
Managing large-scale data pipelines can be a challenging task. As organizations gather data from various sources, the complexity of integrating, transforming, and processing that data can quickly become overwhelming. Manual workflows, inefficient data processing, and the challenge of connecting various systems often slow down progress and delay valuable insights.
To address these challenges, businesses need a scalable, automated, and cost-effective solution that can handle data workflows effortlessly. AWS Glue delivers exactly that. Whether you're tackling complex data transformations, managing massive data volumes, or integrating various AWS services, AWS Glue provides a seamless, serverless platform to streamline and accelerate your data operations.
This blog will explore AWS Glue's architecture, its core features, implementation strategies, and best practices to help you leverage this service to optimize your data workflows and drive business value.
What is AWS Glue?
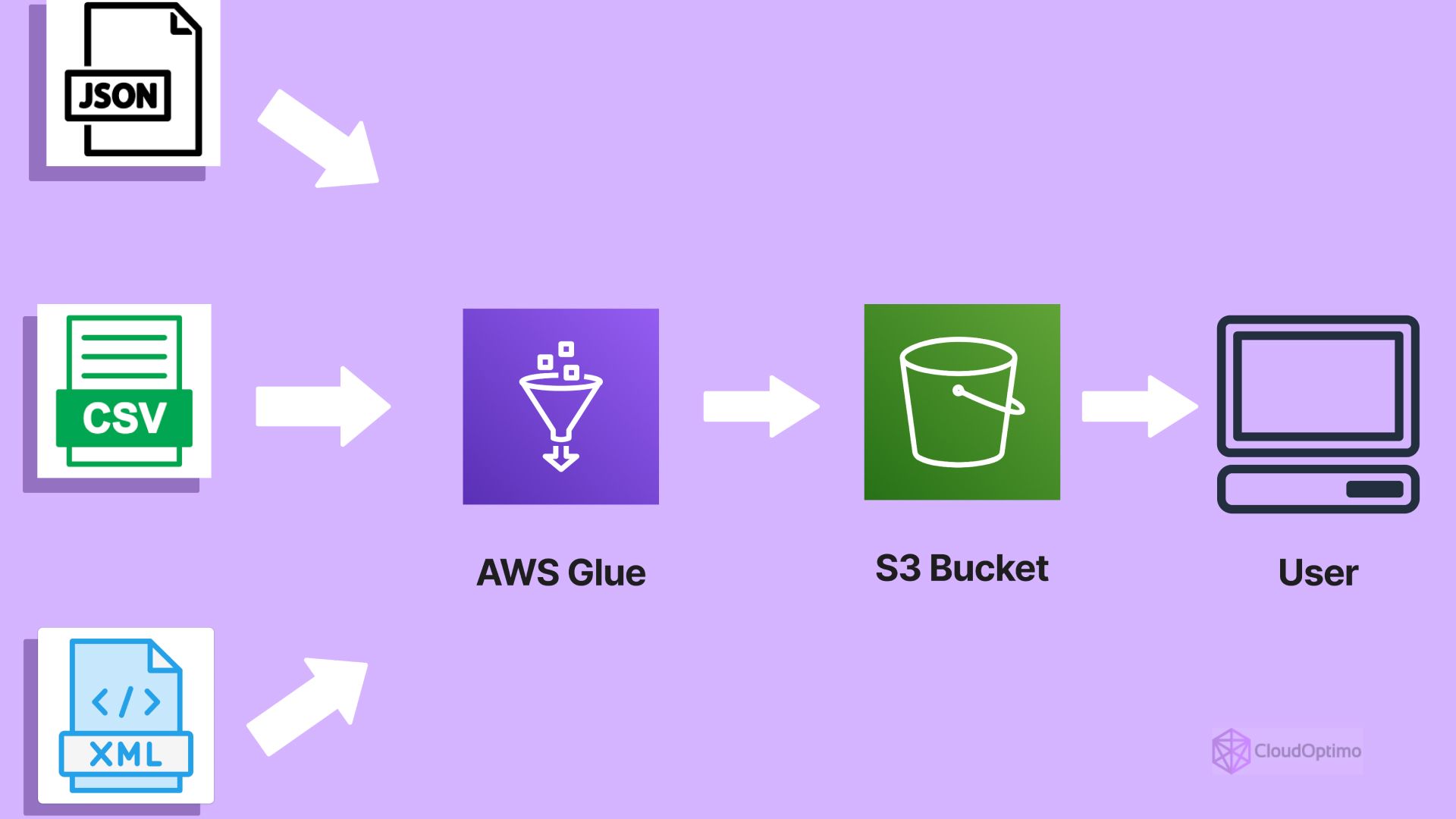
AWS Glue is a fully managed ETL service provided by Amazon Web Services (AWS). It helps automate the process of discovering, cataloging, cleaning, enriching, and transforming data. With data coming in from multiple sources, using AWS Glue makes it easier to move data between your data storage and analytics services in AWS.
- Automation: It automates complex data workflows, which significantly reduces manual effort and human errors.
- Scalability: AWS Glue scales automatically to handle workloads of any size, so you don’t need to worry about resource allocation.
- Cost-Effectiveness: With its pay-as-you-go pricing model, you only pay for the resources you use.
- Integration: It integrates seamlessly with other AWS services like Amazon S3, AWS Redshift, and Amazon Athena.
In short, AWS Glue makes working with data easier, more efficient, and more cost-effective, especially for teams that want to focus on delivering value instead of managing infrastructure.
Where Does AWS Glue Fit in the Data Ecosystem?
AWS Glue plays a pivotal role in the AWS data ecosystem, connecting a variety of data sources with analytics and machine learning services. Understanding its position is key to utilizing it effectively.
Here’s how it fits in:
- Data Ingestion: AWS Glue helps bring data into your ecosystem, whether it's from S3, databases, or third-party applications.
- Data Transformation: Once data is in, AWS Glue transforms it by cleaning, aggregating, and applying business logic to ensure it's ready for analysis.
- Data Loading: After transformation, AWS Glue moves the processed data into analytics tools such as Amazon Redshift or Athena.
AWS Glue integrates with data lakes, warehouses, and analytics platforms to create a seamless data pipeline, enabling faster insights and smarter decision-making.
Core Components of AWS Glue
To fully understand AWS Glue’s potential, you must understand its core components. These components help you design, manage, and monitor ETL jobs.
AWS Glue Data Catalog
The AWS Glue Data Catalog is the central hub of metadata management for AWS Glue. Think of it as a map for your data, providing critical information about your data’s structure, location, and schema.
Key Features:
- Centralized Metadata Repository: It stores the metadata for all your data sources, tables, and partitions, allowing AWS Glue to manage data transformations effectively.
- Schema Management: The catalog keeps track of your data's schema—such as column names, types, and partitions—which helps ensure consistency during ETL operations.
- Data Discoverability: By maintaining an up-to-date catalog, the service makes it easier for other AWS services like Amazon Redshift, Amazon Athena, and AWS Lake Formation to access and query your data.
- Data Partitioning: For large datasets, the catalog supports partitioning, which optimizes performance during read and write operations, as well as speeding up queries by organizing data into subsets (e.g., partitioning by date).
It helps you organize and manage large amounts of data, making it easily discoverable across multiple services, and eliminating manual metadata management.
Crawlers
Crawlers are powerful tools that automate the process of discovering data and cataloging it. Crawlers automatically scan your data sources (like Amazon S3, relational databases, or other AWS services) to infer the structure and schema of your data. They update the AWS Glue Data Catalog with the metadata, ensuring that your ETL jobs are aware of the latest schema changes.
Key Features:
- Automated Schema Discovery: Crawlers detect the format of your data (CSV, JSON, Parquet, etc.) and automatically generate table definitions.
- Schema Evolution Handling: Crawlers can adapt to schema changes over time, such as adding or removing columns, making your ETL process more resilient and reducing the need for manual intervention.
- Scheduling & Incremental Crawling: You can schedule crawlers to run periodically, and the service will only crawl new or updated data, saving time and resources.
- Data Source Integration: Crawlers can scan data from a variety of sources, including Amazon S3, RDS databases, and JDBC-compliant data sources, making them highly versatile.
This automation is essential for keeping ETL jobs running smoothly, especially in dynamic data environments.
ETL Jobs
The ETL Jobs are the core engine of AWS Glue, where the actual transformation of data happens. These jobs perform the Extract, Transform, and Load processes on your data, turning raw data into clean, usable datasets for analysis.
Key Features:
- Customizable Code: AWS Glue provides flexibility by allowing you to write custom transformation logic in Python or Scala. These languages allow you to define complex data processing steps, such as filtering, aggregation and joins.
- Dynamic Frame vs. DataFrame: AWS Glue introduces the concept of DynamicFrames, a special data structure that simplifies working with semi-structured or unstructured data. Unlike a regular DataFrame, DynamicFrames can handle complex nested data types and are easier to work with during transformation.
- Data Transformations: Common operations like filtering, mapping, joining, and aggregating data are supported out of the box. You can also perform more advanced operations such as deduplication or applying business logic.
- Scalability & Parallelism: AWS Glue automatically scales based on the size of the job and data, and jobs can run in parallel, making it suitable for big data workloads. This scaling is managed by AWS Glue, so you don't have to worry about resource provisioning.
Glue Studio
For users who prefer a visual interface to design their ETL jobs, AWS Glue Studio provides a no-code, drag-and-drop environment. It simplifies the process of building, testing, and monitoring ETL workflows.
Key Features:
- Visual Workflow Design: You can visually design complex ETL pipelines by dragging and connecting components. This eliminates the need for manually writing code for every step of your data pipeline.
- Integrated Testing & Debugging: Glue Studio offers built-in features for testing and debugging your ETL jobs before deployment, making it easy to spot issues early.
- Pre-built Transformations: The interface provides a library of pre-built transformations that can be applied without coding, speeding up the ETL development process.
- Real-time Monitoring: Glue Studio allows you to monitor the progress of your jobs in real-time, track their status, and identify bottlenecks during execution.
It significantly reduces the complexity of building ETL pipelines, especially for those who are not as familiar with coding. By offering a no-code interface, it enables faster development and easier management of ETL jobs, which is ideal for teams without extensive programming experience.
Glue Triggers
Glue Triggers provide automation for your ETL jobs by setting up conditions that trigger job execution. These triggers allow you to automate the execution of data workflows based on events or schedules, helping to ensure your data pipelines run at the right times.
Key Features:
- Time-based Triggers: You can schedule jobs to run at specific times or intervals, such as hourly, daily, or weekly. This is useful for running regular data pipelines at consistent times.
- Event-based Triggers: Triggers can be set to fire based on specific events, such as the arrival of new data in an S3 bucket or updates to a database. This ensures that your ETL jobs process data immediately when it’s available.
- Dependency Handling: You can configure triggers to run jobs in sequence or parallel, depending on the dependencies between jobs. This ensures a smooth data flow from one job to another.
- Error Handling: AWS Glue provides options to handle errors and retries, helping to make sure that the pipeline runs without interruption.
With triggers, you can automate your ETL processes and reduce the need for manual intervention. This is particularly useful in production environments where data needs to be processed regularly or as soon as it becomes available.
Putting It All Together
Each of these core components—Data Catalog, Crawlers, ETL Jobs, Glue Studio, and Triggers—plays a crucial role in building and managing effective ETL pipelines. AWS Glue's modular design allows you to work with them individually or in combination, depending on the complexity of your use case.
- Data Catalog serves as the metadata backbone.
- Crawlers automate data discovery and schema management.
- ETL Jobs perform the actual transformation logic.
- Glue Studio offers a visual interface for pipeline creation.
- Triggers automate job execution.
Together, they form a complete and robust ecosystem for data processing, helping you efficiently move and transform data within AWS.
How AWS Glue Works?: A Step-by-Step Breakdown
Let’s walk through how AWS Glue works, from data ingestion to transformation and final storage.
Set Up Your Data Sources
Before AWS Glue can start processing your data, you need to define where the data is coming from. This could be data stored in Amazon S3, relational databases like Amazon RDS, or even data streaming in from other AWS services.
Steps to Set Up Data Sources:
- Define Data Locations: Decide where your raw data is stored, whether it's in Amazon S3, a relational database (RDS, MySQL, etc.), or another AWS service.
- Configure Crawlers: AWS Glue crawlers automatically detect the data structure and schema of the source. These crawlers scan the data and store metadata in the AWS Glue Data Catalog. This makes the data discoverable for further ETL processing.
Setting up your data sources correctly ensures that AWS Glue can accurately process and transform your data. Crawlers save time by automatically identifying the structure of your data and cataloging it for later use.
Create an ETL Job
Once the data sources are defined, the next step is creating an ETL job. This is where the actual transformation of data happens.
Steps to Create an ETL Job:
- Choose Your Programming Language: You can write your transformation logic in either Python or Scala. AWS Glue also supports Glue Studio, a visual interface that lets you build ETL workflows without writing any code.
- Python: If you prefer a flexible, script-based approach, you can write Python code to apply your business logic and transformations to the data.
- Scala: For high-performance transformations, Scala might be a better choice, especially if you're dealing with large datasets.
- Define Transformation Logic: Depending on your business requirements, you can apply various transformations. Common transformations include:
- Filtering: Removing irrelevant data based on specific conditions.
- Aggregating: Summarizing data, such as computing averages or totals.
- Reshaping: Changing the data structure to fit a different format (e.g., changing column names or normalizing nested data).
- Cleansing: Handling missing or incorrect data, such as filling null values or correcting data formats.
The flexibility in choosing programming languages and transformation logic means you can tailor this process exactly to your needs.
- Choose Your Programming Language: You can write your transformation logic in either Python or Scala. AWS Glue also supports Glue Studio, a visual interface that lets you build ETL workflows without writing any code.
Execute the Job
With the data sources configured and transformation logic defined, it’s time to execute the ETL job. Once you run the job, AWS Glue takes over the heavy lifting.
Steps to Execute the Job:
- Run the Job: Execute the ETL job in AWS Glue, and the service will automatically:
- Orchestrate the entire data pipeline, from extraction to transformation.
- Scale resources automatically to handle data volumes efficiently.
- Transform the data based on the logic you defined in step 2.
- Job Monitoring: While the job runs, AWS Glue provides real-time monitoring to track progress, performance, and any errors. You can also set up notifications to alert you if anything goes wrong.
Execution in AWS Glue is automated and scalable, so you don’t need to worry about infrastructure management. Whether you're processing small or large datasets, AWS Glue will allocate the right resources dynamically.
- Run the Job: Execute the ETL job in AWS Glue, and the service will automatically:
Store Transformed Data
After the transformation process is complete, the final step is storing the processed data in your chosen target destination. This could be another S3 bucket, a Redshift data warehouse, or a query-ready format in Amazon Athena.
Steps to Store Transformed Data:
- Choose the Destination:
- Amazon S3: For large, cost-effective storage in formats like Parquet, ORC, or CSV.
- Amazon Redshift: For structured data storage and easy integration with data analytics tools.
- Amazon Athena: For serverless SQL querying directly on data stored in S3.
- Load the Data: AWS Glue loads the transformed data into the target destination. You can schedule regular updates or even trigger automatic data loading as new data becomes available.
- Choose the Destination:
Storing transformed data in the right destination ensures that the next steps in your analytics pipeline (or downstream users) can access it quickly and efficiently.
Hands-On Example: Building a Simple AWS Glue Pipeline
Now that we've broken down the process, let’s walk through an example. We’ll build a simple pipeline that extracts data from an S3 bucket, transforms it, and loads it into Amazon Redshift.
Steps to Build the Pipeline:
- Prepare Data:
Before you start, ensure you have a CSV file in your S3 bucket.
Let’s assume your file is stored in an S3 bucket called s3://my-bucket/customer-data/.
- Create a Crawler:
Use AWS Glue Crawlers to automatically discover the schema of the CSV file. You would typically configure this in the Glue Console, but here’s a Python example using the boto3 library:
| python import boto3 glue_client = boto3.client('glue') # Define the crawler crawler_name = 'customer-data-crawler' crawler_role = 'AWSGlueServiceRole' s3_target = 's3://my-bucket/customer-data/' response = glue_client.create_crawler( Name=crawler_name, Role=crawler_role, DatabaseName='customer_db', Targets={'s3Targets': [{'Path': s3_target}]}, TablePrefix='customer_', CrawlingPolicy={'RecrawlBehavior': 'CRAWL_EVERYTHING'} ) print(response) |
This crawler will scan the CSV file in the S3 bucket, automatically detect the schema, and create a table in the Glue Data Catalog with column names and data types. Once the crawler is run, you can use that schema in the next step.
- Create an ETL Job:
You can use AWS Glue Studio to create the job visually or write Python code to define the transformations. Here, I’ll show you how to do it using Python.
| python import boto3 from awsglue.context import GlueContext from pyspark.context import SparkContext from pyspark.sql import SparkSession # Initialize a GlueContext sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session # Define Data Catalog table name database_name = 'customer_db' table_name = 'customer_data' # Create dynamic frame from Glue catalog dynamic_frame = glueContext.create_dynamic_frame.from_catalog( database=database_name, table_name=table_name ) # Convert DynamicFrame to DataFrame to perform transformations using PySpark df = dynamic_frame.toDF() # Example transformation 1: Filter customers who joined after 2010 df_filtered = df.filter(df['JoinDate'] > '2010-01-01') # Example transformation 2: Create FullName column by combining FirstName and LastName from pyspark.sql.functions import concat_ws df_transformed = df_filtered.withColumn('FullName', concat_ws(' ', df_filtered['FirstName'], df_filtered['LastName'])) # Example transformation 3: Clean up missing Email values df_transformed_cleaned = df_transformed.na.fill({'Email': '[email protected]'}) # Convert back to DynamicFrame for Glue compatibility dynamic_frame_transformed = glueContext.create_dynamic_frame.from_df(df_transformed_cleaned, glueContext, 'transformed_data') # Show the transformed data (for debugging purposes) dynamic_frame_transformed.show() |
Explanation:
- We use DynamicFrame to interact with the data in a schema-agnostic way.
- The code applies three transformations: filtering customers who joined after 2010, creating a new FullName field, and filling missing email values with a placeholder.
- Execute the Job:
Now, you can execute this ETL job in Glue by triggering it. In AWS Glue Console, you can create a job and select Python as the script type, then paste the code from the previous section.
For programmatic job execution, you can use the following Python snippet to start the job:
| python glue_client = boto3.client('glue') # Start the Glue ETL job job_name = 'customer-etl-job' response = glue_client.start_job_run(JobName=job_name) print(response) |
This will start the ETL job based on the transformations you defined in the Python script.
- Store Transformed Data in Amazon Redshift:
Now that the data is transformed, let’s load it into Amazon Redshift. Below is an example of how you can write the transformed data to Redshift:
| python # Define Redshift connection options redshift_options = { "url": "jdbc:redshift://your-cluster-name:5439/your-database", "dbtable": "transformed_customers", "user": "your-user", "password": "your-password" } # Write data to Redshift glueContext.write_dynamic_frame.from_options( dynamic_frame_transformed, connection_type="redshift", connection_options=redshift_options ) |
Explanation:
- Replace the url, dbtable, user, and password placeholders with your actual Redshift cluster details.
- The write_dynamic_frame.from_options method writes the transformed data from the Glue dynamic frame into the specified Redshift table.
This example highlights the power and flexibility of AWS Glue. By automating the entire ETL process—from data discovery to transformation to loading—it allows you to quickly build and scale data pipelines, saving time and reducing manual effort.
CI/CD Pipeline Integration for AWS Glue
Automating the deployment of your AWS Glue jobs ensures that your data workflows remain up-to-date and manageable across different environments (e.g., development, staging, and production). Here’s an example of how to integrate AWS Glue into a CI/CD pipeline:
- Version Control: Store your Glue scripts and configurations in a version control system like Git.
- AWS CodePipeline: Set up AWS CodePipeline to automatically trigger job deployments when changes are committed to the repository.
- AWS CodeBuild: Use AWS CodeBuild to compile and test your Glue scripts before deployment.
- AWS Glue Deployment: Once tested, deploy the job to AWS Glue using AWS SDKs or AWS CLI commands.
Here’s a simple pipeline setup using AWS CodePipeline:
| yaml # AWS CodePipeline YAML configuration stages: - name: Source actions: - name: GitHubSource actionTypeId: GitHub outputArtifacts: - name: SourceArtifact configuration: Owner: "your-organization" Repo: "your-repo" Branch: "main" - name: Build actions: - name: GlueJobBuild actionTypeId: AWS_CodeBuild inputArtifacts: - name: SourceArtifact configuration: ProjectName: "AWSGlueBuildProject" - name: Deploy actions: - name: GlueJobDeploy actionTypeId: AWS_Glue configuration: JobName: "your-glue-job" |
This setup ensures that AWS Glue jobs are automatically tested, built, and deployed as part of your CI/CD pipeline.
Real-World Use Cases of AWS Glue
AWS Glue is used in various industries to solve data-related challenges. Here are a few examples:
Retail & E-commerce: Enhancing Customer Insights and Inventory Management
Retailers generate massive amounts of data from various sources—point-of-sale (POS) systems, online transactions, customer interactions, and inventory records. AWS Glue helps unify this data for improved decision-making.
How AWS Glue Helps:
- 360-Degree Customer View – Combines customer transaction data, online behavior, and feedback to create personalized shopping experiences.
- Inventory Optimization – Merges supply chain and sales data to predict stock shortages and optimize restocking schedules.
- Fraud Detection – Analyzes transactional patterns in real-time to detect anomalies in purchases and prevent fraud.
Example Use Case:
A large e-commerce retailer uses AWS Glue to extract data from its website, mobile app, and in-store purchases. The ETL process consolidates the data and feeds it into an Amazon Redshift data warehouse for real-time analysis, enabling personalized marketing campaigns and stock replenishment recommendations.
Healthcare & Life Sciences: Centralizing Patient Records for Better Care
The healthcare industry faces challenges in integrating data from multiple systems like electronic health records (EHRs), medical imaging, and wearable health devices.
How AWS Glue Helps:
- Unified Patient Data – Combines EHR data, lab results, and insurance claims for a complete patient history.
- Disease Prediction – Helps train AI models by preprocessing vast amounts of patient data.
- Regulatory Compliance – Ensures data governance and adherence to privacy laws like HIPAA.
Example Use Case:
A hospital network uses AWS Glue to aggregate patient records from different departments. The system standardizes and structures the data before loading it into Amazon Athena for querying. This allows doctors to quickly retrieve comprehensive patient histories, improving diagnosis accuracy and treatment efficiency.
Financial Services: Fraud Detection & Risk Management
Banks, fintech companies, and insurance providers rely on AWS Glue for real-time data processing to detect fraud, assess risks, and comply with regulations.
How AWS Glue Helps:
- Fraud Detection in Real-Time – Cleans and pre-processes financial transactions before feeding them into machine learning fraud detection models.
- Credit Scoring & Risk Assessment – Consolidates financial histories to generate accurate credit scores.
- Regulatory Reporting – Automates ETL workflows to prepare compliance reports efficiently.
Example Use Case:
A credit card company processes millions of transactions daily. AWS Glue helps cleanse and structure the data before running anomaly detection algorithms. Suspicious transactions are flagged in real-time, preventing fraudulent activities.
Media & Entertainment: Enhancing Content Recommendations
Streaming platforms generate vast datasets from user interactions, viewing habits, and engagement metrics. AWS Glue enables media companies to harness this data to improve user experiences.
How AWS Glue Helps:
- Personalized Content Recommendations – Processes user watch history and engagement to power AI-driven recommendation engines.
- Ad Targeting Optimization – Merges user demographics and preferences to serve relevant ads.
- Content Performance Analysis – Aggregates viewership metrics to determine trending content.
Example Use Case:
A video streaming service uses AWS Glue to collect and transform viewing data from different devices. The processed data is then used by AI models to recommend content, increasing user engagement and retention.
Manufacturing & IoT: Optimizing Supply Chain Operations
Manufacturers and IoT-driven industries generate sensor data from machinery, factory equipment, and logistics. AWS Glue helps extract insights from this massive stream of data.
How AWS Glue Helps:
- Predictive Maintenance – Aggregates IoT sensor data to predict equipment failures before they occur.
- Supply Chain Optimization – Integrates data from logistics, production, and inventory to improve efficiency.
- Quality Control – Processes production line data to identify defects in real-time.
Example Use Case:
A smart factory uses AWS Glue to clean and analyze sensor data from production machines. The transformed data feeds into a predictive maintenance model, reducing downtime and improving operational efficiency.
These examples show how AWS Glue can provide value across different sectors by streamlining data workflows.
AWS Glue & AWS Athena: A Complementary Approach
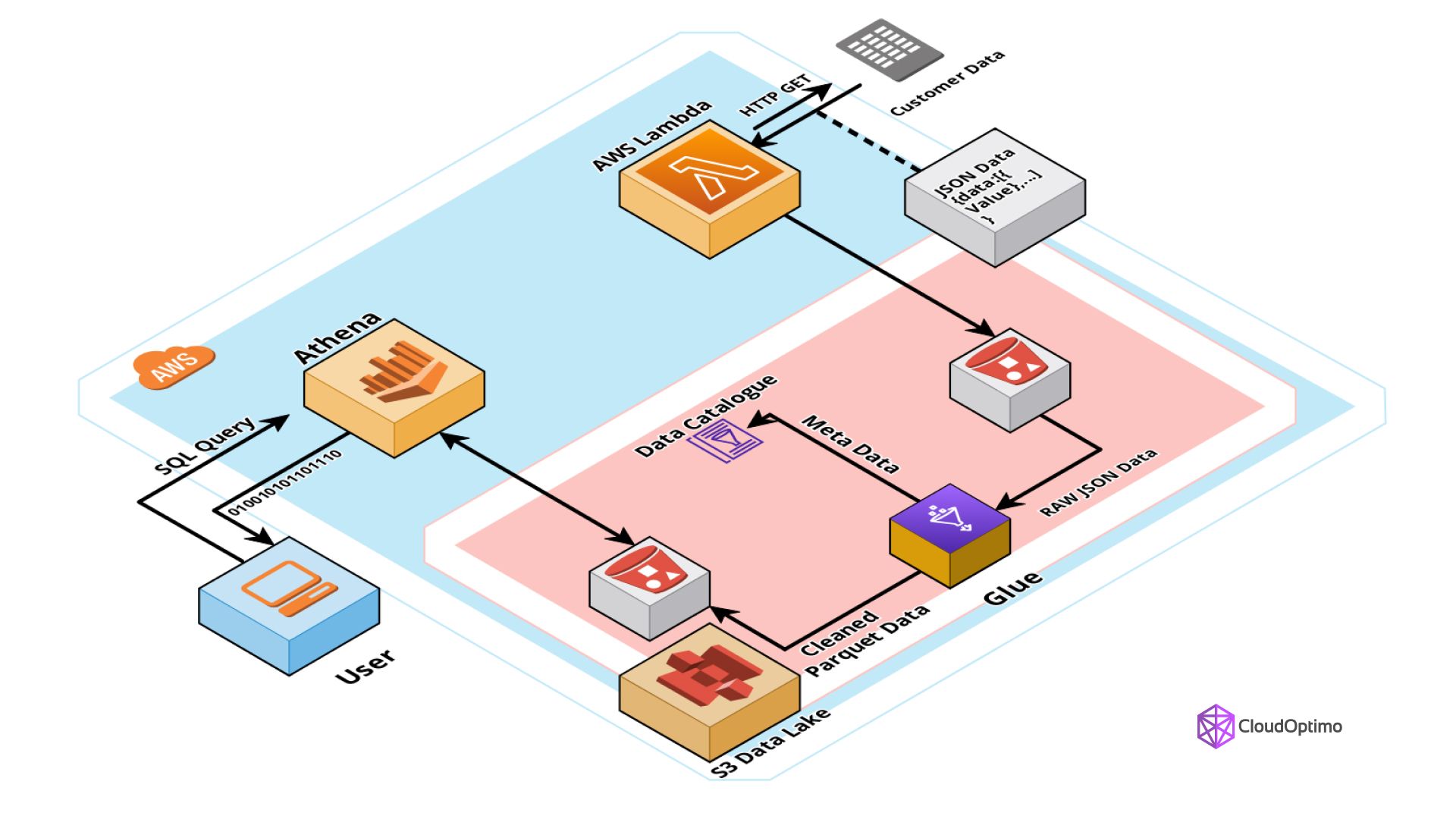
AWS Glue works exceptionally well with Amazon Athena, AWS’s serverless interactive query service. Together, they provide a seamless experience for analyzing large datasets.
- Data Cataloging: AWS Glue creates and maintains the metadata that Athena uses to perform SQL queries.
- Serverless: No need to manage infrastructure; Athena and Glue automatically scale based on data volume and query complexity.
- Cost Efficiency: You only pay for the data scanned by Athena queries, and Glue costs are tied to usage.
By integrating both services, you get an efficient and powerful data processing and querying pipeline.
Best Practices for Optimizing AWS Glue
AWS Glue is a powerful service for ETL workloads, but like any complex system, it requires optimization to handle large-scale jobs efficiently and keep costs down. Here are some key best practices to ensure you're getting the most out of AWS Glue.
Partition Your Data
Partitioning your data properly can drastically improve both performance and cost efficiency, particularly when working with large datasets. By splitting large datasets into smaller, manageable chunks based on certain key attributes (such as date, region, or product type), you enable more efficient queries and faster processing.
How Partitioning Helps:
- Faster Query Execution: When working with Amazon S3 or Amazon Redshift, partitioning allows you to query only relevant portions of the data, reducing the amount of data read and speeding up queries.
- Cost Savings: Since you only query the relevant partitions, the costs associated with data scans in S3 and Redshift can be significantly reduced.
- Improved Performance: Partitioned data can be processed in parallel, allowing AWS Glue to handle large datasets more efficiently.
Best Practices:
- For Amazon S3, organize your data in a logical directory structure (e.g., /year/month/day/).
- For Amazon Redshift, define appropriate partition keys based on your query patterns. This helps in minimizing the data scanned during query execution.
Use Job Bookmarking
Job bookmarking allows AWS Glue to track the state of previously processed data and avoid redundant processing. This is particularly useful for incremental processing, where only the new or updated data needs to be processed, rather than re-running the entire ETL job on all data.
How Job Bookmarking Helps:
- Avoids Duplicate Processing: With job bookmarking, AWS Glue records the state of the last processed record and resumes from there in the next job run, saving time and resources.
- Reduces Job Duration: Only new or changed records are processed, which results in quicker job completion times.
- Lower Cost: Processing smaller batches of data reduces the overall compute costs since AWS Glue only processes the incremental data.
Best Practices:
- Enable job bookmarking by configuring the job in AWS Glue with the Job Bookmarking feature, especially for streaming or batch jobs.
- Use this feature when working with append-only datasets, such as transaction logs or event streams, where new data is regularly added.
Optimize Data Formats and Compression
The data format and compression type you use can significantly impact the performance of your ETL jobs.
Why It Matters:
- Efficient Storage and Faster Processing: Optimized data formats like Parquet or ORC provide columnar storage and are much more efficient than row-based formats (like CSV).
- Compression: Compressing your data reduces the size of files in Amazon S3, which reduces read times and data transfer costs during ETL jobs.
Best Practices:
- Parquet or ORC are highly optimized for large-scale ETL jobs and are typically the best choice when working with AWS Glue.
- Use Snappy compression for Parquet files, as it strikes a good balance between compression efficiency and processing speed.
Leverage DynamicFrames for Schema Flexibility
While working with AWS Glue, consider using DynamicFrames instead of DataFrames for more flexibility in dealing with semi-structured and unstructured data.
Why It Helps:
- Schema Evolution: DynamicFrames automatically handle schema changes, making them ideal for dealing with evolving datasets.
- Data Transformation Flexibility: With DynamicFrames, you can apply transformations without worrying about rigid schemas, allowing for more agile ETL operations.
Best Practices:
- Use DynamicFrames to handle complex, non-relational data or where schema evolution is common (e.g., JSON or CSV with varying columns).
- If your data is highly structured, you may still prefer DataFrames, which offer better performance when working with structured data.
Security Best Practices
To ensure your ETL pipelines are secure, follow these best practices for protecting data during processing and storage.
Use IAM Roles to Control Access
- Principle of Least Privilege: Always define IAM roles and policies with the least privilege principle. This ensures only authorized users and services can access sensitive data.
- Job-specific Permissions: Assign specific permissions for each job rather than providing blanket access to all data in the system.
Encrypt Sensitive Data
- In Transit: Use SSL/TLS encryption for data that’s being transferred between AWS Glue, Amazon S3, Amazon Redshift, or any other AWS service.
- At Rest: Enable encryption on Amazon S3 buckets where raw and processed data are stored. Choose between SSE-S3 or SSE-KMS for server-side encryption.
- Glue Data Catalog: Secure the metadata in the Glue Data Catalog using AWS KMS (Key Management Service) to ensure data at rest is fully encrypted.
Comprehensive Security Configuration
To fully implement security for AWS Glue jobs, configure various security measures such as encryption, VPC access, and monitoring. Below is an example of how to set up a comprehensive security configuration for AWS Glue:
| python # Comprehensive security configuration def configure_security(): # Enable encryption encryption_config = { "S3Encryption": "SSE-KMS", # Server-side encryption using KMS for S3 "CloudWatchEncryption": "KMS", # Encrypt CloudWatch logs "JobBookmarksEncryption": "CSE-KMS" # Encryption for job bookmarks } # Configure VPC vpc_config = { "SecurityGroupIds": ["sg-xxx"], # Specify security group IDs for VPC access "SubnetIds": ["subnet-xxx"] # Define subnet IDs for the Glue jobs to run within a VPC } # Set up monitoring monitoring_config = { "Enable": True, "LogLevel": "INFO", # Set the logging level for CloudWatch "CloudWatchLevel": "DETAILED" # Enable detailed logs for better monitoring } return { "EncryptionConfiguration": encryption_config, "VpcConfig": vpc_config, "MonitoringConfiguration": monitoring_config } |
This function configures encryption for S3, CloudWatch, and Glue Job Bookmarks, sets up VPC configurations for secure access, and enables monitoring with detailed CloudWatch logs to ensure all activities are well-logged.
Regularly Audit Permissions and Policies:
- Review IAM Policies: Regularly audit your IAM policies to ensure that permissions are updated in line with your evolving security requirements.
- AWS CloudTrail: Use AWS CloudTrail to track and monitor access to your AWS Glue resources, allowing you to log and analyze who accessed what data and when.
Advanced Encryption and Monitoring:
To further enhance security, implement granular encryption controls and set up comprehensive monitoring configurations across your AWS Glue resources:
- AWS KMS (Key Management Service): Use KMS for both server-side encryption of data stored in S3 and for managing encryption keys for Glue Data Catalog.
- VPC Configurations: Securely run Glue jobs inside a Virtual Private Cloud (VPC) to isolate network traffic and manage job access more tightly.
- CloudWatch Monitoring: Enable detailed CloudWatch logging to monitor job execution, errors, and overall system health in real-time.
Monitoring & Debugging AWS Glue Jobs
Once your jobs are optimized, it’s essential to continuously monitor and troubleshoot them. AWS Glue provides several tools to help you diagnose issues, monitor job status, and track job performance.
CloudWatch Logs
CloudWatch Logs is your go-to tool for tracking the real-time activity of your AWS Glue jobs. You can use it to capture logs from your ETL jobs, helping you identify any issues during processing, from transformation errors to performance bottlenecks.
Best Practices:
- Enable detailed logging in your AWS Glue job definitions to capture logs that can help diagnose issues.
- Use CloudWatch Insights to search and analyze logs for deeper troubleshooting.
AWS Glue Console
The AWS Glue Console provides a dashboard to easily track your job status, monitor progress, and review error messages. It’s a great tool for quickly checking if a job is stuck or has completed successfully.
Best Practices:
- Monitor job history and view resource utilization directly from the Glue Console to identify potential bottlenecks.
- Use the error messages to quickly address issues with specific jobs or data sources.
CloudWatch Metrics
AWS Glue integrates with CloudWatch Metrics, allowing you to track performance metrics such as the duration of your jobs, the amount of data processed, and resource utilization.
Best Practices:
- Set up CloudWatch Alarms to notify you when jobs fail, take longer than expected, or exceed resource usage limits.
- Leverage CloudWatch Dashboards to visualize performance trends and identify any patterns that may indicate issues.
Debugging with AWS Glue Studio
If you’re using AWS Glue Studio (the visual interface), it offers built-in debugging tools that allow you to inspect job runs, view logs, and step through transformations.
Best Practices:
- Test locally: Use the Preview feature in Glue Studio to test your transformations on a small sample before running on the full dataset.
- Step-by-Step Debugging: You can debug your ETL jobs in Glue Studio by checking the transformations applied and identifying any errors along the way.
Common Challenges & How to Overcome Them
While AWS Glue offers a powerful and flexible environment for data transformation, it’s not without its challenges. Understa
nding these common pitfalls and how to mitigate them can ensure smoother workflows and more efficient use of the service.
Data Skew: Uneven Data Distribution
One of the most common challenges in distributed computing is data skew, where certain partitions or data blocks end up with more records than others. This causes processing bottlenecks, slowing down your ETL jobs significantly.
Solution:
- Partitioning Strategy: Use partitioning strategies when storing your data in Amazon S3 or Amazon Redshift. By organizing your data into partitions based on key attributes (e.g., date, region), you can evenly distribute the workload and reduce the risk of skew.
Additional Tips:
- Avoid small files: Ensure your data is grouped into larger, manageable chunks. Small files can cause inefficiencies in processing.
- Use partitioned datasets to improve job execution speed and minimize the data processed during each run.
Code Example:
| python # Implement custom partitioning strategy def custom_partition_data(dynamic_frame): return dynamic_frame.repartition(num_partitions=50, partitioning_keys=["date", "region"]) |
Complex Transformations: Large-Scale Operations Can Be Resource-Intensive
When dealing with massive datasets, certain data transformations (like aggregations, joins, or complex calculations) can require substantial compute power, making jobs slow and expensive.
Solution:
- Split Large Jobs: Break down large, resource-hungry transformations into smaller, more manageable tasks. Instead of processing a massive dataset in one go, split it into multiple, smaller jobs that can run in parallel.
Additional Optimization Tips:
- Use Pushdown Predicates: Reduce the data you process by filtering it at the data source before loading it into AWS Glue.
- Leverage AWS Glue's built-in optimization features like DynamicFrames and Job Bookmarks to process incremental data instead of reprocessing everything.
- Optimize scripts by focusing on efficient coding practices, such as minimizing the use of expensive operations like joins and sorts when not necessary.
Code Example:
| python # Implement broadcast joins for small tables from pyspark.sql.functions import broadcast def optimize_join(large_df, small_df, join_key): return large_df.join(broadcast(small_df), join_key) |
Permissions: Ensuring Correct Access for Data Sources & Destinations
One of the tricky parts of working with AWS Glue is managing permissions, especially as your jobs start interacting with multiple AWS services and data sources. Ensuring the correct permissions for accessing data across services can lead to either access errors or over-permissioning, both of which pose security risks.
Solution:
Implement fine-grained IAM roles that restrict access to only the required data and services. Use role-based access control (RBAC) to assign specific roles to users and jobs, limiting access to sensitive data.
Best Practices:
- Regularly audit IAM roles and permissions to ensure that users and services only have access to what they need.
- Enable AWS CloudTrail to log all API activities for AWS Glue and related services, providing visibility into access and potential misuse.
Memory Management and Resource Usage
Memory management becomes an issue when performing large joins or resource-intensive operations. Large-scale transformations can lead to out-of-memory errors and slow job execution.
Solution:
Optimize job configurations and split large transformations into smaller tasks. For example, use broadcast joins for small tables to reduce memory overhead.
Best Practices:
- DynamicFrames: Use DynamicFrames for more efficient memory management during transformations.
- Job Bookmarks: Apply Job Bookmarks to process only new or modified data, which reduces reprocessing times.
- Split large operations into smaller jobs to run in parallel, thus balancing resource usage and minimizing job execution times.
Code Example:
| python # Efficient resource management with DynamicFrames def manage_memory_with_dynamic_frame(dynamic_frame): # Apply some transformation logic here return dynamic_frame # Apply job bookmarking to process incremental data def job_bookmarking_example(dynamic_frame): return dynamic_frame.apply_mapping([ ("col1", "string", "col1", "string"), ("col2", "int", "col2", "int") ]) |
AWS Glue vs. Other ETL Solutions: How Does It Compare?
When choosing an ETL solution, there are several popular tools available, such as Apache Spark, Apache NiFi, and traditional ETL tools like Talend and Informatica. While each of these tools has its strengths, AWS Glue offers several unique advantages that make it an attractive choice, especially for organizations heavily invested in the AWS ecosystem.
Below is a breakdown of AWS Glue's key features compared to other ETL solutions.
| Feature | AWS Glue | Apache Spark | Apache NiFi | Talend & Informatica |
| Serverless Architecture | Fully serverless, no infrastructure management needed. | Not serverless; requires manual cluster management (e.g., Amazon EMR). | Not fully serverless; requires node management. | Server-based or cloud-managed; still requires infrastructure setup. |
| Integration with AWS | Tight integration with AWS S3, Redshift, Athena, Lambda, and other AWS services. | Can integrate with AWS, but requires additional setup. | Can integrate with AWS but requires more manual configuration for full ETL functionality. | Integrates with AWS but may require more configuration. |
| Cost-Effectiveness | Pay-as-you-go pricing based on resource consumption. No upfront costs. | Can become more expensive due to infrastructure management costs (EMR clusters). | Open-source but incurs cloud infrastructure costs. | Requires licenses or subscriptions, potentially expensive depending on scale. |
| Ease of Use | Easy-to-use Glue Studio interface for visual ETL creation; automated schema discovery with Glue Crawlers. | Requires coding (Scala, Python, Java); complex setup for non-expert users. | Drag-and-drop UI for data flow management; not as suited for complex transformations. | Offers drag-and-drop interfaces but requires technical expertise for setup. |
| Flexibility & Extensibility | Extensible via Python and Scala; best for AWS-centric workflows. | Highly flexible; can be tailored for complex transformations and streaming data. | Highly customizable via extensions and plugins; great for real-time data flow management. | Extensible, but may be less flexible than Spark in highly customized workflows. |
| Performance and Scalability | Automatically scales based on workload; optimized for cloud-native workflows. | Highly scalable but requires manual cluster management; ideal for large-scale transformations. | Scales well but depends on underlying infrastructure; suited for real-time data flows. | Scales well in the cloud but can become expensive for very large datasets. |
| Support for Complex Data Transformations | Supports standard ETL tasks; limited by serverless nature for non-cloud-native workflows. | Excellent for heavy-duty data transformations; ideal for machine learning and streaming. | Focuses more on data movement; limited transformation capabilities compared to Glue and Spark. | Good for standard transformations; handles a wide variety of data processing tasks. |
| Machine Learning Integration | Seamless integration with AWS SageMaker for ML tasks. | Can be integrated with ML frameworks but requires setup and management. | Not focused on ML; requires additional tools for integration. | Supports integration with ML but not as tight as AWS Glue’s ML integrations. |
| Security | Strong AWS security model with IAM roles, encryption at rest and in transit, and audit logs. | Offers robust security but requires manual setup for IAM roles and encryption. | Can integrate with AWS security but requires manual setup for encryption and IAM. | Supports enterprise-grade security but may require manual configurations for cloud environments. |
| Community and Ecosystem | AWS managed ecosystem; vast documentation, support, and integration with AWS tools. | Large community; powerful open-source ecosystem. However, requires more expertise to set up. | Open-source with an active community; best for data flow management, but not as widely used for full ETL. | Large enterprise support; mature tools with many pre-built connectors, but higher cost. |
While other tools may offer more flexibility in specific scenarios, AWS Glue excels in cloud-native, large-scale data operations.
Future Trends: What’s Next for AWS Glue?
AWS Glue continues to evolve as AWS works to meet the growing needs of modern data processing. Here’s a look at some key future trends that will shape AWS Glue in the coming years.
Machine Learning Integration
AWS Glue is integrating Machine Learning (ML) to automatically clean and transform data. Features such as automatic data classification, anomaly detection, and intelligent data transformations will help automate more aspects of the ETL process.
- Data Cleansing with ML: Expect Glue to offer more advanced features for automatically identifying and fixing data quality issues without manual intervention.
- AI-Powered Transformations: Future versions of AWS Glue might use ML models to automatically suggest or apply transformations based on data patterns.
Cross-Region Support
AWS Glue is expanding its support for cross-region data movement, enabling more flexibility when processing and analyzing data across different AWS regions.
- Data Replication: You will be able to replicate and process data across multiple regions, making it easier to comply with data sovereignty regulations or optimize data for geographic-specific analytics.
Improved Performance and Scalability
AWS Glue is continually improving in terms of performance and scalability. Expect faster job execution times, more efficient resource usage, and improved job scheduling as AWS optimizes its Glue service.
- Faster Data Processing: Future updates to Glue’s underlying infrastructure will likely result in faster processing times for large-scale data jobs.
- Enhanced Job Orchestration: AWS Glue will likely introduce better tools for orchestrating complex multi-step ETL workflows, enabling easier job dependency management and automated retries.
Final Thoughts & Next Steps
AWS Glue is a powerful tool for managing and transforming data in the AWS ecosystem. With its ease of use, scalability, and cost-effectiveness, it’s a great choice for businesses looking to streamline their data workflows.
To get started:
- Familiarize yourself with the core components of AWS Glue.
- Experiment with Glue Studio and Crawlers.
- Build a simple pipeline and scale it as needed.
As you explore AWS Glue, you’ll uncover even more potential for automating and optimizing your data workflows.






