
What is Azure Data Factory (ADF)?
Source - Azure
Data is the backbone of modern businesses, but managing it efficiently is often a challenge. Organizations collect data from multiple sources—databases, APIs, on-premises systems, and cloud platforms—but without a streamlined process, this data remains scattered and unusable.
Azure Data Factory (ADF) simplifies this by acting as a cloud-based data integration service that enables seamless movement, transformation, and orchestration of data workflows. It helps businesses consolidate data across multiple systems, ensuring it is available in the right place, at the right time, and in the right format.
Unlike traditional ETL tools, ADF provides flexibility by supporting both Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) approaches, making it adaptable to various data needs. Whether you are working with structured or unstructured data, ADF allows you to build scalable data pipelines with minimal operational effort.
Overcoming Data Integration Challenges with Azure Data Factory
As businesses scale, their data ecosystems grow more complex. It’s no longer just about collecting data—it’s about integrating, transforming, and delivering it efficiently for decision-making and analytics. Organizations must manage data from multiple sources, each with different structures, formats, and processing requirements. Without a well-designed integration strategy, this complexity can slow down operations, increase costs, and create compliance risks.
Azure Data Factory (ADF) is built to address these challenges by providing a scalable, automated, and secure data integration platform. Let’s examine the most pressing data integration challenges and how ADF offers effective solutions.
The Growing Complexity of Data Integration
Modern businesses rely on data from a variety of platforms, including:
- Databases, CRM systems, and SaaS applications – Each uses different data models, making standardization essential.
- IoT devices and APIs – Continuous data streams require efficient ingestion and processing.
- Cloud and on-premises storage – Hybrid architectures demand seamless data movement and synchronization.
As the volume, velocity, and variety of data increase, organizations need integration solutions that can handle these complexities without excessive operational overhead.
Key Challenges in Data Integration
- Scalability and Performance
As data volumes grow, traditional ETL pipelines often struggle with slow processing times and require costly infrastructure scaling. Businesses need an elastic, cloud-native solution that scales automatically. - Managing Diverse Data Formats
Data integration involves working with structured, semi-structured, and unstructured data. Manual transformations and custom scripts are difficult to maintain, leading to fragile pipelines. - Security and Compliance Risks
Sensitive data must be protected throughout the integration process. Organizations must comply with industry regulations such as GDPR, HIPAA, and SOC 2, ensuring encryption, access control, and accountability. - Latency and Real-Time Processing
Many industries, such as finance, healthcare, and e-commerce, require real-time or near-real-time data processing. Achieving low-latency integration without bottlenecks is a challenge for many legacy systems. - Operational Overhead
Traditional data pipelines require constant monitoring, troubleshooting, and manual intervention. This slows down innovation and increases maintenance costs.
Simply put, data is only as valuable as its usability. Without an efficient integration solution, businesses struggle to keep up with data complexity, leading to inefficient operations and missed insights.
How Does Azure Data Factory Solve These Challenges?
Azure Data Factory streamlines data integration through automation, scalability, and a broad set of built-in capabilities:
- Automated Data Movement – Enables scheduled or event-driven data transfers between on-premises, cloud, and third-party sources, eliminating manual intervention.
- Scalable, Serverless Architecture – Dynamically adjusts compute resources based on workload, optimizing performance without infrastructure management.
- Extensive Connectivity – Supports over 90 built-in connectors, allowing seamless integration with databases, cloud storage, SaaS platforms, and APIs.
- Simplified Data Transformation – Provides low-code and no-code tools to clean, aggregate, and reshape data, reducing dependency on custom scripting.
- Hybrid Data Integration – Enables secure, high-speed transfers between on-premises and cloud environments, ensuring smooth data synchronization.
- Comprehensive Monitoring and Logging – Built-in dashboards and alerts provide real-time visibility into pipeline performance, enabling proactive issue resolution.
- Enterprise-Grade Security – Includes end-to-end encryption, role-based access control, and compliance-ready features to safeguard sensitive data.
By leveraging ADF, businesses can move beyond traditional data integration struggles and build scalable, automated workflows that deliver real-time, actionable insights while reducing operational costs.
Key Components of Azure Data Factory
Azure Data Factory (ADF) is designed with a structured yet flexible architecture, allowing businesses to move, transform, and orchestrate data workflows efficiently.
To build an effective data integration strategy with ADF, it’s essential to understand its core components. Each element uniquely ensures seamless data flow across on-premises, cloud, and third-party systems.
Pipelines – The Blueprint for Data Movement
A pipeline in ADF is more than just a sequence of tasks—it’s the foundation of data orchestration. It defines the flow of data from its source to its destination, along with any transformation that needs to happen.
- Pipelines allow businesses to automate and manage data workflows efficiently.
- A single pipeline can include multiple activities that work together to extract, process, and load data.
- Pipelines are designed for reusability, meaning businesses can optimize workflows without having to rebuild them for every new data integration.
By structuring pipelines effectively, organizations can ensure scalable and maintainable data workflows that adapt to evolving business needs.
Datasets – Structuring Data for Better Processing
A dataset in ADF is not just a representation of data—it defines how data should be interpreted and processed within a pipeline.
- Datasets act as a bridge between a pipeline and the actual data, helping maintain data integrity and schema consistency.
- They define the format, structure, and location of the data, ensuring that different activities within the pipeline can process it correctly.
- A dataset can represent a table in an Azure SQL Database, a CSV file in Azure Blob Storage, or even a response from a REST API.
Businesses can standardize their data workflows by using well-defined datasets, making them more reliable and easier to maintain.
Activities – The Actions That Drive Data Processing
Activities within a pipeline define what happens to the data. They can range from simple data transfers to complex transformations and control logic.
Types of Activities in ADF:
- Data Movement Activities – Responsible for copying data from one system to another.
- Data Transformation Activities – Apply processing rules, such as filtering, aggregating, or joining datasets before loading.
- Control Flow Activities – Manage the execution logic of a pipeline, such as conditional branching and looping.
Each activity plays a crucial role in shaping how data is processed and delivered, enabling businesses to automate workflows without extensive manual intervention.
Linked Services – Connecting to Data Sources with Ease
A linked service acts as the connection point between Azure Data Factory and various data sources or destinations. It provides the necessary configuration and authentication details to ensure secure and seamless data integration.
- Linked services define where and how data is accessed, whether it's an Azure SQL Database, Azure Blob Storage, or an external API.
- They eliminate repetitive connection setups, making pipelines more efficient and manageable.
- ADF supports 90+ built-in connectors, allowing businesses to connect to a vast range of cloud, on-premises, and third-party data sources without additional development effort.
Using linked services effectively ensures that data pipelines remain secure, scalable, and easy to maintain.
Integration Runtimes – Powering Hybrid and Cloud Execution
Integration runtimes (IR) serve as the execution engine for ADF, determining how and where data processing takes place. The right integration runtime ensures efficient data movement and transformation based on business needs.
Types of Integration Runtimes:
- Azure Integration Runtime – A fully managed service for cloud-based data movement and transformation.
- Self-Hosted Integration Runtime – Enables on-premises data processing while maintaining security and compliance.
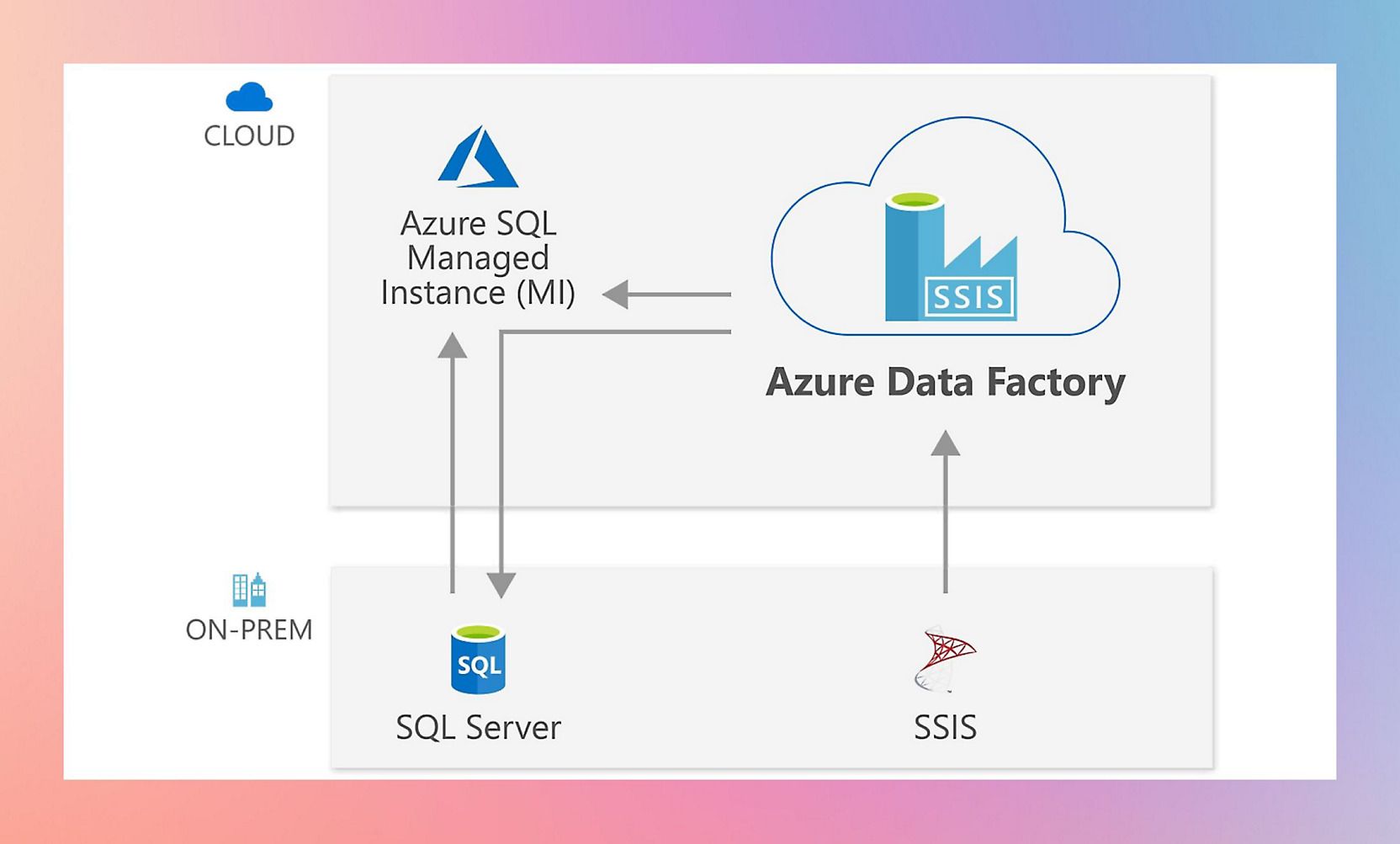
- SSIS Integration Runtime – Allows businesses to run existing SQL Server Integration Services (SSIS) packages within ADF without requiring major modifications.
Selecting the right integration runtime helps businesses balance performance, security, and cost-efficiency when integrating data across different environments.
How Does ADF Fit into the Azure Ecosystem?
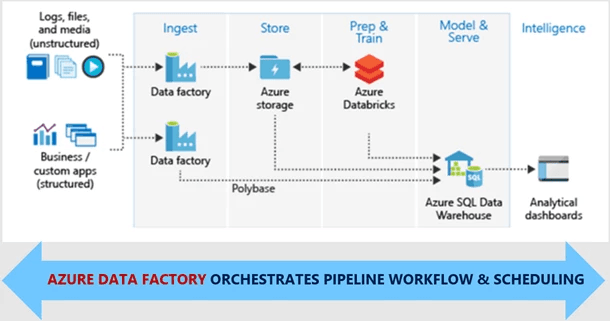
Azure Data Factory is not a standalone tool—it’s a key part of Microsoft’s broader data ecosystem. Its true power comes from how well it integrates with other Azure services to create an end-to-end data pipeline.
- Azure Data Lake Storage (ADLS) – ADF can read from and write to ADLS, allowing businesses to store vast amounts of raw and processed data efficiently.
- Azure Synapse Analytics – Data processed through ADF can be analyzed in Synapse, supporting complex queries and large-scale analytics.
- Azure Databricks – For businesses working with big data, ADF can integrate with Databricks to run advanced machine learning and data processing tasks.
- Azure Logic Apps & Functions – These services help trigger ADF pipelines dynamically, enabling real-time workflows based on business events.
This deep integration makes ADF more than just a data pipeline tool—it serves as the foundation for a comprehensive, cloud-based data strategy that supports reporting, analytics, and AI-driven decision-making.
Building Your First Pipeline
Creating your first pipeline in Azure Data Factory (ADF) may seem like a daunting task, but by following a clear, structured approach, you can quickly set up a functional data integration workflow.
Create an Azure Data Factory Instance in the Azure Portal
Before you can start building pipelines, you’ll need to set up your Azure Data Factory instance. Here’s how:
Step 1: Log in to the Azure Portal – Open your browser and navigate to the Azure portal. Log in with your credentials.
Step 2: Create a Data Factory Instance – In the search bar, type “Data Factory” and select Azure Data Factory. Click Create to begin the instance creation process.
- Fill in the necessary details like Subscription, Resource Group, Region, and Name for your Data Factory.
- Click Review + Create and then click Create to deploy the new Data Factory instance.
Step 3: Open the Data Factory Studio – Once your instance is created, go to the Data Factory Studio to start building your pipeline by clicking on Author & Monitor.
Define Linked Services to Connect Your Data Sources and Destinations
Linked Services act as connection strings, defining how to connect to your data sources and destinations. ADF supports numerous data connectors, such as Azure Blob Storage, Azure SQL Database, and many third-party systems.
Step 1: Create a Linked Service
- In the ADF Studio, navigate to the Manage tab and select Linked Services.
- Click + New and select the data source or destination you want to connect to (e.g., Azure Blob Storage).
Step 2: Configure the Linked Service
- Fill in the connection details, such as the authentication method (e.g., service principal or managed identity), endpoint, and credentials required to access the data.
- Test the connection to ensure that ADF can securely connect to your data source.
Step 3: Save and Close
After configuring, save the Linked Service, and it will be available for use within your pipeline.
Create Datasets to Structure Your Source and Destination Data
Datasets represent the schema and structure of the data you are working with, helping ADF understand how to process data within a pipeline. You need a dataset for both your source (where the data is coming from) and your destination (where the data is going).
Step 1: Create a Source Dataset
- In the Author tab of the ADF Studio, go to Datasets and click + New.
- Select the data store type (e.g., Azure Blob Storage, SQL Server) and configure the connection using the Linked Service you created earlier.
- Specify the file path or table name and any schema details (e.g., column names, types for a table).
Step 2: Create a Destination Dataset
- Similarly, create a destination dataset to specify where the data will be loaded (e.g., another Azure Blob Storage container or an SQL database table).
- Define the data format and schema in this dataset. This step ensures that ADF knows how to write the data to the destination in the correct structure.
Add Activities for Data Movement or Transformation
Activities within a pipeline are the individual tasks that define what will happen to the data as it flows from source to destination. Common activities include data movement, data transformation, and data loading.
Step 1: Add a Copy Data Activity (for Data Movement)
- In your pipeline, click the + icon and select the Copy Data activity. This is the most common activity for transferring data from one location to another.
- In the activity settings, define the source dataset (the data you want to copy) and the destination dataset (where the data should be loaded).
- You can also configure data transformations here if needed (e.g., data type conversions or filters).
Step 2: Add Data Transformation Activities
- If your pipeline needs to transform data (e.g., aggregate, filter, join), you can add a Data Flow activity.
- A Data Flow allows you to visually design and define data transformations. You can apply multiple transformations in sequence, such as filtering rows, adding computed columns, or joining datasets.
Test and Publish Your Pipeline for Execution
Before running your pipeline, you need to test it to ensure everything is configured correctly and works as expected.
Step 1: Test Your Pipeline
- In the Pipeline tab, click on your pipeline to open the details view.
- Click Debug to run the pipeline in a test environment. This step will allow you to validate if the pipeline can successfully move and transform data between your source and destination.
- Review the output in the monitoring section to ensure there are no errors. If there are any issues, adjust the pipeline activities accordingly.
Step 2: Publish the Pipeline
- Once your pipeline runs successfully in the test environment, click Publish All to make the pipeline live.
- Publishing ensures that your pipeline is ready for scheduled or triggered execution in a production environment.
Connecting to Different Data Sources
Azure Data Factory (ADF) is designed to handle a broad range of sources, from cloud-based storage to on-premises databases and third-party SaaS applications. By providing seamless connectivity, ADF enables businesses to unify their data and build more powerful analytics and AI-driven solutions.
Cloud-Based Data Sources: Optimized for Scalability
Modern businesses rely heavily on cloud storage and databases for flexible, scalable data management. ADF natively integrates with key Azure data services, ensuring fast, secure, and reliable data movement across cloud environments.
- Azure SQL Database: ADF connects directly to Azure SQL Database, enabling the movement of structured data with minimal configuration. Whether it’s transactional records or reporting tables, ADF ensures smooth ingestion and transformation.
- Azure Blob Storage: For unstructured or semi-structured data (e.g., CSV, JSON, Parquet), ADF integrates with Azure Blob Storage to facilitate easy data extraction, loading, and processing.
- Azure Synapse Analytics: Handling large-scale analytics workloads? ADF enables seamless data transfer to Azure Synapse Analytics, ensuring optimized performance for big data processing and advanced analytics.
By leveraging ADF’s cloud integrations, organizations can create highly scalable and cost-efficient data pipelines, making it easier to manage real-time analytics and AI-driven insights.
On-Premises Data Sources: Bridging Legacy Systems and the Cloud
Not all data lives in the cloud. Many organizations still rely on on-premises databases and legacy systems, creating challenges for integration and modernization. ADF addresses this with the Self-Hosted Integration Runtime (SHIR), enabling secure data transfer between on-prem and cloud environments.
- Secure Connectivity: SHIR allows ADF to interact with SQL Server, Oracle, Teradata, SAP, and even flat files stored in on-prem systems—without exposing sensitive data to the public internet.
- Real-Time and Scheduled Transfers: Businesses can synchronize data at intervals or in near real-time, ensuring that cloud-based analytics platforms always have up-to-date information.
- Regulatory Compliance: By keeping sensitive data within internal networks while still enabling cloud integration, ADF helps businesses adhere to compliance policies such as GDPR, HIPAA, and SOC 2.
With SHIR, companies don’t need to migrate everything to the cloud at once—they can modernize incrementally while maintaining their existing infrastructure.
SaaS Applications: Unifying Data Across Business Platforms
Enterprises today use a mix of third-party SaaS applications for customer relationship management (CRM), enterprise resource planning (ERP), and marketing automation. ADF makes it easy to integrate these external platforms into centralized data processing workflows.
- Salesforce: Extract customer, sales, and transaction data from Salesforce and move it into Azure for advanced analytics, reporting, or AI-driven insights.
- Microsoft Dynamics 365: Sync business-critical data from Dynamics 365’s ERP and CRM systems to Azure, ensuring a unified data warehouse for decision-making.
By connecting SaaS applications with cloud and on-prem data sources, ADF allows organizations to automate workflows, eliminate data silos, and improve operational efficiency.
Running and Monitoring Your Pipeline – Ensuring Smooth Execution
Once you’ve created your pipeline, the next critical step is ensuring it runs effectively and efficiently. Azure Data Factory provides a range of tools for monitoring and debugging to help maintain optimal performance.
1. Use the ADF Monitoring Dashboard to Track Pipeline Runs
The ADF Monitoring Dashboard is the central hub where you can view the status of pipeline runs, track progress, and analyze any potential issues that arise.
- Pipeline Monitoring: This tool allows you to view real-time status updates, including successful runs, failures, and in-progress activities.
- Run History: You can track all past runs and analyze execution times, resource usage, and overall pipeline performance. This is crucial for identifying trends and potential areas for improvement.
The monitoring dashboard provides a comprehensive overview of your pipelines, enabling data engineers to stay on top of operations.
2. Set Up Alerts and Logging for Proactive Monitoring
To ensure your data pipelines are running smoothly without manual intervention, alerts and logging are essential:
- Alerts: You can set up email notifications, webhooks, or Azure Monitor alerts to notify you when specific pipeline conditions are met (e.g., when a pipeline fails or succeeds). This enables you to take quick action and address issues before they impact your operations.
- Logging: ADF also supports detailed logging, allowing you to capture logs of all activities within your pipeline. These logs help you understand the performance of your activities and identify bottlenecks or failures.
With these monitoring and alerting tools in place, you can ensure that your data workflows remain uninterrupted and are optimized over time.
3. Debug Issues Using the Activity Run History
If a pipeline run encounters issues, ADF provides powerful debugging tools through the Activity Run History:
- Activity Run History: This feature allows you to drill down into each activity’s run details within a pipeline. You can identify which specific step failed, review the input/output data, and check error messages or logs to determine the root cause.
- Error Handling: The history also provides insights into retry mechanisms or error-handling configurations, helping you troubleshoot or adjust pipeline activities accordingly.
With Activity Run History, you can quickly resolve issues, reduce downtime, and improve the reliability of your data processes.
Data Transformation in ADF
Azure Data Factory (ADF) provides powerful transformation capabilities through Mapping Data Flows and Wrangling Data Flows, allowing businesses to process data efficiently without complex coding.
Mapping Data Flows: Scalable, Code-Free Data Transformation
Mapping Data Flows provide a visual, drag-and-drop interface for designing transformation logic. Built on Apache Spark, these flows are optimized for large-scale data processing without requiring users to write extensive code.
Key Features:
- Perform operations like joins, aggregations, lookups, and filtering in a no-code environment.
- Handle schema drift, allowing pipelines to adapt to changing data structures automatically.
- Optimize execution with partitioning strategies and built-in performance tuning.
When to Use Mapping Data Flows:
- When working with structured or semi-structured data from various sources.
- When requiring visual data transformation tools without managing Spark clusters.
- When performance and scalability are priorities, especially with large datasets.
Mapping Data Flows provide a low-code alternative to traditional ETL tools, making transformation more accessible while maintaining efficiency.
Wrangling Data Flows: Self-Service Data Preparation for Business Users
For business analysts and non-technical users, Wrangling Data Flows (powered by Power Query) offer a familiar, Excel-like interface for interactive data preparation.
Key Features:
- Allows users to clean, filter, and reshape data without writing code.
- Automatically converts transformation logic into a structured process.
- Best suited for interactive exploration and ad-hoc transformations.
When to Use Wrangling Data Flows:
- When business users need an easy way to prepare data without engineering support.
- When dealing with semi-structured data formats such as Excel, JSON, or CSV.
- When transformations are one-time or occasional rather than automated.
Wrangling Data Flows provide a self-service approach to data transformation, making it easier for teams to prepare data for reporting and analytics without extensive technical expertise.
Orchestration and Automation
Source - Azure
Azure Data Factory (ADF) provides powerful orchestration and automation capabilities, allowing businesses to optimize their data pipelines for efficiency and scalability.
Scheduling Pipelines for Automated Execution
Manually running data pipelines is inefficient, especially for recurring processes. ADF offers triggers that automate pipeline execution based on predefined conditions.
Types of Triggers:
- Time-Based Triggers: Schedule pipelines to run at fixed intervals (e.g., daily, hourly, or weekly).
- Event-Driven Triggers: Trigger pipelines when specific events occur, such as new files arriving in Azure Blob Storage.
- Manual Execution: Run pipelines on-demand when needed.
Using the right scheduling strategy ensures timely data processing while reducing manual intervention.
Handling Errors and Ensuring Resilience
Failures can occur due to network issues, API timeouts, or data inconsistencies. ADF provides robust error-handling mechanisms to minimize disruptions.
Best Practices for Error Handling:
- Retry Policies: Configure retries for transient failures, ensuring automatic reattempts before marking the pipeline as failed.
- Failover Mechanisms: Implement redundancy by using multiple data sources or alternative processing methods.
- Error Logging & Alerts: Capture detailed logs and set up alerts to quickly diagnose issues when they arise.
By designing fault-tolerant pipelines, businesses can maintain high availability and minimize downtime.
Real-Time Monitoring and Logging
To ensure pipelines are running efficiently, ADF provides built-in monitoring and logging tools for tracking performance and troubleshooting issues.
Key Monitoring Features:
- Azure Monitor Integration: View pipeline execution logs, latency, and success/failure rates.
- Activity Run History: Inspect past runs to identify patterns and optimize performance.
- Custom Alerts: Set up notifications for failures or performance anomalies to proactively resolve issues.
With real-time visibility, teams can ensure pipeline reliability and optimize performance based on historical trends.
Security and Access Control in ADF
Data security is a top priority, especially when dealing with sensitive business and customer data. ADF follows Azure’s enterprise-grade security model, providing role-based access, encryption, and compliance features.
Role-Based Access Control (RBAC):
- Reader: Can view pipeline configurations but cannot make changes.
- Contributor: Can modify pipelines but lacks administrative control.
- Owner: Full control over ADF resources, including security settings.
Applying least-privilege access principles ensures that only authorized users can modify critical workflows.
Data Encryption and Compliance:
- Uses Azure Key Vault to store and manage secrets, API keys, and database credentials securely.
- Compliance with industry standards like GDPR, HIPAA, and SOC ensures that data processing meets regulatory requirements.
Secure Credential Management:
- Instead of hardcoding credentials, use Managed Identity and Linked Services for secure authentication.
- Ensures sensitive connection details are protected from unauthorized access.
By implementing strong access controls and encryption, businesses can protect sensitive data while maintaining regulatory compliance.
Troubleshooting Common Issues
No matter how well you design a data pipeline, challenges are bound to arise. Whether it's a failed connection, slow performance, or unexpected transformations, knowing how to troubleshoot common issues can save time and prevent disruptions.
Here’s a guide to overcoming some of the most frequent roadblocks in Azure Data Factory (ADF).
Connectivity Issues: When Your Pipeline Can’t Reach the Data Source
The Problem: Your pipeline fails because ADF can't connect to the data source. This could be due to incorrect credentials, network restrictions, or the source system being down.
How to Fix It:
- Double-check the authentication details in Linked Services and update expired credentials.
- If working with on-premises data, ensure your Self-hosted Integration Runtime (IR) is running and accessible.
- Review firewall settings and allow ADF’s IP addresses if needed.
- Test the connection within ADF before running the pipeline to catch issues early.
Slow Data Movement: Why Is Pipeline Taking So Long?
The Problem: Your pipeline runs, but it’s moving data much slower than expected.
Possible Reasons:
- Transferring large datasets without optimizing for performance.
- Data store limitations, such as API rate limits or bandwidth constraints.
- Running operations sequentially instead of in parallel.
How to Fix It:
- Enable parallel copy in the Copy Activity settings to move data faster.
- If using large files, switch to optimized formats like Parquet instead of CSV.
- Adjust the concurrency settings to process multiple files or records at once.
- Check for bottlenecks in the source or destination systems—sometimes the slowdown isn’t in ADF but in the data store itself.
Unexpected Data Transformations: Why Doesn’t My Data Look Right?
The Problem: The data arriving at the destination doesn’t match what you expected—values are missing, data types are incorrect, or transformations aren’t working as intended.
How to Fix It:
- Use the Data Preview feature in Mapping Data Flows to check transformations before running the pipeline.
- Enable Schema Drift if your data structure changes frequently.
- Verify that data types are correctly mapped between source and destination.
- If an expression or function isn’t behaving as expected, try simplifying it and testing in smaller steps.
Integration Runtime (IR) Failures: Why Is My Pipeline Not Running?
The Problem: Your pipeline depends on a Self-hosted Integration Runtime, but it’s either failing or unavailable.
How to Fix It:
- Open the Integration Runtime configuration and check if the service is running. Restart it if needed.
- Make sure your IR is updated to the latest version.
- If the machine hosting the IR is under heavy load, allocate more CPU and memory to improve performance.
Debugging and Monitoring Pipelines Effectively
Even when everything seems to be working, it’s important to monitor and debug proactively to catch potential issues before they escalate.
Best Practices:
- Use the ADF Monitoring Dashboard to track pipeline executions and identify failures.
- Set up alerts and logging so you’re notified of failures instead of finding out after the fact.
- Use Retry Policies in pipeline activities to handle temporary issues automatically.
- Check the Activity Run History for error messages and suggested fixes.
Cost Optimization and Best Practices
Pipeline Orchestration and Execution
Pipelines in ADF consist of activities that perform data operations. Costs associated with pipelines are determined by:
- Activity Runs: Charges apply per activity execution. For example, as of the latest pricing, the cost is $0.00025 per activity run.
- Integration Runtime (IR) Hours: The compute resources required to execute activities are billed per hour. For instance, Azure-hosted IR is priced at $0.25 per hour.
Example Calculation:
If you have a pipeline with 5 activities, each running once daily for a month (30 days):
- Activity Runs: 5 activities × 30 days = 150 runs × $0.00025 = $0.0375
- IR Hours: Assuming each activity takes 10 minutes (0.1667 hours):
5 activities × 0.1667 hours × 30 days = 25 hours × $0.25 = $6.25
Total Monthly Cost: $0.0375 (activity runs) + $6.25 (IR hours) = $6.29
Data Flow Execution and Debugging
Data Flows enable data transformations at scale.
vCore Hours: Charges depend on the number of virtual cores (vCores) and execution duration. For example, a General Purpose Data Flow with 8 vCores is priced at $0.25 per vCore-hour.
Example Calculation:
For a Data Flow using 8 vCores running for 2 hours:
- vCore Hours: 8 vCores × 2 hours = 16 vCore-hours × $0.25 = $4.00
SQL Server Integration Services (SSIS) Integration Runtime
For running SSIS packages, costs vary based on the chosen virtual machine (VM) size
- Standard A4 v2 (4 cores, 8 GB RAM): Approximately $612.99 per month without Azure Hybrid Benefit.
- Enterprise D4 v3 (4 cores, 16 GB RAM): Approximately $1,490.66 per month without Azure Hybrid Benefit.
Note: Prices can be significantly reduced using the Azure Hybrid Benefit, which allows you to apply existing SQL Server licenses to Azure services.
Data Factory Operations
Additional charges may incur for operations such as:
- Read/Write Operations: $0.50 per 50,000 operations.
- Monitoring Operations: $0.25 per 50,000 run records retrieved.
Troubleshooting Common Issues
Even with careful configuration, Azure Data Factory (ADF) pipelines can encounter issues related to connectivity, performance, authentication, or execution failures. Here’s how to troubleshoot the most common problems:
Pipeline Failures: Identifying and Resolving Common Issues
Pipeline failures can arise from connectivity problems, incorrect configurations, or permission-related issues.
- Connection Timeouts
- Verify that the source and destination services are online and responsive.
- Increase timeout settings in Linked Services if the connection drops frequently.
- Enable retry policies to handle transient failures automatically
- Authentication and Permission Errors
- Ensure that ADF’s Managed Identity or Service Principal has the required RBAC permissions for data sources.
- Double-check credentials stored in Linked Services (e.g., expired tokens, incorrect access keys).
- For on-premises data, verify that firewall rules and network settings allow access.
- Data Format and Schema Mismatches
- Use data validation activities to check schema consistency before transformations.
- Implement error handling logic to redirect invalid data instead of failing the pipeline.
- Leverage Mapping Data Flows to standardize formats before processing.
- Activity Failures Due to Dependencies
- Review pipeline dependencies to ensure correct sequencing of activities.
- Implement wait activities to handle delays in data availability
- Enable debug mode to analyze execution logs and identify failure points.
- Connection Timeouts
Integration Runtime (IR) Issues: Resolving Connectivity and Performance Challenges
ADF uses Integration Runtime (IR) to connect to various data sources. Misconfigurations or resource limitations can impact performance.
- Self-Hosted IR Connectivity Problems
- Ensure that the Self-Hosted IR service is running and registered in ADF.
- Verify firewall and network settings to allow traffic between the IR and data sources.
- Check log files in the IR node to diagnose connection failures.
- Performance Bottlenecks in IR
- Scale out Self-Hosted IR by adding more nodes for better workload distribution.
- Increase the compute capacity of Azure IR for more intensive processing tasks.
- Virtual Network (VNet) Integration Challenges
- Confirm that Network Security Groups (NSGs) and route tables allow access to ADF.
- Verify Private Link configurations if using private endpoints for secure data movement.
- Self-Hosted IR Connectivity Problems
Performance Optimization: Tuning Data Pipelines for Efficiency
Inefficient data movement and transformation settings can lead to slow execution times and resource inefficiencies.
- Optimize Copy Activity Performance
- Enable parallel copy by partitioning large datasets.
- Use staging storage (e.g., Azure Blob Storage) for large cross-region transfers.
- Select the appropriate data integration format (Parquet, Avro) to optimize read/write performance.
- Enhance Mapping Data Flows
- Adjust Data Flow TTL settings to prevent unnecessary re-computations.
- Optimize dataset partitioning to process data in parallel instead of sequentially.
- Reduce unnecessary transformations by filtering and aggregating early in the data pipeline.
- Monitor and Tune Integration Runtime Usage
- Use Azure Monitor to analyze pipeline execution times and identify bottlenecks.
- Adjust the Integration Runtime size based on workload needs to avoid over- or under-utilization
- Optimize Copy Activity Performance
Debugging and Monitoring: Ensuring Pipeline Reliability
Effective monitoring helps detect potential failures early and simplifies troubleshooting.
- Use Azure Monitor and Log Analytics
- Set up real-time monitoring dashboards to track pipeline execution.
- Enable logging and diagnostic settings to capture detailed failure insights.
- Configure alerts for unexpected pipeline delays or errors.
- Implement Robust Error Handling
- Use try/catch patterns in ADF pipelines to capture and manage failures without stopping execution.
- Redirect failed activities to separate failure-handling paths for further investigation.
- Automate issue resolution using Logic Apps or Azure Functions for quick response.
- Use Azure Monitor and Log Analytics
By following these troubleshooting techniques, you can maintain stable, high-performing ADF pipelines, ensuring reliable data movement and transformation across your cloud and on-premises environments.
Advanced Use Cases and Real-World Scenarios
Handling Big Data with ADF
- Uses parallel processing for large-scale data movement.
Real-Time Data Movement with Event-Driven Triggers
- Supports Azure Event Grid and Logic Apps.
- Enables real-time analytics with minimal latency.
Hybrid Data Integration (On-Prem & Cloud)
- Connects on-prem databases with Azure Synapse & Data Lake.
Alternatives to Azure Data Factory
While Azure Data Factory (ADF) is a robust solution for orchestrating data movement and transformation, it is not the only tool available. Other Azure services may serve as complementary or alternative solutions depending on your specific needs—such as data complexity, real-time processing, or workflow automation.
| Tool | Best For | Key Advantages |
| SQL Server Integration Services (SSIS) | On-premises SQL Server ETL workloads | Tight integration with SQL Server, low-latency processing, and package-based ETL |
| Azure Logic Apps | Event-driven workflow automation | Low-code, easy-to-configure automation for SaaS integrations and real-time triggers |
| Azure Databricks | Large-scale data transformation, AI/ML workloads | Apache Spark-powered analytics, ideal for complex transformations and machine learning |
| Azure Synapse Analytics | Enterprise-scale data warehousing and analytics | Optimized for querying and analyzing massive datasets efficiently |
| Azure Data Factory (ADF) | Hybrid and cloud-based data movement and orchestration | Scalable, serverless ETL with 90+ connectors for seamless data integration |
Choosing the Right Tool for Your Data Integration Needs
- For SQL Server-Centric Workloads: SSIS remains a strong option for organizations deeply embedded in SQL Server ecosystems, providing a familiar ETL environment.
- For Real-Time Workflow Automation: Azure Logic Apps is an excellent choice when automating event-driven workflows, such as triggering processes based on file uploads or API calls.
- For Advanced Data Processing and AI: Azure Databricks is designed for big data processing, data engineering, and AI/ML applications, offering high-performance distributed computing.
- For Large-Scale Analytics: Azure Synapse Analytics provides optimized data warehousing capabilities, making it the go-to solution for organizations with extensive analytical workloads.
- For Hybrid and Cloud-Based Integration: ADF is ideal when businesses need to move, transform, and orchestrate data across on-premises and cloud environments without heavy infrastructure management.
Each of these tools has its strengths, and in many cases, they can be used together with ADF to build a comprehensive data ecosystem tailored to specific business needs.






