
In an AWS environment, sometimes it can be difficult to adjust to fluctuating workloads and expenses. For example, an e-commerce website might encounter spikes in traffic during the holiday season, whereas a news website might witness an unexpected increase in visitors during major events. It's critical to keep costs under control while preserving peak performance in both situations. These issues are resolved by AWS Autoscaling.
This blog will cover the fundamentals of autoscaling, its benefits, and practical steps for implementing it in your AWS architecture.
What is Autoscaling in AWS?
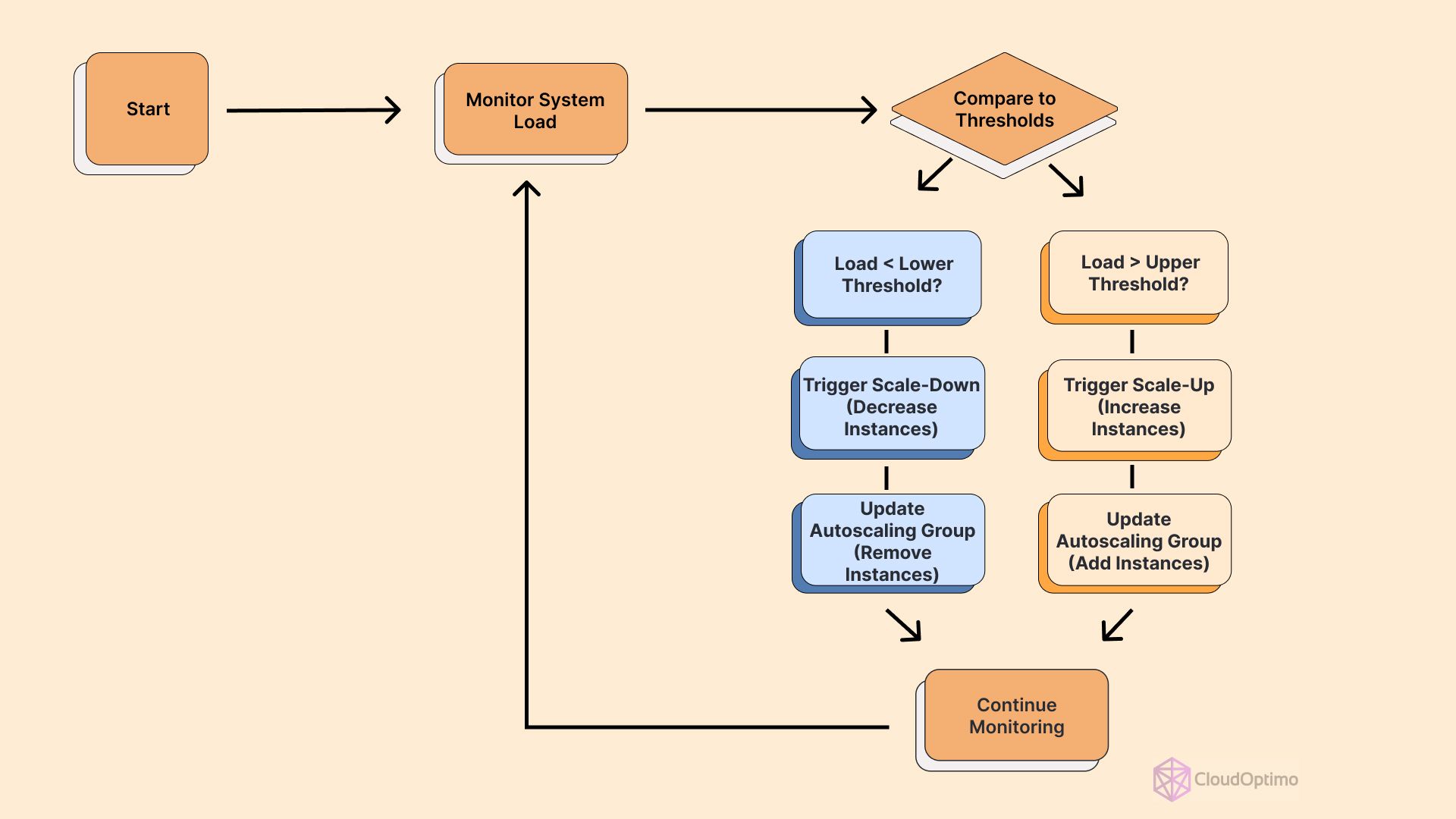
Autoscaling is a powerful feature from Amazon Web Services (AWS) that automatically adjusts the number of compute resources in your application’s architecture based on predefined conditions. This intelligent scaling ensures you have the right amount of resources available to handle your application’s workload at any time, optimizing both performance and cost.
The Core Benefits of Autoscaling
- Cost Optimization: By scaling resources up or down based on demand, you only pay for what you need and when needed.
- Achieving High Availability with AWS Autoscaling: Autoscaling helps maintain application availability by replacing underperforming instances and balancing load across multiple Availability Zones.
- Enhanced User Experience: With resources that adapt to traffic patterns, your applications can maintain consistent performance even during peak loads.
- Simplified Management: Once configured, autoscaling operates automatically, reducing the need for manual intervention and monitoring.
AWS Services That Support Autoscaling
While EC2 Auto Scaling is perhaps the most well-known implementation, AWS offers autoscaling capabilities across various services.
| Service | Scaling Unit | Key Metrics | Use Cases |
| EC2 Auto Scaling | EC2 Instances | CPU Utilization, Network I/O | Web applications, Batch processing |
| ECS | Tasks | CPU Utilization, Memory Utilization | Containerized applications |
| Lambda | Function | Invocation rate, Duration | Serverless event-driven workloads |
| DynamoDB | Read/Write Capacity Units | Consumed Capacity, Throttled Requests | NoSQL database workloads |
| Aurora Serverless | Aurora Capacity Units (ACUs) | Connections, CPU Utilization | Variable database workloads |
Let's explore how autoscaling works in different AWS services:
- EC2 Auto Scaling
EC2 Auto Scaling is the foundation of autoscaling in AWS. It allows you to automatically adjust the number of EC2 instances in a group based on specified conditions.
Key Features:
- Scaling policies based on metrics like CPU utilization, network traffic, etc
- Scheduled scaling for predictable workload changes
- Integration with Elastic Load Balancing for distributed traffic
- Support for multiple instance types and purchase options (On-Demand, Spot, Reserved Instances)
Advanced Features:
- Multi-AZ Auto Scaling groups for high availability
- Integration with Spot Instance fleets for cost optimization
- Use of launch templates for versioning and management of instance configurations
Configuration Steps:
- Create a launch template or launch configuration
- Define your Auto Scaling group
- Configure scaling policies
- Set up notifications (optional)
CLI Example for creating an Auto Scaling group:
| aws autoscaling create-auto-scaling-group \ --auto-scaling-group-name my-asg \ --launch-template LaunchTemplateName=my-launch-template,Version='$Latest' \ --min-size 1 \ --max-size 5 \ --desired-capacity 2 \ --vpc-zone-identifier "subnet-5xxxxxx7,subnet-6xxxxxb,subnet-cxxxxx2"\ --target-group-arns arn:aws:elasticloadbalancing:us-west-2:12345xxxxxxx:targetgroup/my-targets/7xe2dxxx2xxxxx7 |
Best Practices:
- Use a mix of instance types to optimize cost and performance
- Implement gradual scaling to avoid sudden resource changes
- Regularly review and update your scaling policies
- Implement predictive scaling using machine learning forecasts for proactive capacity management
Note - You can use CloudOptimo’s OptimoGroup to simplify autoscaling with spot instances and reduce the risk of interruptions.
- Amazon ECS (Elastic Container Service) Autoscaling
ECS Autoscaling allows you to automatically adjust the number of tasks running in your ECS cluster based on CPU and memory utilization or custom CloudWatch metrics.
Key Features:
- Service Auto Scaling to adjust the desired count of tasks
- Capacity Provider Autoscaling to manage the underlying EC2 instances
Configuration Steps:
- Set up an ECS cluster
- Create a service with the desired task count
- Configure Service Auto Scaling
- (Optional) Set up Capacity Providers for EC2 autoscaling
CLI example for creating an ECS service with Auto Scaling
| aws ecs create-service \ --cluster mycluster \ --service-name myservice \ --task-definition mytask:1 \ --desired-count 2 \ --launch-type EC2 \ --service-registries "registryArn=arn:aws:servicediscovery:region:account:service/srv-abcd1234efgh5678" \ --auto-scaling-group-provider "autoScalingGroupArn=arn:aws:autoscaling:region:account:autoScalingGroup:group-id:autoScalingGroupName/asg-name,managedScaling={status=ENABLED,targetCapacity=75},managedTerminationProtection=ENABLED" |
Best Practices:
- Use target-tracking scaling policies for more precise control
- Implement task-level autoscaling before considering cluster autoscaling
- Monitor and adjust your scaling thresholds regularly
- AWS Lambda Autoscaling
Lambda automatically scales by running additional instances of your function in response to incoming events. While you don't need to configure autoscaling explicitly, understanding how it works can help you optimize your Lambda functions.
Key Aspects:
- Concurrent executions: Lambda can scale up to your account's concurrency limit
- Burst concurrency: Provides initial burst capacity for sudden traffic spikes
- Reserved concurrency: Limits the maximum number of concurrent executions for a function
Best Practices:
- Design functions to be stateless and idempotent
- Use provisioned concurrency for latency-sensitive applications
- Monitor and adjust concurrency limits as needed
Technical Deep Dive:
Lambda's autoscaling works by maintaining a pool of execution environments. When a function is invoked, Lambda allocates it to an available environment or creates a new one if needed. The scaling is managed by the Lambda service itself, which can scale to thousands of concurrent executions within seconds.
Scaling Metrics:
- Concurrent executions: The number of function instances running simultaneously
- Invocation rate: The number of times your function is invoked per second
- Duration: The time it takes for your function to execute
CLI example for enabling Auto Scaling on a DynamoDB table
| aws application-autoscaling register-scalable-target \ --service-namespace dynamodb \ --resource-id "table/MyTable" \ --scalable-dimension "dynamodb:table:ReadCapacityUnits" \ --min-capacity 5 \ --max-capacity 100 aws application-autoscaling put-scaling-policy \ --service-namespace dynamodb \ --resource-id "table/MyTable" \ --scalable-dimension "dynamodb:table:ReadCapacityUnits" \ --policy-name "MyScalingPolicy" \ --policy-type "TargetTrackingScaling" \ --target-tracking-scaling-policy-configuration file://config.json |
4. Amazon DynamoDB Autoscaling
DynamoDB offers autoscaling of read and write capacity units, ensuring your tables can handle varying workloads while optimizing costs.
Key Features:
- Automatic scaling of provisioned capacity
- Support for both table-level and global secondary index-level autoscaling
- Integration with Application Auto Scaling for customized scaling policies
Configuration Steps:
- Enable autoscaling for your DynamoDB table
- Set target utilization percentage
- Define minimum and maximum capacity units
Best Practices:
- Start with a conservative target utilization (around 70%)
- Use on-demand capacity mode for unpredictable workloads
- Regularly review CloudWatch metrics to fine-tune your scaling settings
Implementing Custom Metrics for DynamoDB Autoscaling:
You can use Application Auto Scaling to define custom scaling policies. Here's an example of how to create a custom CloudWatch metric and use it for scaling:
- Create a custom metric in CloudWatch that tracks your application-specific data.
- Create a scaling policy using this custom metric:
| aws application-autoscaling put-scaling-policy \ --service-namespace dynamodb \ --resource-id "table/MyTable" \ --scalable-dimension "dynamodb:table:ReadCapacityUnits" \ --policy-name "MyCustomMetricPolicy" \ --policy-type TargetTrackingScaling \ --target-tracking-scaling-policy-configuration file://config.json |
Where config.json contains:
| { "TargetValue": 70.0, "CustomizedMetricSpecification": { "MetricName": "MyCustomMetric", "Namespace": "MyNamespace", "Dimensions": [ { "Name": "TableName", "Value": "MyTable" } ], "Statistic": "Average", "Unit": "Count" }, "ScaleOutCooldown": 60, "ScaleInCooldown": 60 } |
5. Amazon Aurora Autoscaling
Aurora Serverless v2 provides autoscaling capabilities for your relational database, automatically adjusting capacity based on application demand.
Key Features:
- Seamless scaling from minimum to maximum ACU (Aurora Capacity Units)
- Pay-per-second billing for used resources
- Automatic scaling of both compute and memory
Configuration Steps:
- Create an Aurora Serverless v2 cluster
- Set minimum and maximum ACU limits
- Configure scaling parameters (optional)
CLI example for creating an Aurora Serverless v2 cluster with autoscaling
| aws rds create-db-cluster \ --db-cluster-identifier myserverlessv2cluster \ --engine aurora-mysql \ --engine-version 8.0.mysql_aurora.3.02.0 \ --master-username admin \ --master-user-password mypassword \ --db-cluster-parameter-group-name default.aurora-mysql8.0 \ --vpc-security-group-ids sg-0123456789abcdef0 \ --serverless-v2-scaling-configuration MinCapacity=0.5,MaxCapacity=16 aws rds create-db-instance \ --db-instance-identifier myserverlessv2instance \ --db-cluster-identifier myserverlessv2cluster \ --engine aurora-mysql \ --db-instance-class db.serverless aws rds modify-db-cluster \ --db-cluster-identifier myserverlessv2cluster \ --serverless-v2-scaling-configuration MinCapacity=1,MaxCapacity=32 |
Best Practices:
- Use Aurora Serverless v2 for variable or unpredictable workloads
- Set appropriate ACU limits based on your application's needs
- Monitor scaling events and adjust parameters as necessary
- Amazon EMR Autoscaling
AWS EMR (Elastic MapReduce) supports autoscaling for big data processing workloads, allowing you to adjust the number of instances in your cluster dynamically.
Key Features:
- Instance group-level autoscaling
- Support for both uniform and instance fleet node groups
- Custom rules based on YARN metrics or CloudWatch metrics
Configuration Steps:
- Create an EMR cluster with instance groups or instance fleets
- Configure autoscaling policies for each instance group
- Define scaling rules and thresholds
CLI example for creating an EMR cluster with autoscaling
| aws emr create-cluster \ --name "AutoscalingCluster" \ --release-label emr-5.30.0 \ --applications Name=Hadoop Name=Spark \ --ec2-attributes KeyName=mykey \ --instance-groups file://instancegroups.json \ --auto-scaling-role EMR_AutoScaling_DefaultRole \ --service-role EMR_DefaultRole { "InstanceGroups": [ { "Name": "Master nodes", "InstanceRole": "MASTER", "InstanceType": "m5.xlarge", "InstanceCount": 1 }, { "Name": "Core nodes", "InstanceRole": "CORE", "InstanceType": "m5.xlarge", "InstanceCount": 2, "AutoScalingPolicy": { "Constraints": { "MinCapacity": 2, "MaxCapacity": 10 }, "Rules": [ { "Name": "ScaleOutMemoryPercentage", "Description": "Scale out if YARNMemoryAvailablePercentage is less than 15", "Action": { "SimpleScalingPolicyConfiguration": { "AdjustmentType": "CHANGE_IN_CAPACITY", "ScalingAdjustment": 1, "CoolDown": 300 } }, "Trigger": { "CloudWatchAlarmDefinition": { "ComparisonOperator": "LESS_THAN", "EvaluationPeriods": 1, "MetricName": "YARNMemoryAvailablePercentage", "Namespace": "AWS/ElasticMapReduce", "Period": 300, "Statistic": "AVERAGE", "Threshold": 15, "Unit": "PERCENT" } } } ] } } ] } |
Best Practices:
- Use instance fleets for more flexible instance type selection
- Implement gradual scaling to avoid disrupting running jobs
- Monitor cluster utilization and adjust policies accordingly
| Service | Step 1 | Step 2 | Step 3 | Step 4 |
| EC2 Auto Scaling | Create Launch Template | Define Auto Scaling Group | Configure Scaling Policies | Set up Notifications |
| ECS | Set up ECS Cluster | Create Service | Configure Service Auto Scaling | Set up Capacity Providers |
| DynamoDB | Enable Autoscaling | Set Target Utilization | Define Min/Max Capacity | Create Scaling Policy |
| Aurora Serverless | Create Serverless Cluster | Set Min/Max ACUs | Configure Scaling Parameters | - |
Implementing Cross-Service Autoscaling Strategies
While individual service autoscaling is powerful, combining autoscaling across multiple services can lead to even greater efficiency and cost savings. Here are some strategies to consider:
Application-wide Autoscaling
Coordinate autoscaling across your entire application stack:
- EC2 Auto Scaling for application servers
- DynamoDB autoscaling for the database layer
- Lambda for event-driven processing
- ECS for containerized microservices
Implement this by:
- Using AWS CloudFormation or Terraform for infrastructure-as-code
- Leveraging AWS Systems Manager to manage and coordinate scaling actions
- Implementing custom metrics and alarms in CloudWatch to trigger cross-service scaling
Predictive Autoscaling
Utilize machine learning to predict scaling needs:
- AWS SageMaker to build and train predictive models
- AWS Auto Scaling predictive scaling feature for EC2
- Custom ML models for other services like DynamoDB or Aurora
Implement this by:
- Collecting and analyzing historical usage data
- Training models to predict future resource needs
- Integrating predictions with your autoscaling configurations
Cost-Aware Autoscaling
Optimize autoscaling decisions based on cost considerations:
- Utilize CloudOptimo’s OptimoGroup to maximize cost savings with Spot Instances while guaranteeing uninterrupted performance
- Implement CloudOptimo’s OptimoSizing recommendations
- Leverage CloudOptimo’s CostSaver to analyze and optimize scaling patterns
Implement this by:
- Setting up detailed billing and cost allocation tags
- Creating custom CloudWatch metrics for cost per request or transaction
- Adjusting autoscaling policies based on cost-performance trade-offs
| Category | Best Practice | Benefit |
| Cost Optimization | Use mixed instance types | Balance performance and cost |
| Performance | Implement gradual scaling | Avoid sudden resource changes |
| Monitoring | Regularly review CloudWatch metrics | Fine-tune scaling thresholds |
| Security | Use IAM roles for autoscaling operations | Enhance security posture |
| Reliability | Configure multi-AZ deployments | Improve availability |
Limitations and Potential Pitfalls of Autoscaling
While powerful, autoscaling is not a silver bullet. Be aware of these limitations:
- Database bottlenecks: Autoscaling application servers may lead to database connection limits. Consider implementing connection pooling or database proxy solutions.
- Cold start latency: For services like Lambda, be mindful of cold start times when scaling rapidly.
- Cost unpredictability: While autoscaling can optimize costs, it can also lead to unexpected expenses if not properly configured.
- Application-specific scaling metrics: Generic metrics like CPU utilization may not always reflect your application's actual performance needs.
Comparative Analysis of Autoscaling Approaches
While autoscaling principles remain similar across services, the implementation and use cases can vary:
| Autoscaling Service | Best Suited For | Key Features | Considerations |
| EC2 Auto Scaling | Traditional applications with predictable or gradually changing load patterns |
|
|
| ECS Autoscaling | Containerized applications, rapid scaling |
|
|
| Lambda Autoscaling | Event-driven, short-lived functions, burstable workloads |
|
|
| DynamoDB Autoscaling | NoSQL databases with fluctuating read/write throughput |
|
|
| Aurora Autoscaling | Relational databases with unpredictable workloads |
|
|
Choose your autoscaling approach based on your application architecture, expected load patterns, and specific service capabilities.
Complex Autoscaling Scenarios
Let's explore some advanced use cases that involve autoscaling across multiple services:
- E-commerce platform during flash sale:
- EC2 Auto Scaling for web servers
- ECS for microservices
- DynamoDB autoscaling for product catalog
- Lambda for order processing
- ElastiCache for session management
Challenge: Coordinate scaling across all services to handle sudden traffic spikes without overspending.
- Real-time data processing pipeline:
- Kinesis Data Streams for data ingestion
- EC2 Auto Scaling for stream processing applications
- EMR for batch processing
- Redshift for data warehousing
Challenge: Balance real-time processing needs with batch processing efficiency while managing costs.
- Multi-region disaster recovery:
Route 53 for global load balancing
You can also use services like CloudFlare or DynDns to manage DNS load balancing.
- EC2 Auto Scaling in multiple regions
- Aurora Global Database with autoscaling
- S3 Cross-Region Replication
Challenge: Ensure consistent autoscaling policies across regions while optimizing for latency and compliance requirements.
Monitoring and Optimizing Autoscaling
To ensure your autoscaling setup is effective, consider the following best practices:
- Comprehensive Monitoring
- Use CloudWatch dashboards to visualize scaling activities across services
- Set up CloudWatch alarms for unusual scaling events or threshold breaches
- Implement custom metrics to track application-specific performance indicators
| Metric Name | Description | Relevant Services |
| CPU Utilization | Percentage of allocated EC2 compute units used | EC2, ECS |
| Memory Utilization | Percentage of allocated memory used | ECS, Lambda |
| Request Count Per Target | Number of requests completed per target in an ALB | EC2 Auto Scaling |
| Invocation Rate | Number of times a function is invoked per second | Lambda |
| Consumed Read/Write Capacity Units | Number of capacity units consumed | DynamoDB |
Trade-offs between scaling metrics:
- CPU Utilization: Easy to measure but may only reflect application performance accurately for some workloads.
- Request Count: Directly relates to application load but may not account for request complexity.
- Custom Application Metrics: Most accurate but require additional setup and maintenance.
- Regular Performance Reviews
- Analyze scaling history and patterns using CloudWatch Insights
- Review and adjust scaling thresholds and policies periodically
- Conduct load testing to validate autoscaling effectiveness
- Continuous Optimization
- Leverage CloudOptimo’s CostSaver for cost optimization recommendations
- Explore new instance types or compute options as they become available
- Stay updated with AWS service improvements and new autoscaling features
- Documentation and Knowledge Sharing
- Maintain detailed documentation of your autoscaling configurations
- Conduct regular team reviews of autoscaling strategies
- Implement a change management process for autoscaling modification
Troubleshooting Common Autoscaling Issues
- Slow scaling response
- Issue: Resources don't scale fast enough to meet demand.
- Solution: Review your CloudWatch alarm periods and scaling policy cooldown times. Consider reducing these times, but be cautious of increased costs due to frequent scaling actions.
- Instances terminated unexpectedly
- Issue: Newly launched instances are terminated shortly after starting.
- Solution: Check your scale-in protection settings and instance health check configurations. Ensure your user data scripts are completed successfully.
- Cost spikes
- Issue: Unexpected scaling leads to high costs.
- Solution: Implement scaling limits and review your scaling metrics. Set up CloudWatch alarms for unusual scaling events.
- Application performance issues during scaling
- Issue: Performance degrades during scaling events.
- Solution: Ensure your application is stateless and can handle instance churn effectively. Implement proper load balancing and database connection management.
The following are the examples:
- EC2 Auto Scaling:
- Issue: Instances are launched but immediately terminated.
- Solution: Check your user data script, and ensure it's completed successfully.
- ECS:
- Issue: Tasks are placed but fail to start.
- Solution: Verify your task definition and set all required environment variables.
- DynamoDB:
- Issue: Table needs to scale up despite increased traffic.
- Solution: Check if you've hit your account limits, and verify your scaling policy configuration.
Challenges and Considerations
While autoscaling offers numerous benefits, it's important to be aware of potential challenges:
- Application Design
- Ensure your application is stateless and can handle dynamic scaling
- Implement proper session management and data consistency mechanisms
- Database Scaling
- Be mindful of connection limits when scaling application servers
- Consider read replicas or database proxy solutions for improved scalability
- Cost Management
- Implement safeguards to prevent runaway scaling and unexpected costs
- Regularly review and optimize your Reserved Instance and Savings Plans portfolio
- Performance Tuning
- Balance between responsiveness and stability in your scaling policies
- Consider warm-up periods for newly launched instances or containers
- Compliance and Security
- Ensure autoscaling actions comply with your security and compliance requirements
- Implement proper IAM roles and policies for autoscaling operations
Cost Analysis
Effective autoscaling can lead to significant cost savings. For example, a company using EC2 Auto Scaling with a mix of On-Demand and Spot Instances reported a 70% reduction in compute costs while maintaining performance during peak hours.
To maximize cost benefits:
- Use AWS Cost Explorer to analyze your scaling patterns and identify optimization opportunities.
- Implement automated notifications for unusual scaling events that might impact costs.
- Proactively manage your Reserved Instance and Savings Plans by regularly assessing your base capacity needs. Leverage CloudOptimo's CostSaver to optimize your portfolio and reduce cloud expenses.
| Challenge | Description | Potential Solution |
| Slow Scaling Response | Resources don't scale fast enough to meet demand | Adjust CloudWatch alarm periods and cooldown times |
| Cost Spikes | Unexpected scaling leads to high costs | Implement scaling limits and better monitoring |
| Application Performance Issues | Performance degrades during scaling events | Ensure the application is stateless and can handle instance churn |
| Database Bottlenecks | Database can't keep up with scaled application servers | Implement read replicas or database proxy solutions |
Concrete Example: A media streaming company implemented auto-scaling for their EC2-based transcoding farm. By scaling down during off-peak hours and utilizing Spot Instances, they achieved:
- 40% reduction in EC2 costs
- 99.9% availability maintained
- Ability to handle 3x normal load during peak events
Key to their success:
- Use of Spot Instances for non-critical workloads
- Implementing predictive scaling based on historical data
- Regular review and adjustment of scaling policies
Future Developments in AWS Autoscaling
AWS continually enhances its autoscaling capabilities. Keep an eye out for:
- Improved machine learning-driven predictive scaling across more services
- Enhanced cross-service autoscaling orchestration
- More granular controls for serverless autoscaling in services like Lambda and Fargate
These upcoming features promise to streamline autoscaling processes further and improve resource optimization. As AWS evolves, so too will the strategies for implementing efficient, cost-effective autoscaling solutions.
To stay at the forefront of these developments:
- Regularly review AWS documentation and announcements
- Participate in AWS community forums and events
- Experiment with new features in non-production environments
By staying informed and adaptable, you'll be well-positioned to leverage the full potential of AWS autoscaling, ensuring your infrastructure remains agile, efficient, and ready for whatever challenges lie ahead.
FAQs
Q: How does AWS ensure data consistency during autoscaling events?
A: AWS uses strategies like distributed caching and database replication to maintain data consistency. For EC2, Elastic Load Balancing helps distribute traffic evenly across scaled instances.
Q: How does autoscaling work with spot instances?
A: You can configure Auto Scaling groups to use spot instances, which can significantly reduce costs. AWS will automatically request spot instances based on your specifications and replace them if they're interrupted.
For example, you can use CloudOptimo’s OptimoGroup to simplify autoscaling with spot instances and reduce the risk of interruptions.
Q: What's the smallest interval at which autoscaling can occur?
A: The minimum interval depends on the service. For EC2 Auto Scaling, it's 60 seconds. Some services like Lambda scale almost instantaneously.
Q: How does autoscaling work with containerized applications in AWS Fargate?
A: Fargate allows you to define CPU and memory requirements for your containers. ECS or EKS can then automatically scale the number of tasks or pods based on your defined metrics.
Q: What's the difference between AWS Auto Scaling and Application Auto Scaling?
A: AWS Auto Scaling provides a unified way to manage scaling for multiple resources, while Application Auto Scaling is the underlying service that provides scaling functionality for individual AWS services.






