

As businesses continue to generate vast amounts of data, the need for efficient data integration, transformation, and analytics has never been greater. Microsoft Azure provides two powerful tools—Azure Data Factory (ADF) and Azure Databricks—to handle these challenges. But which one is the right fit for your data processing needs? This blog aims to clarify the differences, strengths, and ideal use cases for both solutions to help you make an informed decision.
Why Compare Azure Data Factory and Azure Databricks?
Many businesses struggle with understanding whether they should use ADF or Databricks for their data workflows. Are these tools competing, or can they work together? Understanding their differences helps in selecting the right one for your needs.
Common Misconceptions About These Two Services
- "ADF and Databricks do the same thing." – While both handle data transformation, their execution models and use cases differ.
- "Databricks is just a better version of ADF." – Databricks is designed for big data and machine learning, while ADF specializes in ETL workflows.
- "ADF and Databricks can’t be used together." – In reality, they complement each other well in many scenarios.
Understanding Their Roles in Data Processing
What is Azure Data Factory (ADF)?
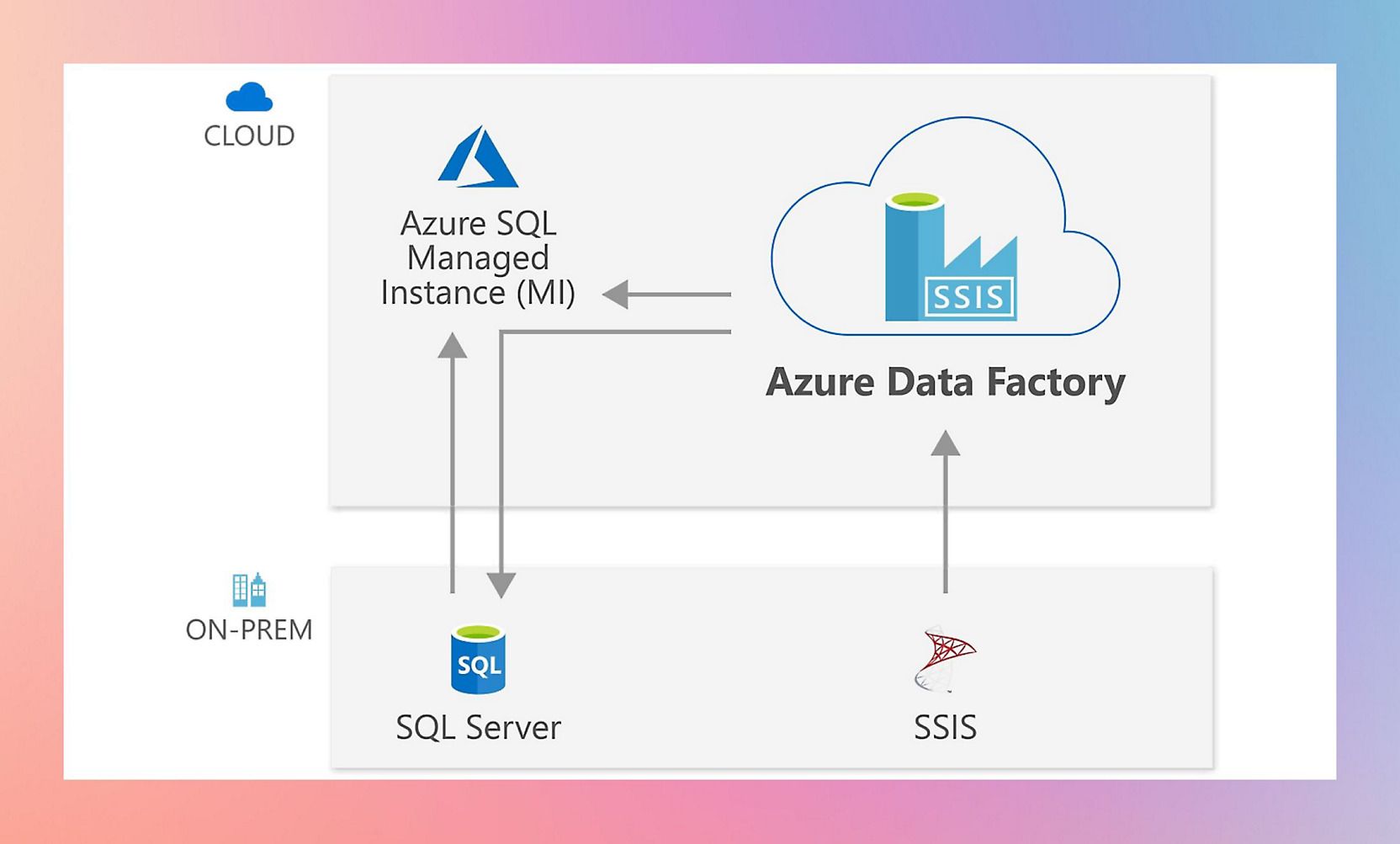
Source - Azure
Azure Data Factory is a cloud-based data integration service that allows you to create, schedule, and orchestrate Extract, Transform, and Load (ETL) workflows across diverse data sources.
Key Features and Capabilities
- Data Ingestion & Integration: Supports over 90 data connectors for seamless data movement.
- Low-Code Approach: Provides a visual interface to design workflows without needing extensive coding.
- Data Flow Transformations: Offers data transformation capabilities using data flow activities.
- Scalability & Monitoring: Provides built-in monitoring, logging, and alerting mechanisms.
Common Use Cases
- Migrating on-premises data to the cloud.
- Automating ETL pipelines for structured and semi-structured data.
- Integrating multiple data sources for unified reporting.
What is Azure Databricks?
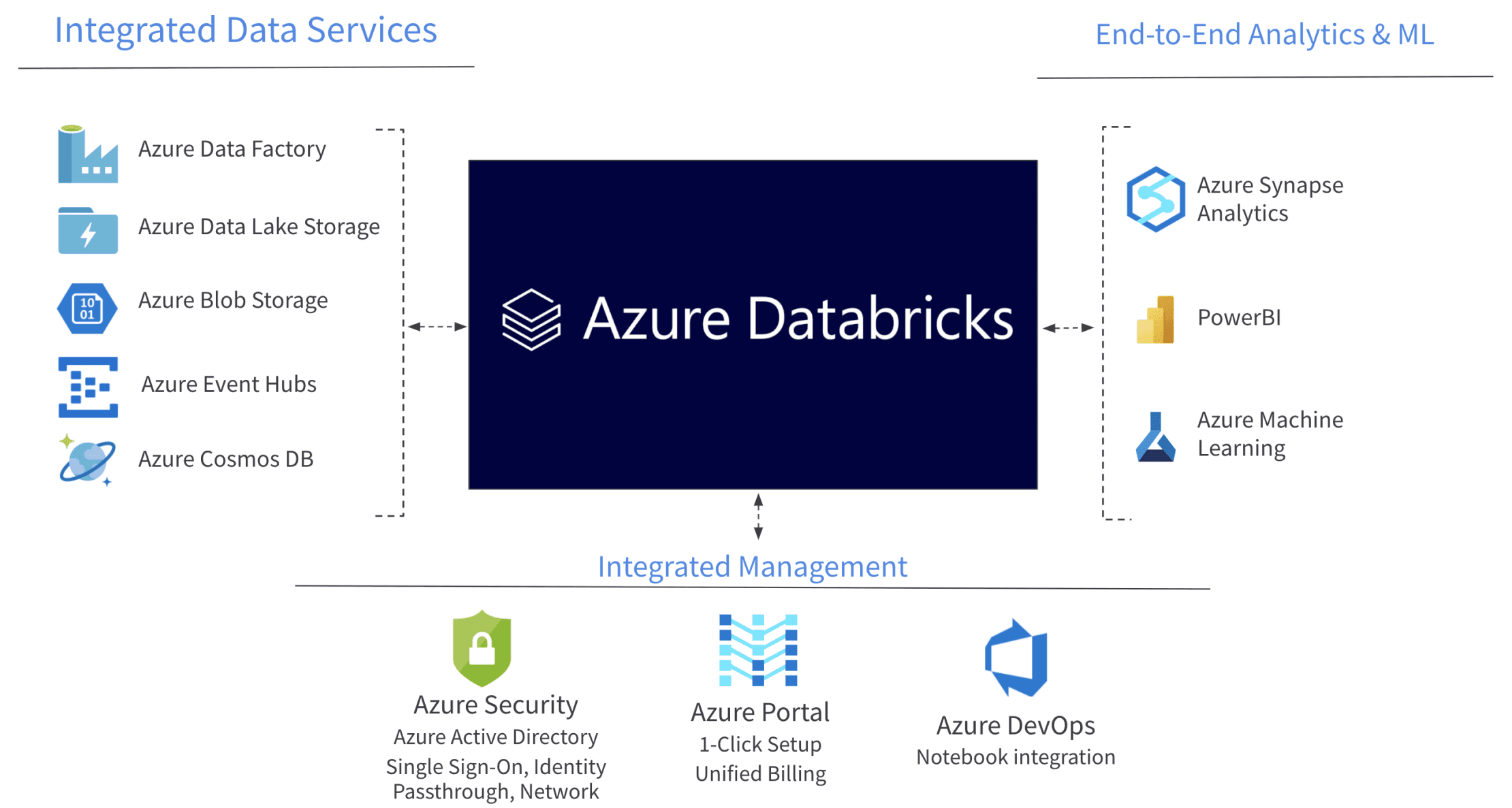
Source - Databricks
Azure Databricks is an Apache Spark-based analytics platform optimized for big data processing and AI workloads.
Key Features and Capabilities
- Scalable Big Data Processing: Designed to handle massive data volumes efficiently.
- Advanced Analytics & AI: Supports ML models, data science workloads, and real-time analytics.
- Collaborative Workspaces: Allows teams to collaborate using notebooks with Python, Scala, and SQL.
- Seamless Integration: Works well with Azure services such as Azure Data Lake and Power BI.
Common Use Cases
- Running large-scale data analytics and machine learning models.
- Processing unstructured and semi-structured data from IoT devices and logs.
- Performing advanced real-time analytics on streaming data.
Key Differences
Although both are integral to modern data engineering and processing workflows, they cater to different needs. Understanding their core differences is key to selecting the right solution for your data processing tasks.
Let’s break down their key differences across 7 important areas to help you make an informed decision based on your organization's unique needs.
| Key Difference | Azure Data Factory | Azure Databricks |
| Data Processing & Transformation Approach | Low-code data orchestration (ETL) | Advanced big data computation (ELT, ML) |
| Architecture & Workflow Execution | Pipeline-based execution | Cluster-based execution |
| Performance & Scalability | Parallel execution for large datasets | Distributed computing with auto-scaling |
| Integration & Connectivity | 90+ built-in connectors for hybrid environments | Deep integration with Spark, ML, and AI tools |
| Hybrid & Multi-Cloud Support | Integrates primarily with Azure ecosystem, limited direct multi-cloud capabilities | Supports hybrid and multi-cloud setups via open-source Spark and REST APIs |
| Data Engineering vs. Data Science | Best for ETL pipelines and data movement | Best for machine learning, AI, and advanced analytics |
| Security & Compliance | Azure AD, Key Vault, Managed Identity integration | Azure AD, Managed Identity, Spark-level security with fine-grained access control |
This table provides a snapshot of the key differences between Azure Data Factory and Azure Databricks, giving you a quick understanding of their roles. If you're looking for a solution to manage data workflows, ADF is your go-to tool. If your focus is on advanced data processing, analytics, or machine learning, Databricks is the more suitable choice.
Next, we will explore these differences in detail, including their data processing and transformation approaches, performance and scalability, security considerations, and more.
Data Engineering vs. Data Science Capabilities
When choosing between Azure Data Factory (ADF) and Azure Databricks, it’s important to understand their distinct roles in data engineering and data science. Both services offer unique capabilities, but they cater to different tasks and workflows. Here’s a closer look at their strengths:
Azure Data Factory: Best for Data Movement & ETL Pipelines
- Core Focus: ADF is designed for data movement and ETL pipelines. It allows organizations to orchestrate the flow of data from various sources to destinations, making it a natural fit for teams focused on building and managing data pipelines.
- Low-Code Approach: ADF is optimized for data engineers who need to automate data workflows with minimal coding. It provides a low-code interface for orchestrating complex processes.
- ETL-Optimized: ADF is built for Extract, Transform, and Load (ETL) workflows, handling large-scale data processing with ease while integrating with a wide variety of data sources.
Azure Databricks: Best for AI, ML, and Advanced Analytics
- Core Focus: Azure Databricks excels in advanced analytics and machine learning workflows. It provides a powerful environment for data scientists and data engineers to build and deploy complex models at scale.
- Unified Analytics Platform: Built on Apache Spark, Databricks allows users to process large datasets, perform real-time analytics, and run AI/ML models seamlessly.
- Machine Learning & AI: It integrates deeply with tools like MLflow and Azure Machine Learning, enabling sophisticated workflows for model training, hyperparameter tuning, and deployment.
| Feature | Azure Data Factory (ADF) | Azure Databricks |
| Primary Focus | Data Engineering: Data movement, ETL workflows, and orchestration | Data Science: AI, ML, and advanced analytics |
| Best for | Data Engineers building and automating data pipelines | Data Scientists building machine learning models and big data workflows |
| Processing Engine | Uses Azure Databricks, SSIS, and HDInsight for computation | Built on Apache Spark, offering distributed data processing |
| Machine Learning | Limited ML capabilities, mainly through Azure Machine Learning | Deep integration with Apache Spark, MLflow, and Azure ML |
| Data Preparation | Prepares data for ETL processing and integration | Handles data wrangling and ML feature engineering |
| Collaboration | Strong data integration and workflow collaboration | Unified environment for collaboration between data engineers and data scientists |
| Visualization Tools | Limited visualization capabilities, relies on Power BI for reporting | Offers Power BI integration for ML model outputs and visualizations |
Data Processing & Transformation Approach: Focused Comparison
When comparing Azure Data Factory (ADF) and Azure Databricks, it’s essential to focus on how both platforms handle data processing and data transformation—the backbone of any data pipeline. While both are built to move and transform data, they cater to different needs, tools, and processing styles.
Azure Data Factory: Orchestrating Low-Code Transformations
Azure Data Factory is primarily designed for data orchestration with an emphasis on low-code transformations. It provides an easy-to-use environment for defining, scheduling, and managing data workflows. ADF excels in moving data across multiple environments with minimal coding required, making it ideal for users who prefer a more visual and configurable approach to building data pipelines.
- ETL (Extract, Transform, Load) Model: ADF operates in the ETL paradigm, where transformations are applied before loading data into the destination system.
- Low-Code Design: Users can design transformations using a visual, low-code interface, particularly through Mapping Data Flows, where transformations like filtering, aggregating, and merging can be done without writing code.
- Batch Processing: ADF is optimized for batch-based data processing, suitable for scheduled and periodic data integration tasks, primarily focusing on structured data.
- Data Connectivity: ADF offers a wide range of built-in connectors to connect data sources and sinks, including relational databases, data lakes, and cloud services, allowing seamless data movement across multiple platforms.
- Data Transformation: For basic transformations, ADF relies on the Mapping Data Flows feature, providing an easy, visual way to transform structured and semi-structured data. Complex data transformations can be written with custom scripts (SQL, Python).
Azure Databricks: Advanced Big Data Processing with Code-First Transformations
Azure Databricks, built on Apache Spark, is tailored for high-performance, distributed data processing. It targets large-scale data transformations and is often used for advanced analytics, real-time processing, and machine learning workflows. Unlike ADF, Databricks requires a code-first approach, offering data engineers greater flexibility and power when performing complex transformations.
- ELT (Extract, Load, Transform) Model: Databricks operates in the ELT paradigm, where data is first loaded into storage (e.g., a data lake), and transformations are performed later using Spark’s distributed computing power.
- Code-First Approach: Databricks requires users to write transformations in Python, Scala, or SQL. This enables highly customizable and complex transformations that are ideal for data scientists and engineers with coding expertise.
- Real-Time and Batch Processing: Databricks excels in both batch processing and real-time data streaming. It’s optimized for scenarios involving large, unstructured data, where performance and scalability are critical.
- Distributed Data Processing: Powered by Apache Spark, Databricks distributes processing tasks across multiple nodes, which is essential for handling large datasets efficiently. It allows for parallel data processing, leading to faster transformation times.
- Advanced Transformations: With Databricks, users can perform advanced data cleansing, aggregation, and analysis, including machine learning model training directly within the platform, making it highly suited for big data analytics.
| Feature | Azure Data Factory (ADF) | Azure Databricks |
| Transformation Approach | Low-code ETL using Mapping Data Flows | Code-first ELT using Apache Spark |
| Data Transformation Style | Visual, pre-built transformations without code | Custom, code-based transformations with Python/Scala/SQL |
| Processing Mode | Primarily batch processing | Supports both batch and real-time streaming |
| Data Handling | Focus on structured and semi-structured data | Handles structured, semi-structured, and unstructured data |
| Real-Time Processing | Limited real-time capability; event-driven pipelines | Full support for real-time data streaming and processing |
| Transformation Flexibility | Restricted to visual transformations with built-in features | Highly flexible, supporting advanced and custom transformations |
Architecture & Workflow Execution
Building on the previous discussion around data processing and transformation, it’s crucial to understand how Azure Data Factory (ADF) and Azure Databricks handle architecture and workflow execution. The way each service structures and executes its workflows impacts how efficiently it can handle data transformation, movement, and orchestration tasks.
Azure Data Factory: Pipeline-Based Execution
Azure Data Factory (ADF) operates on a pipeline-based execution model, where users define workflows as a sequence of tasks, also known as activities. These pipelines help orchestrate data movement, transformation, and loading across different data stores and compute environments.
- Pipeline-Oriented Design: Workflows are created through pipelines, which can include sequential, parallel, or conditional activities that run based on specific triggers or schedules.
- Task Dependency Management: Tasks within the pipeline are connected in a specific order, with the output of one task often acting as the input for the next. These dependencies ensure proper sequencing and error handling.
- Visual Interface: ADF offers a low-code, visual interface for building these pipelines, making it easier to design and monitor workflows without requiring deep coding expertise.
- Workflow Execution: Pipelines can be executed on demand, on a schedule, or triggered by external events (e.g., file arrival, data availability).
Azure Databricks: Cluster-Based Execution
Azure Databricks takes a more flexible, code-first approach with a cluster-based execution model. It is designed to run distributed tasks on Apache Spark clusters, which allows for powerful parallel processing and high scalability.
- Cluster-Based Execution: Tasks in Databricks run on Spark clusters, which are groups of virtual machines that process data in parallel. The ability to dynamically allocate resources allows for high performance and efficient use of computing power.
- Job-Oriented Design: Workflows in Databricks are defined through jobs that can include multiple tasks, which are executed in a specified sequence. Jobs are often managed within notebooks or Databricks jobs.
- Task Dependency Handling: Task dependencies in Databricks are typically managed through notebooks, where the output of one task is passed as an input to the next. Complex workflows are handled via built-in tools for managing task sequencing.
- Execution Flexibility: Unlike ADF’s purely orchestrated pipelines, Databricks allows for much greater flexibility in execution, enabling on-demand job executions, scheduling, or real-time streaming based on the workflow design.
| Feature | Azure Data Factory (ADF) | Azure Databricks |
| Execution Model | Pipeline-based execution for orchestrating tasks | Cluster-based execution using Apache Spark for distributed processing |
| Workflow Dependency Handling | Tasks are connected sequentially or in parallel with dependencies | Dependencies handled within notebooks or jobs |
| Task Scheduling | Pipelines are scheduled or triggered by events | Jobs are run on demand or scheduled within notebooks or clusters |
| Workflow Execution Flexibility | Visual, low-code interface for easy workflow creation | Code-first execution with high flexibility for complex workflows |
| Complexity of Execution | Simple pipeline orchestration with a visual design | More complex; requires code execution and cluster management |
| Execution Triggers | Triggered by events (e.g., file arrival) or schedules | Jobs triggered by code execution or cluster events |
Performance & Scalability
When dealing with large datasets and high-volume data processing, both Azure Data Factory (ADF) and Azure Databricks offer robust features. However, each service approaches performance, scalability differently.
Azure Data Factory: Parallel Execution for Large Datasets
Azure Data Factory is optimized for data orchestration and can handle large datasets efficiently through parallel execution in its pipelines. It utilizes different integration runtimes and compute environments (like Azure HDInsight or Azure Databricks) to perform data processing tasks in parallel.
Data Movement Speed:
- Handles approximately 10–100 MB/sec per pipeline.
- On average, ADF can process 1 TB of data in about 2–4 hours, depending on pipeline complexity and integration runtime configuration.
Parallel Execution Capacity:
- Supports up to 50 concurrent data flows per pipeline.
- Can orchestrate workflows across 10–20 compute environments (like HDInsight, Azure SQL, or even Databricks itself) in parallel.
Compute Scaling:
- Manual scaling via Integration Runtimes.
- Maximum of 256 cores per integration runtime.
- Can handle datasets up to 100 TB with proper partitioning and parallelism.
Latency:
- Average pipeline orchestration latency: 30–90 seconds.
- Data transformation latency: typically 1–5 minutes per task depending on complexity.
Azure Databricks: Distributed Computing for Big Data
Azure Databricks, leveraging Apache Spark, excels in distributed computing, enabling the handling of big data and advanced analytics at scale. It allows massively parallel processing of datasets across multiple machines in a cluster, making it ideal for highly complex and high-volume data workloads.
Data Processing Speed:
- Can process 1 TB of data in approximately 10–20 minutes.
- Designed to handle up to 1 petabyte (PB) of data in a single cluster.
Distributed Processing:
- Clusters scale from 2 to 100+ nodes automatically.
- Supports simultaneous processing of multiple petabyte-scale datasets.
Cluster Scaling:
- Auto-scales clusters based on workload (no manual intervention needed).
- Most enterprise workloads run optimally with 16–64 nodes.
- Scaling up to 1000+ nodes is possible for extreme big data scenarios.
Performance Benchmarks:
- Achieves up to 10x faster processing than traditional big data frameworks.
- Reduces data processing times by up to 90% compared to legacy ETL systems.
- Supports advanced tuning (caching, partitioning, adaptive query execution) to further optimize heavy workloads.
| Feature | Azure Data Factory (ADF) | Azure Databricks |
| Data Movement / Processing Speed | 10–100 MB/sec (data movement) | 1 TB processed in 10–20 minutes |
| Parallelism Limit | 50 concurrent data flows per pipeline | Distributed across 1000+ nodes, enabling massive parallelism |
| Max Dataset Handling | Handles up to 100 TB per pipeline | Handles up to 1 PB+ in a single cluster |
| Compute Scaling | Manual scaling (up to 256 cores via Integration Runtime) | Auto-scaling clusters (2–1000+ nodes) |
| Performance Tuning Features | Optimized via parallel execution and integration runtime tuning | Advanced Spark optimizations like caching, partitioning, and adaptive query execution |
Data Governance & Metadata Management
Understanding how Azure Data Factory and Azure Databricks handle data governance, metadata, and lineage is essential, especially for enterprise-grade environments where compliance, auditing, and data quality are key concerns.
Azure Data Factory: Basic Governance & Lineage Capabilities
ADF offers fundamental governance and metadata management, primarily focusing on lineage tracking and data catalog integration to maintain visibility during data movement and orchestration.
- Metadata Tracking: Provides basic lineage for data movement across different data sources and sinks, helping users trace data flow within pipelines.
- Catalog Integration: Integrates with Azure Purview (now part of Microsoft Purview) to extend data discovery, classification, and governance capabilities.
- Governance Scope: While helpful for pipeline-level metadata, ADF has limited in-built data quality enforcement and lacks advanced versioning features compared to Databricks.
Azure Databricks: Advanced Governance & Data Management
Databricks provides a more comprehensive approach to governance, versioning, and metadata management, thanks to its integration with Delta Lake and strong access control mechanisms.
- Delta Lake Integration: Offers data versioning, time travel, and schema enforcement, which are critical for ensuring consistency and auditability of big data workloads.
- Fine-Grained Access Control: Supports role-based access control (RBAC), attribute-based access control (ABAC), and table-level security, providing tighter governance.
- Data Lineage & Quality: Provides complete data lineage, not just for movement but for in-cluster transformations, with built-in support for data quality constraints (e.g., constraints, expectations).
- Unified Governance with Unity Catalog: Databricks integrates Unity Catalog to centralize metadata, access control, and lineage tracking across all Databricks assets.
| Metric | Azure Data Factory | Azure Databricks |
| Data Lineage | Basic lineage tracking for data movement | End-to-end lineage including transformation, movement, and versioning via Delta Lake & Unity Catalog |
| Metadata Management | Limited native metadata handling, extendable via Azure Purview | Centralized metadata management through Delta Lake and Unity Catalog |
| Data Versioning | Not natively supported | Supported via Delta Lake (Time Travel, ACID Transactions) |
| Data Quality Enforcement | Relies on external tools or manual implementation | Built-in support for schema enforcement, constraints, and data quality rules |
| Access Control | Role-based access via Azure RBAC | Fine-grained access control (Row/Column-Level Security, Attribute-Based Access Control) |
| Audit & Compliance | Basic logging and monitoring via Azure Monitor & Purview | Detailed auditing, change tracking, and compliance support through Unity Catalog and Spark logs |
Integration & Connectivity
Both Azure Data Factory (ADF) and Azure Databricks offer powerful integration capabilities, but they are designed to serve different needs. Let's dive into how they differ in terms of connectivity, hybrid and multi-cloud support, and native integration with other Azure services.
Azure Data Factory: Extensive Connector Library
- Connector Ecosystem: ADF offers over 90+ pre-built connectors to various data sources, ranging from on-premises databases and cloud storage systems to SaaS applications like Salesforce or Google BigQuery. This extensive library makes it an excellent choice for organizations with heterogeneous data environments.
- Data Movement and Orchestration: ADF is optimized for data movement and can connect to a wide variety of sources. It offers an intuitive way to orchestrate data workflows between these sources, ensuring smooth integration between cloud and on-premises systems.
Azure Databricks: Deep Machine Learning & AI Integration
- AI/ML-Focused: Databricks is particularly strong in integrating with machine learning models and big data analytics pipelines. It integrates deeply with tools like Apache Spark, MLflow, and Delta Lake, providing a unified environment for data scientists and data engineers.
- Built for Advanced Analytics: If your data workflow requires AI/ML integration, Databricks is the clear winner. It allows you to seamlessly connect to Azure Machine Learning and run complex models at scale, leveraging its distributed computing capabilities.
Hybrid & Multi-Cloud Support: Flexibility in Deployment
- Azure Data Factory: ADF supports hybrid and multi-cloud environments, meaning it can easily connect to data sources across Azure, AWS, Google Cloud, and on-premises systems. This flexibility makes it a perfect choice for organizations with a multi-cloud strategy or those migrating from legacy systems to the cloud.
- Azure Databricks: While Databricks also supports multi-cloud environments (Azure, AWS, GCP), it is more tightly integrated with Azure services. Organizations that are heavily invested in the Azure ecosystem can take advantage of Azure Databricks's ability to work seamlessly with Azure Data Lake, Azure Synapse, and other native Azure services, while also being able to operate on AWS or Google Cloud.
Native Integration with Other Azure Services
- Azure Data Factory: ADF integrates natively with various Azure services like Azure SQL Database, Azure Data Lake, Azure Blob Storage, Azure Synapse, and Azure Machine Learning. This makes it a solid choice for organizations looking to build end-to-end data pipelines within the Azure ecosystem.
- Azure Databricks: Databricks is tightly integrated with Azure services like Azure Data Lake, Azure Synapse, Azure Machine Learning, and Power BI. It leverages Delta Lake for data lakehouse architecture and integrates well with Azure’s analytics tools, allowing data scientists to scale ML models and run data-intensive queries directly in the cloud.
| Feature | Azure Data Factory (ADF) | Azure Databricks |
| Connector Library | 90+ built-in connectors for diverse cloud and on-prem sources | Primarily focused on AI/ML and big data connectors |
| Hybrid & Multi-Cloud Support | Extensive support for multi-cloud and hybrid environments | Primarily optimized for Azure, but also supports multi-cloud |
| AI/ML Integration | Limited integration for ML/AI, mainly through Azure ML | Deep AI/ML integration with Apache Spark, MLflow, and Delta Lake |
| Native Azure Integration | Strong integration with Azure services like Azure SQL and Synapse | Deep integration with Azure Data Lake, Azure Synapse, and Azure ML |
Security & Compliance: Do the Differences Matter?
While both Azure Data Factory (ADF) and Azure Databricks provide robust security and compliance measures, the specifics of their implementation vary. Understanding these critical differences is crucial for enterprises where data protection is paramount.
Azure Data Factory: Security Focused on Data Movement
- Data Encryption: ADF ensures encryption of data both at rest and in transit. It also supports Azure Active Directory (Azure AD) for access control, providing enterprise-grade security.
- Regulatory Compliance: ADF complies with global standards like GDPR, ISO, and HIPAA, making it a strong choice for organizations with regulated data.
- Granular Access Control: ADF offers fine-grained access control through Azure Role-Based Access Control (RBAC) and integrates with Key Vault for managing credentials.
Azure Databricks: Security for Big Data Workflows and ML Models
- Distributed Security: As a big data platform, Databricks inherits Azure security features, such as network security, private IP support, and Azure AD for managing user access across clusters.
- Advanced Encryption: Databricks supports encryption for both data in transit and data at rest, especially important when processing large-scale datasets or running sensitive ML models.
- Compliance Certifications: Like ADF, Databricks meets various regulatory standards, including GDPR and SOC 2, ensuring that enterprise workflows and data science operations are secure and compliant.
Choosing the Right Tool for Different Scenarios
When choosing between Azure Data Factory (ADF) and Azure Databricks, it's important to match the tool to your specific needs. Both are powerful but are better suited to different types of data workflows and use cases. Here's how to determine the best choice based on your scenario:
Best Choice for ETL & Data Movement
- Azure Data Factory (ADF) is the go-to choice for ETL (Extract, Transform, Load) workflows. It specializes in data movement and orchestration across a wide range of systems. With over 90+ pre-built connectors, ADF makes it easy to integrate data across various cloud and on-premises platforms. If your primary need is to build data pipelines that automate the transfer and transformation of data, ADF is the more efficient and user-friendly option.
Best Choice for Big Data & ML Workloads
- Azure Databricks is built for handling big data and machine learning (ML) workflows. Powered by Apache Spark, it supports distributed computing for large-scale data processing and integrates with tools like MLflow for machine learning model management. If your project involves processing large datasets or developing advanced analytics and AI solutions, Databricks offers powerful features tailored for such use cases.
Best Choice for Hybrid & Multi-Cloud Deployments
- If your organization requires support for hybrid or multi-cloud environments, Azure Data Factory (ADF) is the better choice. ADF offers a wide range of connectors that enable integration across multiple cloud platforms (Azure, AWS, GCP) as well as on-premises systems. This makes it an ideal tool for organizations with a multi-cloud strategy or those transitioning from legacy systems. While Azure Databricks also supports multi-cloud environments, it is primarily optimized for Azure and might not offer the same level of flexibility for diverse cloud ecosystems.
Can They Work Together?
Absolutely! Many organizations use Azure Data Factory (ADF) and Azure Databricks together to create a more powerful and comprehensive data workflow.
- Azure Data Factory excels at orchestrating data movement and transformation across various data sources, whether on-premises or in the cloud. It can handle the ETL/ELT processes and efficiently move data across platforms, preparing it for the next steps.
- Once the data is prepared and moved, Azure Databricks steps in for advanced analytics, machine learning, and big data processing. Leveraging Apache Spark and its integration with MLflow and Delta Lake, Databricks handles complex data processing and provides a unified environment for data scientists to build and deploy models at scale.
This complementary approach allows organizations to leverage the strengths of both tools for end-to-end data workflows, from data ingestion to advanced analytics and AI-driven insights.
Final Thoughts: Making an Informed Decision
Choosing between Azure Data Factory (ADF) and Azure Databricks isn't about finding a universal winner but selecting the right tool for your specific needs. Consider the following factors when making your decision:
- Data Volume: For smaller, simpler workflows, ADF may suffice. However, for large-scale data processing and high-volume workloads, Databricks may be the better choice due to its distributed computing capabilities.
- Processing Complexity: If you need to perform advanced transformations or machine learning, Databricks is the go-to tool. For more straightforward ETL/ELT workflows, ADF provides a more intuitive solution.
- Team’s Skill Set: Consider the technical expertise of your team. ADF is easier for non-technical users due to its low-code interface, while Databricks is more suited for data scientists and engineers with experience in distributed computing and machine learning.
Pro Tip: Start small, experiment with both services based on your needs, and don’t hesitate to combine ADF and Databricks for a comprehensive data strategy. Both tools can work seamlessly together, and using them in tandem allows you to get the best of both worlds—efficient data movement and advanced analytics.






