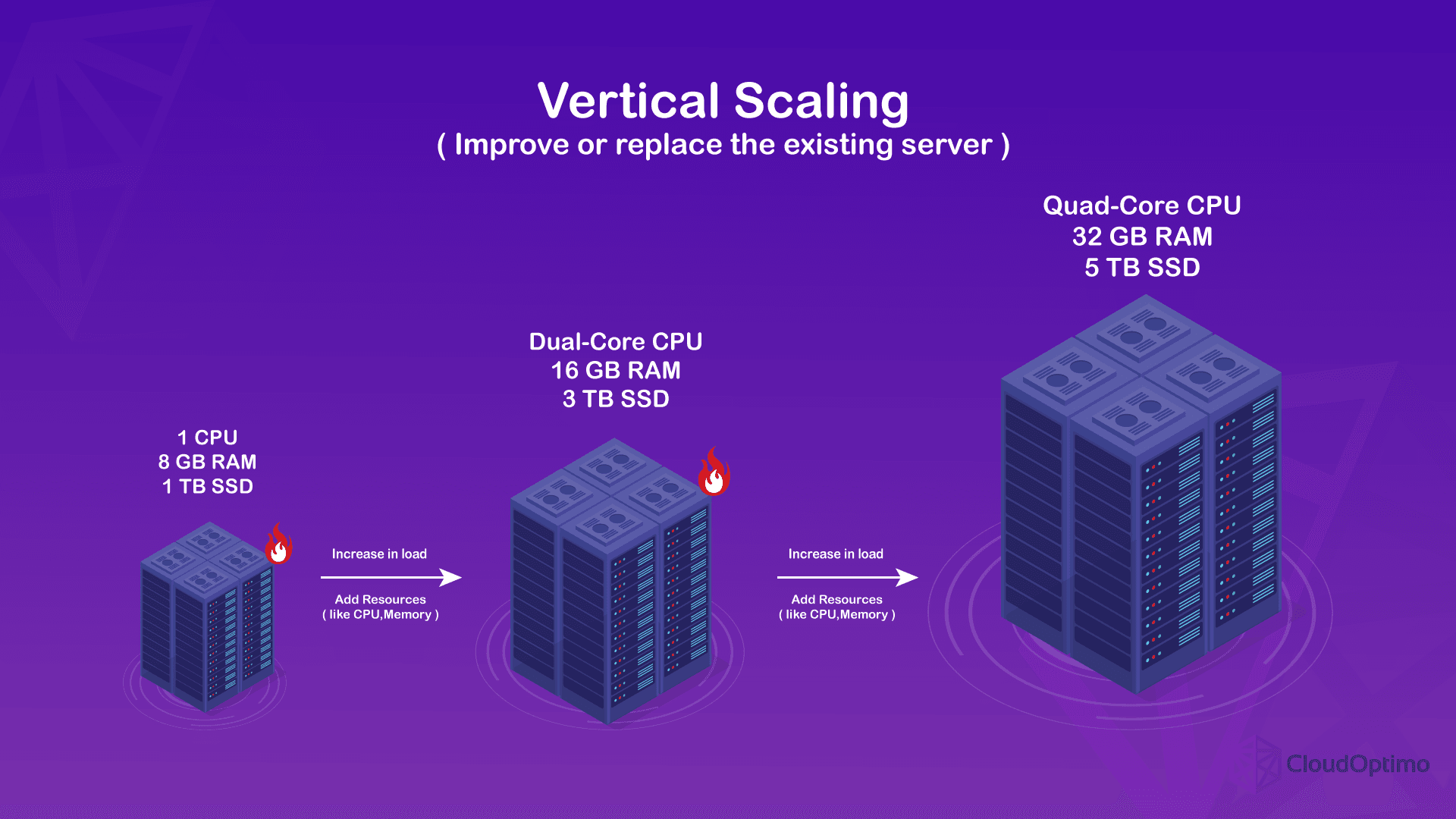
Vertical scaling, also known as "scaling up," is the opposite of horizontal scaling. It involves boosting the capacity of your existing system by adding more resources to the same nodes or machines, instead of adding more nodes themselves. Imagine it like upgrading the engine and tires of your car to handle tougher terrain instead of adding another car to the journey.
How it works?:
- Let's say you have a single server running your application. You could increase its processing power by adding more CPUs or a faster CPU.
- You could also upgrade its memory (RAM) to handle larger datasets or more concurrent requests.
- Additionally, you could expand its storage capacity with additional hard drives or solid-state drives (SSDs).
- By beefing up your existing server, you essentially increase its capabilities to handle heavier workloads.
Key advantages of vertical scaling:
- Simplicity: It's easier to manage and maintain a single server compared to a distributed system with multiple nodes.
- Faster implementation: Upgrading hardware on a single machine is usually quicker than setting up and configuring additional servers.
- Reduced complexity: There's no need to deal with distributed processing or communication overhead.
Limitations of vertical scaling:
- Limited headroom: There's a physical limit to how much you can upgrade a single server. Eventually, you'll hit a point where adding more resources won't provide significant benefits.
- Single point of failure: If your upgraded server fails, your entire system goes down, whereas with horizontal scaling, other nodes can pick up the slack.
- Costlier in the long run: Continuously upgrading hardware on a single server can be more expensive than adding commodity servers horizontally over time.
What is Horizontal Scaling?
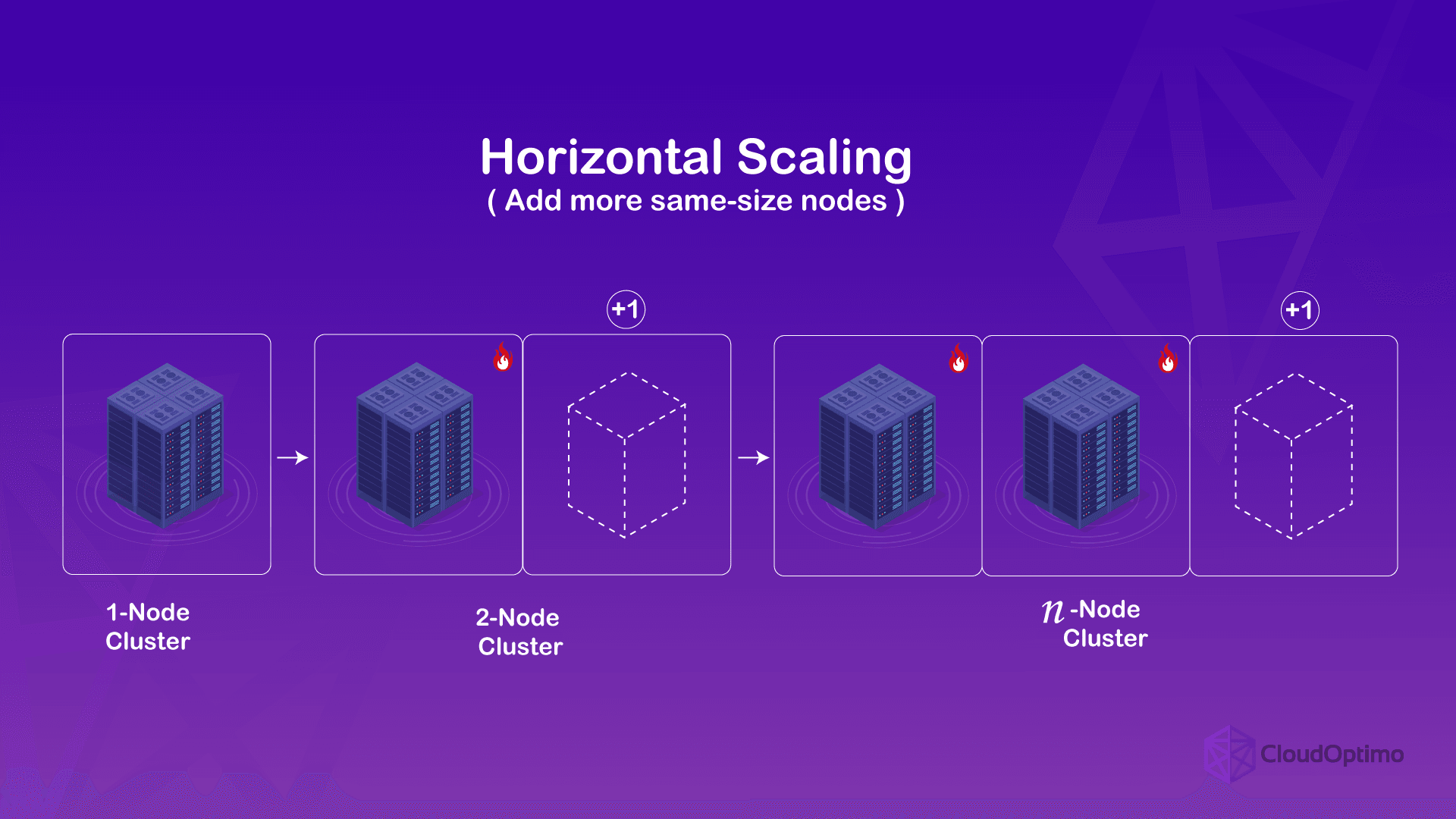
Horizontal scaling, also known as scaling out, is a technique for handling increased workload or demand in a system by adding more nodes or machines to the system. Think of it like adding more lanes to a highway to handle increased traffic instead of just trying to make the existing lanes faster.
How does it works?
- Imagine you have a single server running your application. As traffic or data volume increases, that server might become overloaded and slow down.
- With horizontal scaling, you add another server (node) to the system. This distributes the workload across both servers, improving performance and capacity.
- You can continue adding more servers as needed, essentially spreading the work among a growing team of machines. This makes the system highly scalable and able to handle even massive workloads.
Key benefits of horizontal scaling:
- Increased capacity: You can handle more traffic and data by simply adding more machines.
- Improved performance: Distributing the workload across multiple servers reduces bottlenecks and improves overall responsiveness.
- High availability: If one server fails, the others can pick up the slack, minimizing downtime and ensuring service continuity.
- Cost-effectiveness: Adding commodity servers is often cheaper than upgrading a single server to its limits.
Drawbacks of horizontal scaling:
- Increased complexity: Managing and coordinating multiple servers adds complexity compared to a single server setup.
- Resource overhead: Running additional servers consumes resources like electricity and space.
- Not all applications scale well: Some applications are not designed to be easily distributed across multiple nodes.
- Overall, horizontal scaling is a powerful technique for building highly scalable and resilient systems. It's particularly well-suited for applications that experience variable or unpredictable workloads and require high availability.
Comparison between Vertical Scaling and Horizontal Scaling:
| Feature | Vertical Scaling (Scaling Up) | Horizontal Scaling (Scaling Out) |
|---|---|---|
| Scalability | Limited by hardware limits of a single server | Highly scalable, can add nodes indefinitely |
| Performance | Improved up to a point, then diminishing returns | Linearly increases with added nodes |
| Cost (Initial) | Lower upfront cost, often cheaper for small increases | The higher upfront cost for additional nodes |
| Cost (Ongoing) | Can become expensive as hardware reaches limits | Relatively stable, cost per unit scales linearly |
| Complexity | Simpler to manage and maintain | More complex to manage and coordinate multiple nodes |
| Availability | Single point of failure, entire system goes down if server fails | Fault tolerant, other nodes can pick up the slack if one fails |
| Suitability | Good for predictable workloads, moderate increases | Ideal for unpredictable workloads, high traffic spikes, future growth |
| Examples | Upgrading CPU, RAM, storage on a single server | Adding more web servers, database nodes, application instances |
Practical Use Cases for Vertical and Horizontal Scaling:
| Scenario | Scaling Approach | Pros | Cons |
|---|---|---|---|
| E-commerce website experiencing seasonal traffic spikes (e.g., Black Friday) | Horizontal scaling (add web servers) | - Handles sudden surges in traffic smoothly. - Increased availability and fault tolerance. - Future-proofs for further growth. | - Higher initial cost for additional servers. - Increased complexity in managing server clusters. |
| Small business database struggling with complex queries and growing data volume | Vertical scaling (upgrade CPU, RAM) | - Faster processing power for demanding tasks. - Simpler to manage compared to a distributed system. - Lower initial cost. | - Limited scalability beyond server hardware limits. - Single point of failure if the server crashes. - May not be cost-effective for long-term needs. |
| Video game server with fluctuating player count | Hybrid approach: - Vertical scaling (upgrade CPU) for base capacity. - Horizontal scaling (add game servers) during peak hours. | - Combines benefits of both approaches. - Scalable for unexpected player spikes. - Efficient resource utilization during low traffic periods. | - More complex setup and management than individual approaches. - Requires careful planning and configuration for smooth scaling. |
| Mobile app with unpredictable user activity (e.g., news app during breaking events) | Horizontal scaling (add application instances) | - Responsive performance even with sudden user influx. - High availability and fault tolerance. - Elastic scaling based on real-time demand. | - Higher ongoing cost for cloud resources. - Increased monitoring and management overhead. |
| Small startup with limited budget and predictable workload | Vertical scaling (upgrade server resources) | - Cost-effective solution for initial growth. - Simpler setup and maintenance. - Sufficient for current needs. | - Limited scalability for future growth. - Single point of failure risk. - May become expensive as workload increases. |
Conclusion:
Choosing between vertical and horizontal scaling depends on your specific needs and application. If you need a quick and simple solution for a moderate increase in workload, vertical scaling might be a good option. However, for highly scalable and resilient systems that need to handle significant traffic spikes or unpredictable workloads, horizontal scaling is often the preferred approach.






