

1. Introduction to Real-Time Data Streaming
In today's digital landscape, data is generated continuously and in massive volumes. From user interactions on websites and mobile apps to IoT sensor outputs and financial transactions, organizations are increasingly looking for ways to act on this data as it happens. This need has given rise to real-time data streaming.
What Is Real-Time Data Streaming?
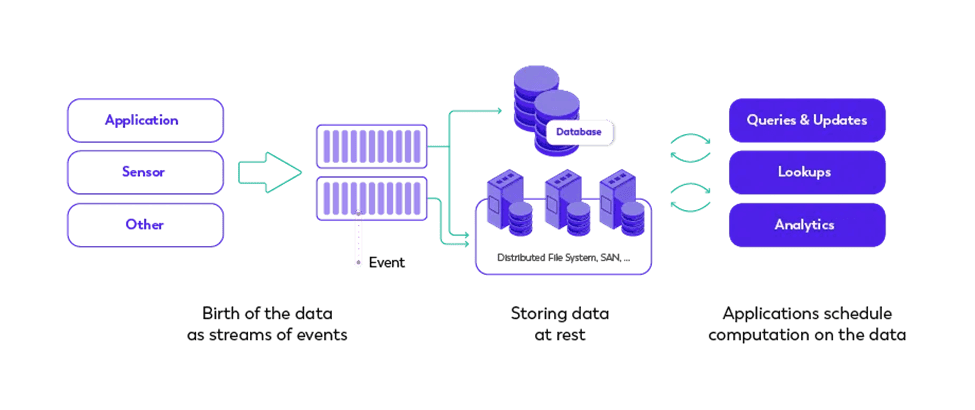
Source: estuary.dev
Real-time data streaming refers to the processing and analysis of data as it is created. Unlike traditional batch processing, which stores data and processes it at scheduled intervals, streaming enables applications to respond immediately to incoming data. This approach is particularly useful in scenarios where low latency and real-time insights are critical.
Importance in Modern Architectures
Real-time streaming has become foundational in modern, event-driven architectures. Businesses across industries rely on it to:
- Detect and respond to security threats in seconds
- Personalize user experiences based on live interactions
- Monitor infrastructure and application performance
- Enable intelligent automation in connected devices
As systems become more dynamic, the ability to make timely decisions based on streaming data can directly impact customer satisfaction, operational efficiency, and competitive advantage.
Limitations of Traditional Batch Processing
While batch processing is suitable for certain analytical workloads, it introduces delays and lacks responsiveness. Key limitations include:
- High latency: Time lag between data generation and insight
- Static data sets: No continuous updates or real-time feedback
- Complex workflows: Increased overhead to handle time-sensitive tasks
These challenges have driven the adoption of platforms like Amazon Kinesis, which are purpose-built for real-time data processing at scale.
2. Overview of Amazon Kinesis
What Is Amazon Kinesis?
Amazon Kinesis is a fully managed platform provided by AWS that enables developers and data teams to ingest, process, and analyze real-time streaming data. It offers a suite of services designed to handle everything from high-volume event streams to time-encoded media like video and audio.
Whether the goal is to build real-time dashboards, detect anomalies, or route data into analytics platforms, Kinesis provides the tools to support a wide variety of streaming data applications.
How It Integrates into the AWS Ecosystem
Kinesis is tightly integrated with other AWS services, making it easy to construct scalable and responsive data pipelines. For example:
- Data can be ingested through Kinesis Data Streams, transformed with AWS Lambda, and stored in Amazon S3
- Kinesis Data Firehose can automatically load data into Amazon Redshift for further analysis
- Kinesis Data Analytics supports querying streams directly using SQL, without provisioning servers
These integrations reduce operational complexity and allow teams to focus on building data-driven applications rather than managing infrastructure.
High-Level Architecture
Here’s a simplified view of how Kinesis fits within a real-time pipeline:
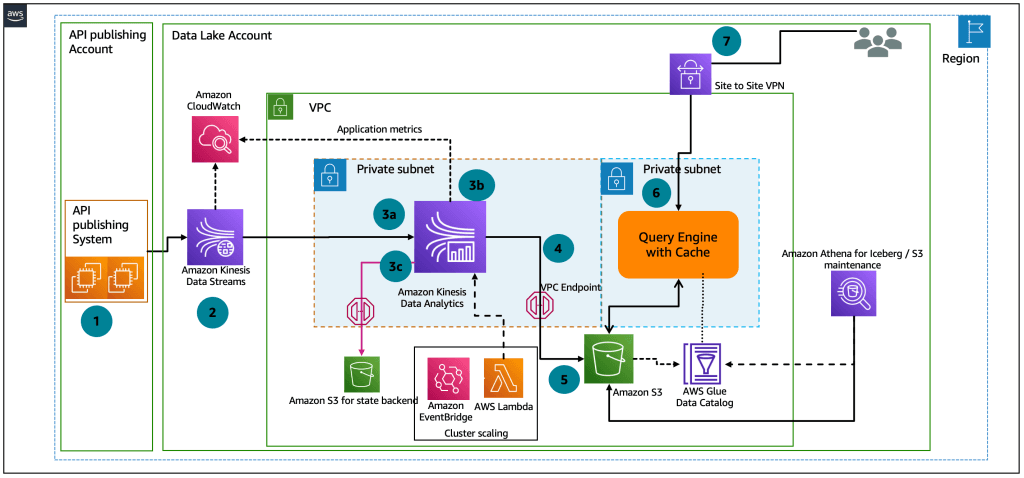
Source: AWS
This architecture supports a wide range of use cases, from simple log forwarding to complex, multi-stage stream processing applications.
3. Kinesis Core Services Explained
Amazon Kinesis consists of four core services, each serving a specific role in a real-time data architecture. Choosing the right one depends on the nature of the data, the processing requirements, and the intended destination.
3.1 Kinesis Data Streams (KDS)
Purpose: Enables developers to build custom, high-throughput streaming applications with precise control over data ingestion and processing.
Key Capabilities:
- Ingests real-time data from thousands of producers
- Organizes data into shards, which define throughput limits
- Allows multiple consumers to read data concurrently
- Stores records for up to 7 days
When to Use: Use KDS when you need fine-grained control over processing logic, such as in real-time fraud detection, live analytics dashboards, or streaming machine learning pipelines.
3.2 Kinesis Data Firehose
Purpose: A fully managed service that reliably delivers streaming data to destinations such as Amazon S3, Redshift, OpenSearch, or third-party services like Splunk.
Key Capabilities:
- No infrastructure to manage—Firehose automatically scales
- Supports data transformation with AWS Lambda
- Handles batching, compression, and encryption
When to Use: Ideal for use cases that require minimal processing and straightforward delivery to storage or analytics tools—for example, log collection, metrics ingestion, or data lake population.
3.3 Kinesis Data Analytics
Purpose: Allows developers and analysts to process streaming data using SQL—no need to build and manage custom stream processing applications.
Key Capabilities:
- Write SQL queries against streaming data from KDS or Firehose
- Supports windowed aggregations, filters, and joins
- Scales automatically based on data volume
When to Use: Best suited for real-time alerting, metric calculation, and stream filtering—especially for teams with SQL expertise but limited background in distributed systems.
3.4 Kinesis Video Streams
Purpose: Designed for real-time streaming and storage of video, audio, and other time-encoded media.
Key Capabilities:
- Ingests and stores encrypted video streams
- Enables playback and on-demand processing
- Integrates with AWS ML services for analysis (e.g., facial recognition)
When to Use: Commonly used in security monitoring, smart home applications, and industrial automation scenarios where media needs to be recorded, analyzed, or streamed in real time.
Each Kinesis service addresses a specific category of streaming data, allowing teams to choose the right tool for the right job. Together, they form a flexible and powerful platform for real-time data solutions on AWS.
4. Architectural Deep Dive
To get the most out of Amazon Kinesis, it’s important to understand what’s happening behind the scenes. This section dives deeper into the architecture of each Kinesis service and how they fit into a larger data pipeline.
Partitioning, Shards, and Throughput in Kinesis Data Streams
At the heart of Kinesis Data Streams (KDS) is the concept of shards. A shard is a unit of throughput—it controls how much data you can write to and read from your stream.
Each shard provides:
- 1 MB/sec or 1,000 records/sec for writes
- 2 MB/sec for reads
So if your application needs to handle 5 MB/sec of incoming data, you’ll need at least 5 shards.
Shards are assigned data using a partition key, which is a string you define when sending data. This key determines which shard the data goes to. The key should be designed to distribute data evenly, avoiding “hot shards” that become overwhelmed.
Example:
| json { "PartitionKey": "user_9483", "Data": "user clicked on homepage banner" } |
Using IDs like session ID or user ID is a good practice to ensure even distribution.
Tip: If your stream starts to lag, check CloudWatch for WriteProvisionedThroughputExceeded—this means your shards are maxing out.
Buffering and Delivery in Kinesis Data Firehose
Kinesis Data Firehose takes a more hands-off approach. You don’t manage shards here—instead, Firehose automatically:
- Buffers incoming data (default: 5 minutes or 1–128 MB, whichever comes first)
- Applies optional transformations via AWS Lambda
- Delivers data to destinations like S3, Redshift, OpenSearch, or custom HTTP endpoints
You can also enable compression (GZIP, Snappy, ZIP) and data format conversion (e.g., JSON to Parquet).
When buffering matters:
If you're delivering to S3 and want near real-time performance, reduce the buffer interval to speed up delivery—but be aware this might increase your cost (more frequent S3 PUT operations).
Stateful Processing in Kinesis Data Analytics
Kinesis Data Analytics lets you process and analyze streaming data using SQL—a powerful feature for teams who want real-time insight but don’t want to manage complex stream processors.
What makes it unique is stateful processing:
- You can maintain session data, count events, or calculate running totals
- Supports sliding, tumbling, and session windows
- Can join multiple streams or perform time-based aggregations
Example SQL Query:
| sql SELECT region, COUNT(*) as view_count FROM input_stream WINDOWED BY TUMBLING (INTERVAL '1 MINUTE') GROUP BY region; |
This query gives you a per-minute count of events per region—ideal for dashboards or alerts.
Integration with AWS Lambda, S3, Redshift, and More
One of the strengths of Kinesis is its native integration with other AWS services, which allows you to create modular, event-driven pipelines.
| AWS Service | Integration Role |
| Lambda | Run custom logic on stream data (e.g., enrich, filter, alert) |
| S3 | Durable object storage for raw or transformed data |
| Redshift | Store for real-time analytics and reporting |
| OpenSearch | Powering search and dashboards (e.g., Kibana) |
| CloudWatch | Log and monitor stream performance |
These integrations reduce operational overhead and allow you to focus on delivering business value from your data.
5. Setting Up Your First Kinesis Pipeline
Let’s look at what it takes to build a basic end-to-end Kinesis pipeline—from data ingestion to real-time processing and storage.
Step 1: Creating a Data Stream
Start by creating a Kinesis Data Stream in the AWS Management Console or via the CLI.
- Define a name (e.g., user-activity-stream)
- Select shard count based on expected throughput
- Optional: Enable server-side encryption using KMS
You can scale your stream later by resharding—splitting or merging shards based on usage.
Step 2: Ingesting and Consuming Data
To push data into Kinesis, use:
- AWS SDKs (e.g., Python boto3, JavaScript)
- Kinesis Producer Library (KPL) for higher efficiency
- Kinesis Agent to stream logs from EC2
Sample Python snippet:
| python import boto3 client = boto3.client('kinesis') client.put_record( StreamName='user-activity-stream', Data=b'user clicked on page', PartitionKey='user_123' ) |
To consume data:
- Use AWS Lambda to process each record as it arrives
- Or use Kinesis Client Library (KCL) for custom consumer apps
Step 3: Transforming and Storing Data
After ingesting data, you might want to:
- Filter or enrich it (via Lambda)
- Analyze it (via Kinesis Data Analytics)
- Store it (via Firehose to S3, or directly to Redshift)
For example, you could:
- Use Lambda to remove PII before saving to S3
- Use Analytics to calculate click-through rates
- Route logs into OpenSearch for real-time querying
Step 4: Monitoring and Metrics with CloudWatch
CloudWatch provides detailed metrics for your stream:
| Metric | Description |
| IncomingBytes | Volume of incoming data |
| PutRecord.Success | Successful record ingestion |
| IteratorAgeMilliseconds | Consumer lag |
| ReadProvisionedThroughputExceeded | Consumer bottlenecks |
Set up alarms to catch:
- Sudden drops in data volume
- Processing delays (e.g., high iterator age)
- Shard capacity limits being reached
These insights help you stay proactive about scaling and performance tuning.
6. Security and Compliance Considerations
Real-time data often includes sensitive information—making security and compliance a top priority. Amazon Kinesis includes multiple layers of protection, from encryption to access control to regulatory compliance support.
Encryption at Rest and in Transit
All Kinesis services support:
- In-transit encryption using TLS
- At-rest encryption via AWS Key Management Service (KMS)
You can use AWS-managed keys (default) or customer-managed keys for more control.
Use encryption if your stream handles:
- User data
- Financial transactions
- Medical or regulated data
IAM Roles and Access Policies
Kinesis access is managed via IAM roles and policies. You can assign granular permissions, such as:
| Action | Use Case |
| kinesis:PutRecord | Allow producer apps to send data |
| kinesis:GetRecords | Allow consumers to read from the stream |
| kinesis:DescribeStream | Allow stream configuration access |
Tip: Always follow least privilege. Use different roles for producers, consumers, and admins.
Private Access via VPC Endpoints
To restrict data flows to your private network:
- Set up VPC Interface Endpoints (via AWS PrivateLink)
- Ensure traffic doesn't leave AWS's secure infrastructure
- Use security groups and VPC flow logs for added visibility
This is especially important for financial services, healthcare, or any regulated industry.
Compliance Certifications
Amazon Kinesis complies with several global and industry-specific standards:
| Standard | Supported |
| HIPAA | ✔ Yes |
| GDPR | ✔ Yes |
| SOC 1, 2, 3 | ✔ Yes |
| ISO 27001 | ✔ Yes |
| FedRAMP | ✔ (Depending on region/service) |
You’re still responsible for how your application handles data, but AWS provides the tools to help you meet strict compliance needs.
7. Performance Tuning and Best Practices
Optimizing the performance of your Amazon Kinesis pipeline ensures that it can handle high-volume data with minimal latency and without overburdening your resources. Here’s how to fine-tune your setup for optimal performance.
Scaling with Shards in Kinesis Data Streams
In Kinesis Data Streams (KDS), the capacity of your stream is determined by the number of shards you use. Each shard provides a specific level of throughput, which directly impacts the performance of your application. By scaling your shards correctly, you can accommodate higher data ingestion rates.
A single shard provides the following:
- 1 MB/sec for incoming data (writes)
- 2 MB/sec for outgoing data (reads)
- 1,000 records/sec for write operations
When you anticipate high data volumes, it’s essential to scale your stream by increasing the number of shards, either manually or via on-demand mode where Kinesis automatically adjusts based on your traffic.
Producer and Consumer Optimization
Optimizing the producer and consumer sides of your pipeline can significantly impact throughput. For producers, using the Kinesis Producer Library (KPL) enables record aggregation to send multiple records in a single request, reducing the overhead of network calls.
For consumers, consider leveraging the Kinesis Client Library (KCL), which supports parallel processing, load balancing, and checkpointing, making it easier to scale your application as your data load increases. Using Enhanced Fan-Out also improves performance by enabling each consumer to receive data at a higher throughput rate, directly from Kinesis.
Handling Throttling and Retry Logic
When your application exceeds the throughput limits of a shard, throttling can occur. To avoid this, retry logic is essential. Implement exponential backoff in your application to handle retries, and consider using buffering queues to temporarily store data before retrying if necessary.
Kinesis Data Firehose automatically retries failed deliveries, but in KDS, retry logic needs to be built into your consumer applications.
Monitoring Latency and Error Rates
Monitoring key metrics through Amazon CloudWatch is vital for ensuring your data pipeline performs optimally. Some critical metrics to watch include:
- PutRecord.Success: Measures the success of data ingestion
- GetRecords.IteratorAgeMilliseconds: Indicates latency between ingestion and consumption
- ThrottledRequests: Identifies when you exceed throughput limits
By setting up CloudWatch alarms, you can proactively monitor these metrics to address potential issues before they become critical.
8. Cost Optimization Strategies
While Kinesis offers powerful real-time streaming capabilities, it’s important to understand how costs are incurred and find ways to minimize them without sacrificing performance. Below is an overview of the pricing model and practical strategies for cost reduction.
Understanding the Kinesis Pricing Model
Kinesis follows a pay-as-you-go model, with separate pricing structures for Kinesis Data Streams, Firehose, Data Analytics, and Video Streams. Below is a breakdown of the key cost factors:
| Service | Pricing Factors | Publicly Available Prices |
| Data Streams | Shard usage (per hour), data ingestion (per GB), and data retrieval (per GB) | $0.015 per shard hour, $0.028 per GB ingested, $0.014 per GB retrieved |
| Firehose | Data ingestion (per GB) and data delivery (per GB) | $0.029 per GB ingested, $0.035 per GB delivered to destinations |
| Data Analytics | vCPU usage per hour (charged per second), data processed (per GB) | $0.11 per vCPU hour, $0.035 per GB processed |
| Video Streams | Video ingestion, storage, and retrieval (per minute/GB) | $0.020 per minute ingested, $0.045 per GB stored |
Cost Comparison Across Services
When choosing between KDS and Firehose, the decision largely depends on your processing needs:
- Kinesis Data Streams is more suitable for custom processing workflows where you need full control over the pipeline and prefer manual scaling.
- Kinesis Firehose is best for use cases where you need a simple, fully managed delivery pipeline to destinations like S3, Redshift, or ElasticSearch. It’s generally more cost-effective for simple data transfer tasks without complex transformations.
Tips to Reduce Ingestion and Storage Costs
Here are some strategies to optimize your Kinesis pipeline cost-effectively:
- Use data aggregation: Batch multiple small records into a single request to reduce overhead.
- Compression: Enable compression (e.g., GZIP) when using Firehose to reduce data storage costs.
- Retention policies: Set an appropriate retention period for KDS streams to minimize storage costs. Reducing the default 24-hour retention can save significant money if your use case does not require long-term storage.
- Lambda transformations: Perform data transformation on the fly with Lambda before storing or delivering to reduce unnecessary data transfer or storage costs.
By reviewing your Kinesis usage periodically, you can make informed adjustments to keep costs under control.
9. Real-World Use Cases and Architectures
Amazon Kinesis is a versatile tool used in a wide variety of real-time data streaming scenarios across industries. Below are some prominent use cases that highlight the power of Kinesis in action.
Real-Time Log Analysis
Real-time log collection and analysis is one of the most common use cases for Kinesis. By streaming log data into Kinesis Firehose, organizations can route logs to S3 for storage or to OpenSearch for real-time querying. This approach ensures that businesses can continuously monitor their infrastructure and applications for issues, providing near-instant visibility into system performance.
IoT Data Ingestion and Processing
For the Internet of Things (IoT), Kinesis handles massive data streams generated by devices such as sensors, smart meters, and connected products. Data is ingested into Kinesis Data Streams, processed via Kinesis Data Analytics or Lambda, and can be stored in services like Amazon Timestream or Redshift. This architecture supports real-time decision-making and anomaly detection, allowing businesses to act quickly on data from millions of devices.
Fraud Detection and Anomaly Monitoring
In sectors like finance, where fraud detection is critical, Kinesis enables real-time monitoring of transactions. Data streams from Kinesis Data Streams can be processed for anomaly detection, with Lambda or machine learning models helping to identify fraudulent activities. Alerts can be triggered immediately, allowing for fast intervention.
Clickstream Analytics
Tracking user behavior via clickstream data helps businesses understand how users interact with their websites or apps. Using Kinesis Data Streams, you can ingest user interaction data and analyze it in real time with Kinesis Data Analytics. This helps businesses personalize their offerings, improve customer experience, and optimize their digital strategies based on real-time insights.
These real-world use cases demonstrate how Kinesis can be adapted for a variety of business needs, ranging from real-time log analysis to sophisticated IoT data processing.
10. Comparing Kinesis with Apache Kafka
As you evaluate Amazon Kinesis for your real-time data streaming needs, it’s important to understand how it compares with other popular streaming solutions like Apache Kafka. Both platforms serve similar purposes but have distinct features, strengths, and weaknesses that may influence your decision.
Feature-by-Feature Comparison
| Feature | Amazon Kinesis | Apache Kafka |
| Managed Service | Fully managed (with Kinesis Data Streams, Firehose, Analytics) | Self-managed (requires setup and maintenance) |
| Ease of Use | Simple to configure and integrate with AWS ecosystem | Requires more setup, operational expertise |
| Scaling | Automatic scaling available (Kinesis Data Streams) | Manual scaling; requires handling partitioning |
| Data Retention | Configurable (up to 365 days for Kinesis Data Streams) | Configurable, but typically designed for long-term retention |
| Throughput | Up to 1,000 records per second per shard for writes | Higher throughput, supports more complex architectures |
| Integration | Natively integrates with AWS services | More third-party integrations, but lacks native AWS support |
Performance and Scaling Differences
Kinesis provides automatic scaling in its Kinesis Data Streams service, making it easier to adjust throughput based on real-time data ingestion needs. With Kinesis Data Firehose, scaling is completely automated, eliminating manual interventions. This automatic scalability ensures that Kinesis handles variable workloads effectively.
In contrast, Apache Kafka offers greater flexibility and control over scaling but requires manual intervention. Kafka clusters need to be carefully managed to balance the load across partitions and brokers, especially as the data volume grows. Kafka is often the better choice when performance needs are highly customized or when managing multi-region deployments.
Operational Complexity
One of the key differences between Kinesis and Kafka lies in operational complexity. Kinesis is fully managed, which means that AWS takes care of much of the heavy lifting related to scaling, patching, and infrastructure management. This allows your team to focus on building applications rather than managing the underlying service.
Apache Kafka, on the other hand, is often deployed in self-managed clusters, requiring more operational effort. While Kafka is extremely powerful and flexible, it demands expertise in cluster management, monitoring, and troubleshooting. For organizations with resources to handle complex infrastructure, Kafka can provide additional customization. But for teams looking for simplicity and integration with the AWS ecosystem, Kinesis is often the easier choice.
When to Choose Which
- Choose Kinesis when you need a fully managed service with seamless integration into the AWS ecosystem and want to focus more on application development rather than operational overhead.
- Choose Apache Kafka when you require greater control over infrastructure, complex routing of data, or need to manage long-term data retention across different environments.
11. Limitations and Trade-offs
While Amazon Kinesis offers powerful capabilities for real-time data streaming, there are certain limitations and trade-offs to consider when architecting your solution.
Latency Expectations
Kinesis guarantees low-latency data processing, but like any streaming service, it’s important to be aware of the inherent latency. For Kinesis Data Streams, the time between data ingestion and consumption can typically range from milliseconds to seconds. However, heavy data volumes, processing logic, or poor network conditions can introduce delays. For applications where real-time processing is critical, latency can become a challenge that requires careful design to minimize bottlenecks.
Throughput Bottlenecks
Throughput bottlenecks are common in Kinesis when the number of shards does not scale in accordance with the volume of data being ingested. If the throughput of your stream exceeds the shard capacity, you may encounter throttling or dropped records. To mitigate this, you should actively monitor throughput and adjust shard counts as needed. In addition, careful partition key selection helps distribute the load across shards, preventing hot spots that can lead to bottlenecks.
Service Quotas and Constraints
Every AWS service has quotas or limits, and Kinesis is no exception. Some of the key quotas include:
- The maximum number of shards per stream (currently 500 shards per stream in standard mode)
- Firehose delivery streams can handle a maximum of 5,000 records per second per stream.
For applications with demanding requirements that exceed these quotas, you may need to design a more complex architecture or contact AWS for quota increases. Understanding these limits upfront can help you design your pipeline accordingly.
Additionally, data retention times in Kinesis are configurable but can come with costs. By default, Kinesis Data Streams retains data for 24 hours, but if you extend this retention period (up to 365 days), your storage costs will increase.
12. Conclusion
Amazon Kinesis offers a powerful suite of services tailored for real-time data streaming, transformation, and delivery at scale. Whether you’re building a real-time analytics dashboard, processing IoT sensor data, or powering event-driven applications, Kinesis provides the infrastructure to handle high-throughput, low-latency pipelines with ease.
Throughout this blog, we explored the core components—Kinesis Data Streams, Firehose, Data Analytics, and Video Streams—each serving distinct roles in the streaming ecosystem. We also took a closer look at performance tuning, cost optimization, and real-world architectures, highlighting how businesses can maximize Kinesis' potential while staying cost-effective and operationally lean.
While it’s important to weigh the trade-offs such as latency, throughput limits, and service quotas, Kinesis’ deep integration within the AWS ecosystem, coupled with its managed and serverless capabilities, makes it an ideal choice for teams looking to build resilient and scalable streaming solutions without the complexity of managing infrastructure.
In a world increasingly driven by real-time data, Amazon Kinesis stands as a key enabler for modern, intelligent applications that demand speed, agility, and continuous insights.






