

Can your application handle unexpected traffic spikes? Azure Autoscaling ensures it does. By intelligently adjusting resources based on demand, you can optimize performance, reduce costs, and achieve unparalleled scalability. Let's dive into how to master this essential cloud skill.
What is Autoscaling in Azure?
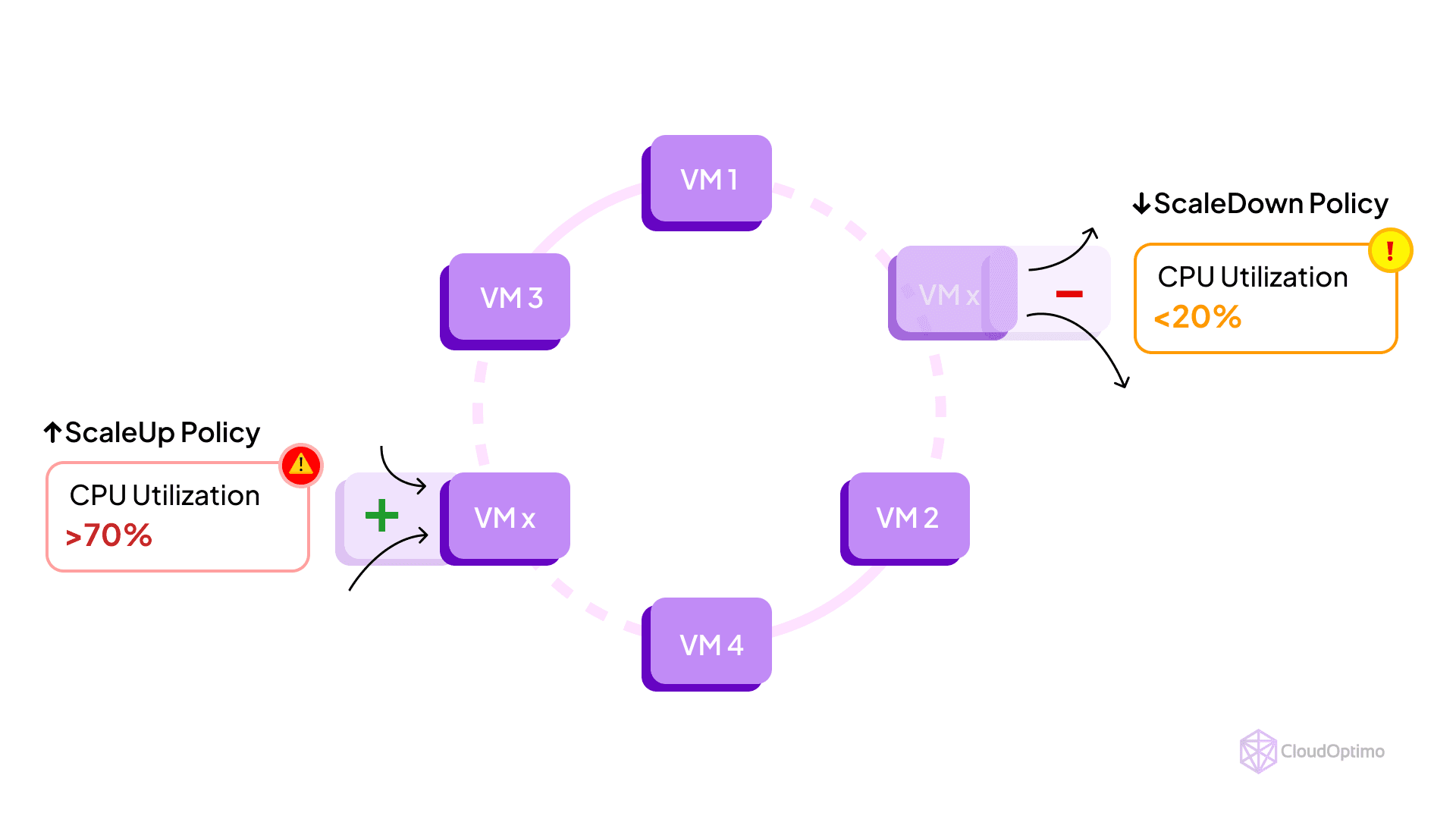
Azure autoscaling is an intelligent feature that dynamically adjusts your cloud resources based on predefined rules and real-time metrics. This automated scaling ensures your applications have the necessary resources to handle varying workloads efficiently, striking a balance between performance and cost-effectiveness.
Key Advantages of Azure Autoscaling
- Resource Optimization: Dynamically allocate resources based on actual demand, minimizing waste.
- Financial Efficiency: Pay only for the resources you need, when you need them.
- Seamless User Experience: Maintain consistent performance during traffic fluctuations.
- Operational Simplicity: Reduce manual intervention with automated resource management.
Autoscaling Mechanisms
Azure employs several core autoscaling mechanisms to adjust resource allocation dynamically:
- Horizontal Pod Autoscaler (HPA): Primarily for Kubernetes environments, this controller automatically scales the number of replica pods based on CPU utilization or custom metrics.
- Cluster Autoscaler: In Kubernetes, this component adjusts the size of the cluster (number of nodes) to accommodate pod scheduling needs.
- Virtual Machine Scale Sets (VMSS): This infrastructure-as-a-service (IaaS) resource allows for automatic virtual machine scaling based on CPU utilization, network traffic, or custom metrics.
- App Service Autoscale: This platform-as-a-service (PaaS) offering enables scaling of web apps, API apps, and mobile backends based on instance count, CPU utilization, or request queue length.
- Azure Functions Autoscale: Serverless compute automatically scales based on incoming triggers and execution time.
Comparative Analysis of Autoscaling Approaches
| Feature | Horizontal Pod Autoscaler (HPA) | Virtual Machine Scale Sets (VMSS) | App Service Autoscale |
| Scalability | Rapid, granular | Flexible, horizontal and vertical | Efficient for web applications |
| Cost-efficiency | Cost-effective for containerized workloads | Cost-effective with proper configuration | Cost-effective for PaaS applications |
| Management complexity | Requires Kubernetes environment | More complex to manage | Easier to configure and manage |
Azure Services Supported by Autoscaling
While Virtual Machine Scale Sets are often associated with autoscaling, Azure offers this functionality across a diverse range of services:
| Service/Component | Scalable Unit | Primary Metrics | Typical Use Cases |
| Virtual Machine Scale Sets | VM Instances | CPU Utilization, Network Traffic | Scalable Web Applications |
| App Service Plans | Application Instances | Request Queue Length, Memory Usage | APIs, Web Apps |
| Azure Kubernetes Service | Pods and Nodes | Container CPU/Memory Usage | Microservices Architectures |
| Azure Functions | Function Instances | Execution Count, Queue Length | Event-Driven Processing |
| Azure SQL Database | Compute Resources (DTUs/vCores) | CPU Percentage, IO Percentage | Dynamic Database Workloads |
| Azure Cosmos DB | Throughput (Request Units) | Normalized RU Consumption | Global-Scale NoSQL Applications |
Let's delve into the autoscaling mechanisms of key Azure services:
- Virtual Machine Scale Sets
Virtual Machine Scale Sets (VMSS) enable you to manage and scale a group of identical VMs collectively.
Notable Features:
- Supports both horizontal and vertical scaling
- Integrates seamlessly with Azure Load Balancer
- Offers flexibility with custom metrics for scaling decisions
Implementation Walkthrough:
- Design your VMSS architecture
- Configure scaling parameters (min/max instances, scaling rules)
- Set up monitoring and alerts
- Implement health probes for reliability
Azure CLI example for creating a VM Scale Set with autoscaling:
| az vmss create \ --resource-group myResourceGroup \ --name myScaleSet \ --image UbuntuLTS \ --upgrade-policy-mode automatic \ --admin-username azureuser \ --generate-ssh-keys \ --instance-count 2 \ --vm-sku Standard_DS2_v2 az monitor autoscale create \ --resource-group myResourceGroup \ --resource myScaleSet \ --resource-type Microsoft.Compute/virtualMachineScaleSets \ --name autoscale \ --min-count 2 \ --max-count 10 \ --count 2 |
Best Practices:
- Implement gradual scaling to prevent resource shocks
- Utilize a mix of VM sizes for cost-performance balance
Regularly review and fine-tune scaling thresholds
- App Service Plans
App Service Plans provide a flexible platform for scaling web applications, APIs, and mobile backends.
Key Capabilities:
- Supports both time-based and metric-based scaling rules
- Offers seamless integration with Azure Front Door for global load balancing
- Provides built-in auto-healing mechanisms
Configuration Process:
- Select an appropriate App Service Plan tier
- Define scaling rules based on performance metrics or schedules
- Set instance limits (minimum and maximum)
- Configure scale-out and scale-in thresholds
Azure CLI example for enabling autoscaling on an App Service Plan:
| az appservice plan update --name myAppPlan --resource-group myRG --sku S1 az monitor autoscale create --resource-group myRG --resource myAppPlan --resource-type Microsoft.Web/serverFarms --name myAutoScaleSettings --min-count 1 --max-count 5 --count 1 az monitor autoscale rule create --resource-group myRG --autoscale-name myAutoScaleSettings --condition "CpuPercentage > 70 avg 10m" --scale out 1 |
Best Practices:
- Implement staged scaling for predictable workload patterns
- Utilize Application Insights for in-depth performance monitoring
Consider using deployment slots for zero-downtime updates
- Azure Kubernetes Service (AKS)
AKS provides powerful autoscaling capabilities for containerized applications at both the pod and node levels.
- Distinguishing Features:
- Horizontal Pod Autoscaler for application-level scaling
- Cluster Autoscaler for infrastructure-level scaling
- Support for custom metrics and event-driven scaling
- Setup Guidelines:
- Enable cluster autoscaler during AKS cluster creation or update
- Configure Horizontal Pod Autoscaler for deployments
- Define resource requests and limits for efficient scaling
Azure CLI snippet for enabling cluster autoscaler:
| az aks create --resource-group myRG --name myAKSCluster --node-count 1 --enable-cluster-autoscaler --min-count 1 --max-count 5 |
Best Practices:
- Implement pod disruption budgets to maintain application availability
- Utilize node pools for efficient resource allocation
- Regularly monitor and adjust autoscaling parameters
- Azure Functions
Azure Functions automatically scales to meet demand, offering true serverless autoscaling in the Consumption plan.
Key Aspects:
- Scales based on event trigger frequency and execution duration
- Supports Consumption, Premium, and Dedicated hosting plans
- Offers dynamic concurrency management
Optimization Strategies:
- Design functions to be stateless and idempotent
- Utilize durable functions for complex workflows
- Monitor execution times and adjust timeout settings accordingly
- Azure SQL Database
Azure SQL Database offers flexible scaling options to handle varying database workloads efficiently.
Notable Features:
- Serverless compute tier for automatic scaling
- Hyperscale service tier for massive scalability
- Autoscaling of storage capacity
Implementation Steps:
- Choose the appropriate service tier (Serverless or Hyperscale)
- Configure min/max vCores or auto-pause delay for Serverless
- Monitor performance metrics and adjust as needed
Best Practices:
- Utilize Query Store for performance insights
- Implement elastic pools for efficient resource sharing among multiple databases
- Regularly review and optimize query performance
Integration with Azure Services
To maximize the benefits of autoscaling, integrate with these powerful Azure services:
Azure Monitor for Comprehensive Metrics
Use Azure CLI to create and send custom metrics:
| az monitor metrics create \ --resource-group myResourceGroup \ --resource-name myResource \ --resource-type "Microsoft.Compute/virtualMachineScaleSets" \ --metric-names "CustomMetric" \ --time-grain PT1M \ --time-window P1D az monitor metrics send-values \ --resource-group myResourceGroup \ --resource-name myResource \ --resource-type "Microsoft.Compute/virtualMachineScaleSets" \ --metric-name "CustomMetric" \ --time-stamp "xxxx-xx-xxT12:00:00Z" \ --value xx |
Application Insights for Deep Performance Monitoring
Query Application Insights for detailed performance data:
| az monitor app-insights query \ --app myAppInsights \ --analytics-query "requests | where success == false | summarize FailedRequests = count() by bin(timestamp, 5m)" \ --output table |
Azure Log Analytics for Advanced Querying
Use Log Analytics to create complex queries spanning multiple resources:
| az monitor log-analytics query \ --workspace-name myWorkspace \ --analytics-query " let appInsights = app('myAppInsightsResource').requests | where success == false | summarize FailedRequests = count() by bin(timestamp, 5m); let scaleEvents = AutoscaleScaleActionsLog | where ResourceId contains 'myResourceId' | summarize ScaleEvents = count() by bin(TimeGenerated, 5m); appInsights | join kind=fullouter scaleEvents on $left.timestamp == $right.TimeGenerated | project timestamp, FailedRequests, ScaleEvents | render timechart " \ --output table |
These integrations provide deeper insights into your application's performance and scaling behavior.
Key Factors for Autoscaling Strategy Selection
When selecting the appropriate autoscaling strategy for your Azure environment, consider the following factors:
Workload Characteristics
- Predictable Workloads: These exhibit consistent patterns, such as daily or weekly traffic spikes. Time-based scaling rules are often suitable.
- Unpredictable Workloads: These are characterized by sudden and unpredictable traffic surges. Metric-based scaling, triggered by CPU utilization, memory usage, or custom metrics, is generally preferred.
- Bursty Workloads: These involve short-lived, high-intensity workloads, requiring rapid scaling and elastic resources. Serverless computing and horizontal pod autoscaling (HPA) are often ideal.
Performance Requirements
- Latency-Sensitive Applications: Low latency is critical. Autoscaling decisions must be made quickly to avoid performance degradation.
- High Throughput Applications: The ability to handle a large volume of requests is essential. Horizontal scaling is often employed to increase capacity.
- Scalability: The system must handle increasing workloads without compromising performance. Autoscaling should be designed to accommodate growth.
Cost Optimization
- Cost-Sensitive Workloads: Minimizing expenses is a primary goal. Consider rightsizing instances, utilizing spot instances, and implementing cost-saving autoscaling rules.
- Performance-Optimized Workloads: Prioritize performance over cost. Be willing to invest in additional resources to meet service level objectives (SLOs).
Compute Model
- Serverless: Ideal for unpredictable workloads with high burstiness, as it offers automatic scaling based on event triggers.
- Virtual Machines: Provide granular control over resources but require more management for autoscaling.
- Containers: Offer a balance between flexibility and efficiency, suitable for various workload types.
Decision Matrix for Autoscaling Strategy
To help you select the most appropriate autoscaling strategy, use the following decision matrix. This structured approach will guide you through evaluating your workload characteristics, performance requirements, cost priorities, and compute models.
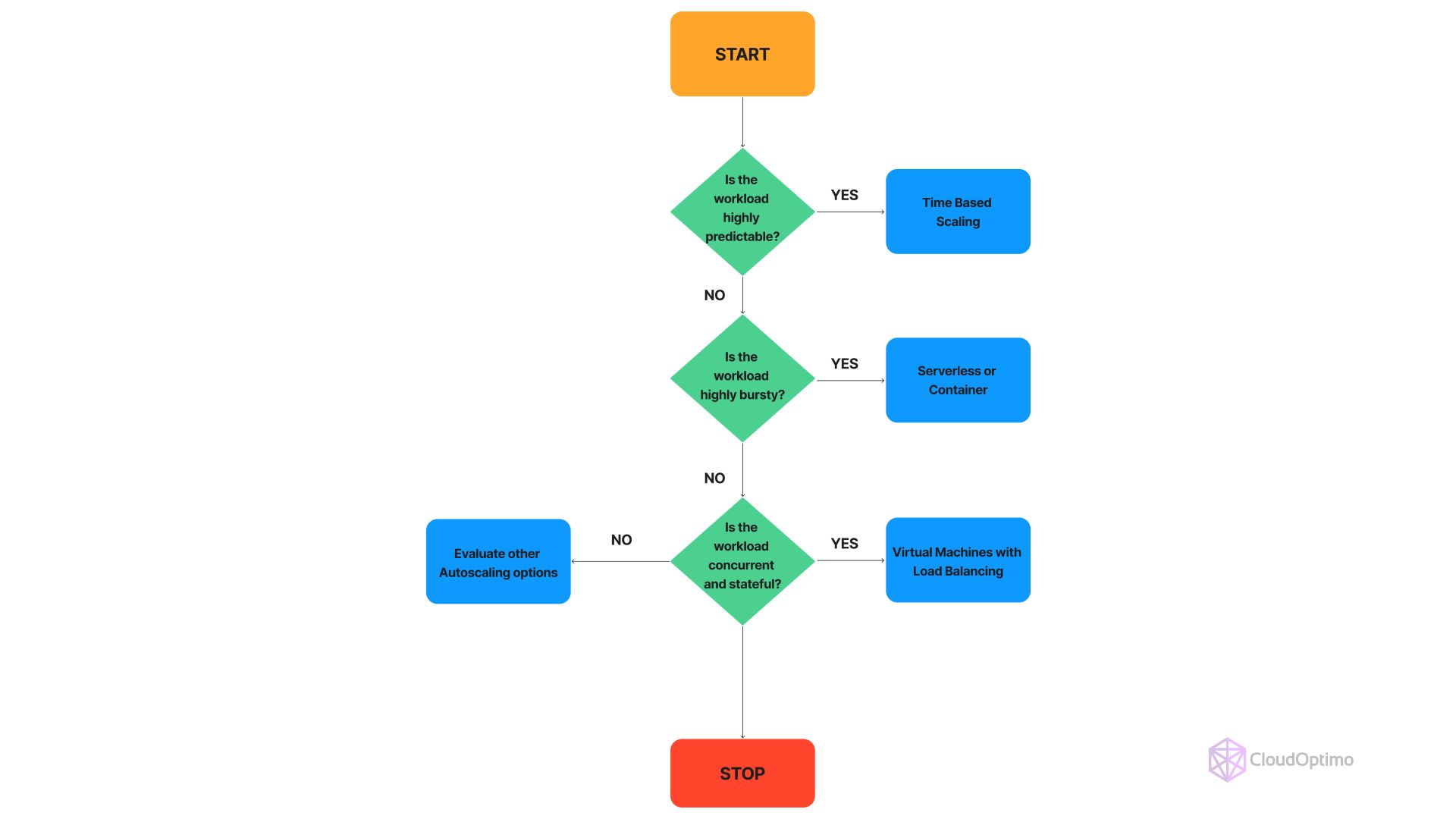
- Evaluate Workload Characteristics
| Workload Type | Characteristics | Recommended Autoscaling Approach |
| Predictable | Consistent patterns (e.g., daily/weekly spikes) | Time-Based Scaling |
| Unpredictable | Sudden and irregular surges | Metric-Based Scaling (e.g., CPU, memory metrics) |
| Bursty | Short-lived, high-intensity demands | Serverless Computing or Horizontal Pod Autoscaling (HPA) |
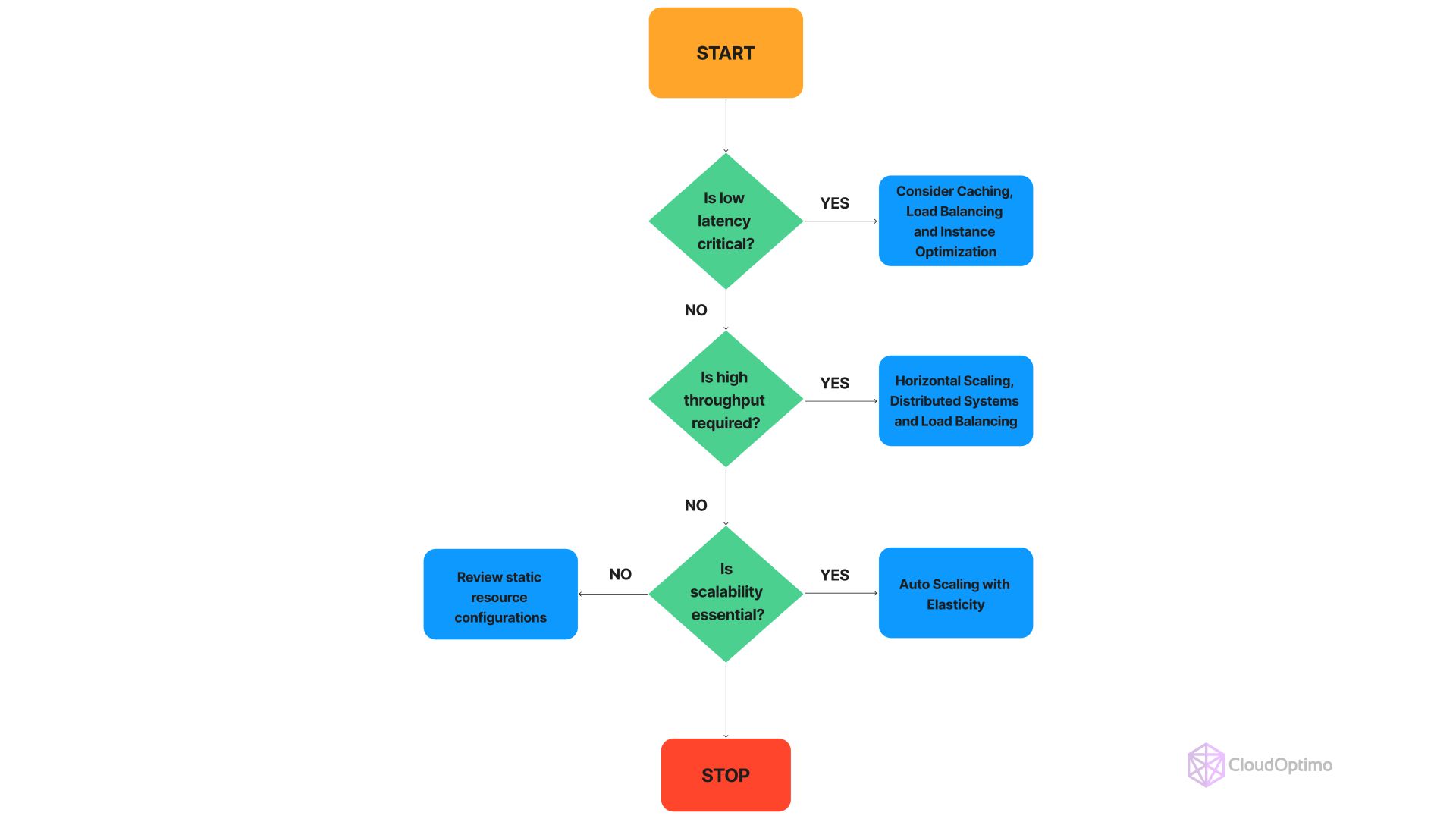
- Assess Performance Requirements
| Performance Requirement | Characteristics | Recommended Autoscaling Approach |
| Latency-Sensitive | Low latency is crucial | Rapid Response Autoscaling |
| High Throughput | High volume of requests | Horizontal Scaling |
| Scalability | Ability to handle growing workloads | Horizontal or Vertical Scaling |
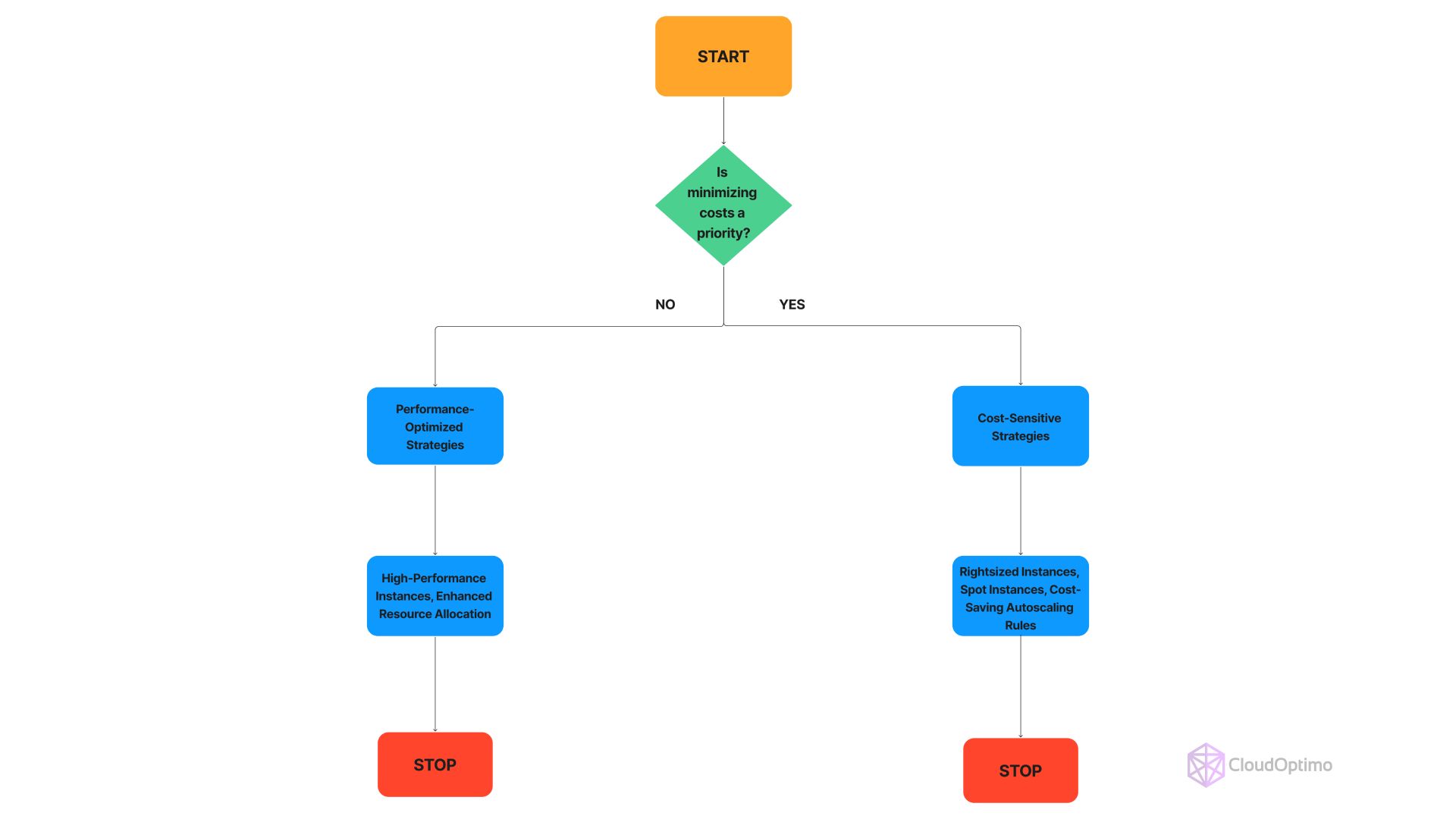
- Evaluate Cost Optimization Needs
| Cost Focus | Characteristics | Recommended Autoscaling Approach |
| Cost-Sensitive | Prioritize minimizing expenses | Rightsized Instances, Spot Instances, Cost-Effective Scaling Rules |
| Performance-Optimized | Prioritize performance over cost | High-Performance Instances, Enhanced Resource Allocation |
- Choose Compute Model
| Compute Model | Characteristics | Best Suited For |
| Serverless | Automatically scales based on event triggers | Unpredictable and Bursty Workloads |
| Virtual Machines | Granular control over resources | Predictable Workloads, Performance-Sensitive Applications |
| Containers | Flexible and efficient | Various Workloads, Scalable Applications |
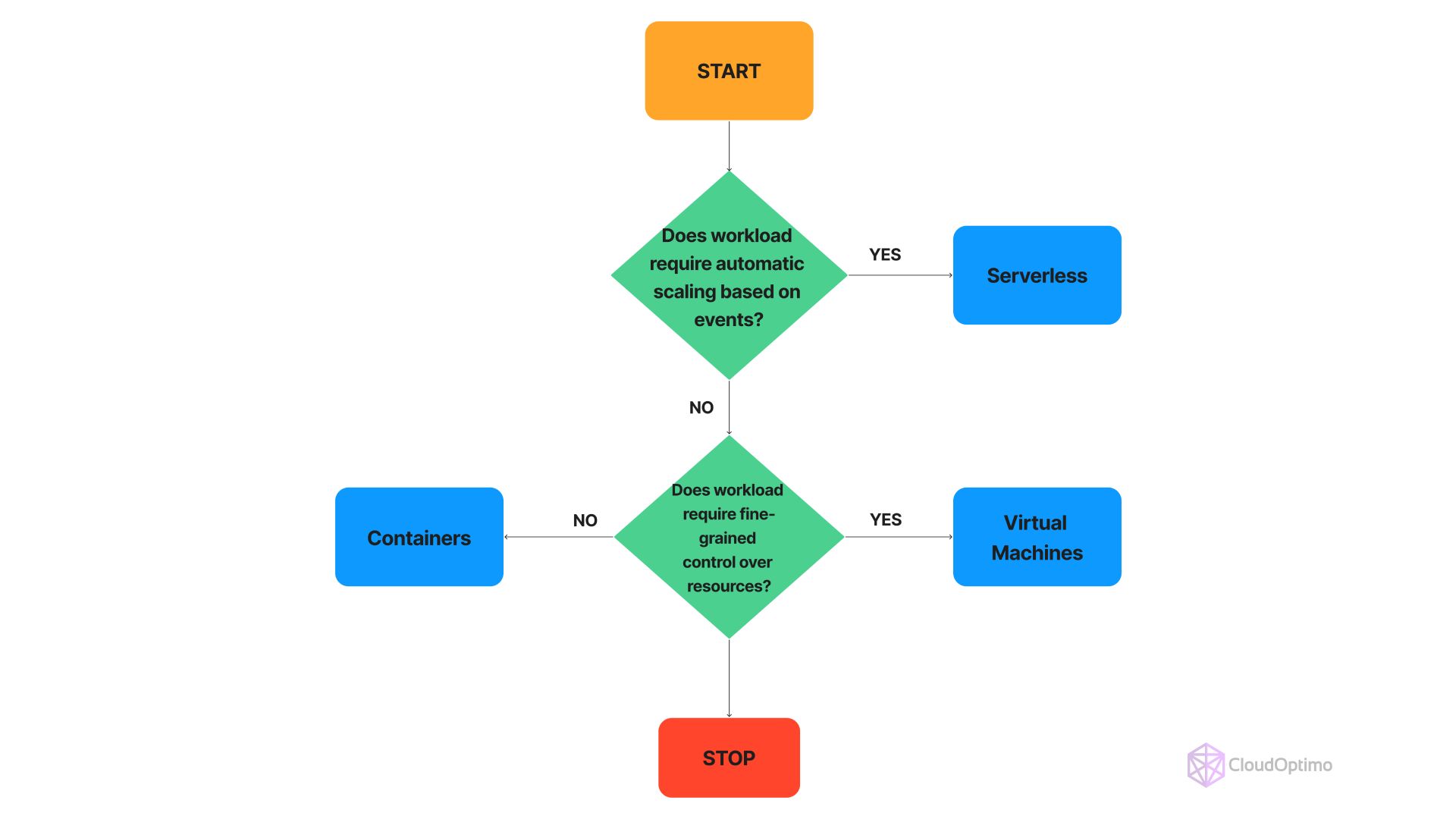
How to Use the Decision Matrix
- Identify Workload Characteristics:
- Determine if your workload is predictable, unpredictable, or bursty.
- Refer to the matrix to find the recommended autoscaling approach.
- Assess Performance Requirements:
- Evaluate whether your application is latency-sensitive, needs high throughput, or requires scalability.
- Use the matrix to align your performance needs with the appropriate autoscaling strategy.
- Evaluate Cost Optimization Needs:
- Decide if minimizing costs or optimizing performance is your priority.
- Choose the autoscaling approach that best fits your cost management strategy.
- Choose Compute Model:
- Select the compute model that best suits your workload type and autoscaling needs.
Example Application
Imagine you’re managing a web application with the following attributes:
- Workload Characteristics: Unpredictable traffic patterns.
- Performance Requirements: Latency-sensitive.
- Cost Optimization Needs: Performance-optimized.
- Compute Model: Serverless.
Decision Path:
- Workload Characteristics: Unpredictable → Metric-Based Scaling.
- Performance Requirements: Latency-Sensitive → Rapid Response Autoscaling.
- Cost Optimization Needs: Performance-Optimized → Serverless Computing.
- Compute Model: Serverless.
Result: Serverless Computing with Metric-Based Scaling to handle unpredictable traffic with low latency and optimized performance.
This decision matrix provides a structured approach to selecting an autoscaling strategy based on your specific needs and constraints, ensuring that your environment is both efficient and cost-effective.
Developing an Effective Autoscaling Strategy
A well-crafted autoscaling strategy involves careful consideration of several key elements:
Cross-Service Orchestration:
- Azure Logic Apps: Used for complex scaling workflows involving multiple services, with conditions, loops, and integrations.
- Azure Monitor Custom Metrics: Create metrics aligned with specific application performance indicators (APIs) to trigger scaling actions.
- Azure Event Grid: React to events from various Azure services to initiate scaling based on specific triggers.
Predictive Scaling:
- Azure Machine Learning: Develop predictive models using time-series data and machine learning techniques to forecast demand.
- Azure Time Series Insights: Analyze historical data to identify patterns and trends for predictive scaling.
Cost-Conscious Scaling:
- Azure Cost Management: Analyze spending patterns to identify cost optimization opportunities.
- Azure Budgets: Set spending limits to prevent unexpected cost overruns.
- Rightsizing Recommendations: Utilize Azure Advisor to optimize instance sizes and counts.
By carefully considering these factors and implementing a well-defined autoscaling strategy, organizations can optimize resource utilization, improve application performance, and reduce costs.
Key Monitoring and Optimization Techniques
Effective monitoring and optimization are crucial for maximizing the benefits of autoscaling.
- Azure Monitor:
- Workbooks: Create custom dashboards to visualize scaling metrics, performance counters, and logs.
- Alerts: Configure alerts for critical performance thresholds and scaling events.
- Logs: Analyze detailed logs to identify performance bottlenecks and scaling issues.
- Azure Application Insights: Gain insights into application performance and user behavior to inform scaling decisions.
- Load Testing: Simulate different traffic patterns to evaluate scaling behavior and identify performance bottlenecks.
- A/B Testing: Experiment with different scaling policies to determine the optimal configuration.
- Cost Analysis: Monitor resource utilization and costs to identify optimization opportunities.
Real-World Case Studies
To illustrate the practical benefits of Azure Autoscaling, let's explore a few real-world examples:
E-commerce Platform during Flash Sales
A leading online retailer experienced rapid growth, particularly during flash sales events. To handle sudden traffic spikes, they implemented the following:
- Leveraged VM Scale Sets to rapidly provision additional web servers.
- Utilized Azure Functions for stateless, scalable backend processes.
- Employed Azure Machine Learning to build predictive models for anticipating demand based on historical sales data and external factors.
- Integrated Azure Monitor and Application Insights to track performance metrics and identify optimization opportunities.
By optimizing its autoscaling configuration, the retailer achieved a 65% reduction in compute costs while maintaining 99.99% availability during peak sales.
Real-Time Data Processing Pipeline
A large financial services company processed massive volumes of real-time market data. To handle fluctuating data ingestion rates, they implemented the following:
- Deployed AKS with Cluster Autoscaler to dynamically adjust the number of worker nodes based on workload.
- Integrated Azure Monitor and Application Insights for comprehensive monitoring and performance analysis.
- Utilized Azure Event Grid to trigger autoscaling based on data ingestion rates.
This approach resulted in a 40% reduction in compute costs while ensuring efficient processing of real-time data.
Global Content Delivery Network (CDN)
A global media company sought to improve the performance and scalability of its CDN. They implemented the following:
- Deployed VM Scale Sets across multiple Azure regions to distribute content globally.
- Utilized Azure Front Door for load balancing and traffic optimization.
- Implemented autoscaling based on CDN request rates and cache hit ratios.
This solution enhanced content delivery performance, reduced latency, and improved user experience, while also optimizing infrastructure costs.
Key Takeaways from These Case Studies
- Utilize predictive analytics: Implement machine learning to forecast demand and optimize resource allocation.
- Prioritize monitoring and optimization: Continuously monitor performance metrics and fine-tune scaling policies.
- Focus on cost optimization: Explore options like reserved instances, spot instances, and rightsizing to reduce costs.
Navigating Autoscaling Challenges
While autoscaling offers significant benefits, be prepared to address these potential hurdles:
- Application Architecture: Ensure your applications are designed for horizontal scaling
- Data Tier Scaling: Implement proper connection management and consider using database proxies
- Cost Governance: Establish safeguards against uncontrolled scaling and associated costs
- Performance Consistency: Balance responsiveness with stability in your scaling policies
- Compliance Adherence: Ensure autoscaling actions align with regulatory requirements
Advanced Autoscaling Considerations
- Chaos Engineering
Chaos engineering is a discipline that involves introducing intentional failures into a system to build confidence in the system's capability to withstand unexpected conditions. In the context of autoscaling, this can involve:
- Simulating traffic spikes: To test the system's ability to scale up and handle increased load.
- Injecting delays: To simulate network latency or service disruptions.
- Killing instances: To test the system's ability to recover from instance failures.
By proactively introducing failures, organizations can identify weaknesses in their autoscaling system and make necessary improvements.
- Machine Learning Integration
Leveraging machine learning can significantly enhance autoscaling capabilities:
- Predictive Modeling: Build models to forecast future resource requirements based on historical data and external factors.
- Anomaly Detection: Identify unusual patterns in resource usage to prevent unexpected outages.
- Optimization: Fine-tune scaling policies based on machine learning algorithms to achieve optimal performance and cost-efficiency.
- Root Cause Analysis: Use machine learning to identify the root causes of performance issues.
By integrating machine learning, organizations can make more informed and proactive scaling decisions.
- Autoscaling for Containerized Environments
Containerized environments, such as Kubernetes, present unique challenges and opportunities for autoscaling:
- Horizontal Pod Autoscaler (HPA): Automatically scales the number of replica pods based on CPU utilization or custom metrics.
- Cluster Autoscaler: Adjusts the size of the Kubernetes cluster (number of nodes) to accommodate pod scheduling needs.
- Vertical Pod Autoscaler (VPA): Automatically adjusts resource requests and limits for individual pods based on usage patterns.
Effective autoscaling in containerized environments requires careful consideration of factors like pod scheduling, resource allocation, and cluster management.
- Autoscaling for Big Data Workloads
Big data workloads often exhibit unpredictable and bursty patterns, requiring specialized autoscaling approaches:
- Spark Cluster Autoscaling: Dynamically adjust the number of worker nodes in a Spark cluster based on workload.
- Data Ingestion Scaling: Scale data ingestion components (e.g., Kafka, Flume) to handle varying data rates.
- Data Processing Scaling: Scale compute resources for data processing jobs based on workload intensity.
- Storage Autoscaling: Automatically adjust storage capacity to accommodate growing data volumes.
By implementing effective autoscaling for big data workloads, organizations can optimize resource utilization, improve performance, and reduce costs.
- Autoscaling for Serverless Functions
Serverless functions offer automatic scaling based on incoming events, but fine-tuning is often necessary:
- Cold Start Optimization: Minimize the impact of cold starts through techniques like function warming and reserved concurrency.
- Concurrency Limits: Adjust concurrency limits to balance performance and cost.
- Batching: Combine multiple small requests into a single function invocation to improve efficiency.
- Custom Metrics: Create custom metrics to monitor function performance and trigger scaling actions.
Organizations can achieve better performance and cost efficiency by optimizing serverless function autoscaling.
By carefully addressing these challenges and implementing best practices, organizations can effectively leverage Azure Autoscaling to optimize resource utilization, improve application performance, and reduce costs.
Troubleshooting and Optimization Tips
- Monitor scaling events and errors using Azure Monitor diagnostic logs
- Implement gradual scaling with cool-down periods to prevent sudden resource changes
- Leverage Azure Advisor recommendations for cost optimization and performance tuning
- Use Azure Resource Graph to analyze historical scaling patterns and trends
- Experiment with custom metrics and scaling policies to better match your application's needs
Advanced Troubleshooting and Optimization
For more advanced users, here are some sophisticated techniques to enhance your autoscaling strategy:
Log Analytics for Scaling Patterns
Use Azure CLI to query Log Analytics for detailed insights:
| az monitor log-analytics query \ --workspace-name myWorkspace \ --analytics-query "AutoscaleScaleActionsLog | where ResourceId contains 'myResourceId' | summarize ScaleActions=count() by bin(TimeGenerated, 1h), ScaleDirection=iff(Details contains 'scale up', 'Scale Out', 'Scale In') | render timechart" \ --output table |
This query visualizes scaling actions over time, helping identify patterns and potential issues.
Custom Azure Monitor Workbooks
Create workbooks that correlate scaling events with performance metrics:
| az monitor workbook create \ --resource-group myResourceGroup \ --name "Scaling Events vs CPU Usage" \ --location eastus \ --categories "workbook" \ --display-name "Scaling Events vs CPU Usage" \ --source-id "/subscriptions/subId/resourceGroups/myResourceGroup" \ --version "1.0" \ --tags "autoscaling" "performance" \ --serialized-data '{ "version": "Notebook/1.0", "items": [ { "type": 3, "content": { "version": "KqlItem/1.0", "query": "let scaleEvents = AutoscaleScaleActionsLog | where ResourceId contains \"myResourceId\";\nlet perfMetrics = Perf | where ObjectName == \"Processor\" and CounterName == \"% Processor Time\";\nscaleEvents\n| join kind=leftouter perfMetrics on $left.TimeGenerated == $right.TimeGenerated\n| project TimeGenerated, ScaleAction=iff(Details contains \"scale up\", \"Scale Out\", \"Scale In\"), CPUUsage=CounterValue\n| render timechart", "size": 0, "timeContext": { "durationMs": 86400000 }, "queryType": 0, "resourceType": "microsoft.operationalinsights/workspaces" }, "name": "Scaling Events vs CPU Usage" } ] }' |
A/B Testing Scaling Policies
Implement A/B testing using Azure Traffic Manager to compare different scaling strategies:
| az network traffic-manager profile create \ --name myABTestProfile \ --resource-group myResourceGroup \ --routing-method Weighted \ --unique-dns-name myabtest az network traffic-manager endpoint create \ --name policy-A \ --profile-name myABTestProfile \ --resource-group myResourceGroup \ --type azureEndpoints \ --target-resource-id "/subscriptions/subscriptionId/resourceGroups/myResourceGroup/providers/Microsoft.Web/sites/policy-A-app" \ --weight 50 az network traffic-manager endpoint create \ --name policy-B \ --profile-name myABTestProfile \ --resource-group myResourceGroup \ --type azureEndpoints \ --target-resource-id "/subscriptions/subscriptionId/resourceGroups/myResourceGroup/providers/Microsoft.Web/sites/policy-B-app" \ --weight 50 |
The Future of Autoscaling in Azure
Microsoft continually enhances Azure's autoscaling capabilities. Keep an eye on emerging trends:
- AI-driven predictive scaling across a broader service spectrum
- Enhanced cross-service autoscaling coordination
- More granular controls for serverless and container-based autoscaling
By staying informed about these advancements and adapting your strategies accordingly, you can harness the full potential of Azure autoscaling, ensuring your infrastructure remains agile, efficient, and primed for future challenges.
FAQs
Q: How does autoscaling work with Azure Container Instances (ACI)?
A: Azure Container Instances don't have built-in autoscaling. However, you can implement autoscaling for ACI using Azure Functions or Logic Apps to monitor metrics and create/delete container instances as needed.
Q: How does autoscaling interact with Azure Availability Zones?
A: When configuring VM Scale Sets or AKS clusters with autoscaling, you can distribute instances across Availability Zones for high availability. The autoscaler will maintain balance across zones when scaling out or in.
Q: What's the difference between instance-level and subscription-level autoscaling in Azure?
A: Instance-level autoscaling applies to individual resources or resource groups, while subscription-level autoscaling (like Azure subscription quotas) affects the entire subscription. Most autoscaling discussions focus on instance-level scaling.
Q: Is there a way to implement cross-region autoscaling in Azure?
A: Azure doesn't provide native cross-region autoscaling. However, you can implement a custom solution using Azure Traffic Manager or Front Door to distribute traffic, and use separate autoscaling configurations in each region.
Q: What's the relationship between autoscaling and Azure Load Testing?
A: Azure Load Testing can be used to simulate high load scenarios and test your autoscaling configurations. It helps ensure that your autoscaling rules respond correctly to increased demand before you encounter it in production.






