

1. Introduction
1.1 The Evolution of AI Hardware Acceleration
The rapid growth of artificial intelligence has consistently pushed the boundaries of computing infrastructure. Initially reliant on general-purpose CPUs, the industry quickly pivoted to GPUs for their parallel processing power. However, the increasing complexity and scale of modern AI models has revealed the limitations of even high-end GPUs, prompting a shift toward more specialized hardware.
Timeline of AI Hardware Evolution
| Year | Milestone | Description |
| 2006 | NVIDIA CUDA | Enabled general-purpose computing on GPUs, catalyzing early deep learning progress. |
| 2011 | Rise of GPU-accelerated ML | GPUs like NVIDIA’s GTX 580 gained traction in academia and startups. |
| 2015 | Google TPUs | Google introduced Tensor Processing Units, custom ASICs for TensorFlow. |
| 2018 | AWS Inferentia announced | Amazon entered the AI hardware race with its first inference-optimized chip. |
| 2020 | AWS Trainium announced | Focused on high-performance model training in the cloud. |
| 2022 | Inferentia2 released | A second-generation chip with better performance and support for larger models. |
| 2023 | Trn1n Instances | Enhanced Trainium-based instances launched with faster networking. |
This evolution reflects the industry’s transition from general-purpose hardware to highly specialized silicon designed for specific AI workloads.
1.2 AWS’s Custom Silicon Strategy

Source: AWS Events
AWS's approach to AI infrastructure centers on vertical integration—owning the full stack from silicon to cloud. With Inferentia and Trainium, AWS can deliver optimized performance and lower costs to customers running ML workloads at scale. These chips are part of AWS's broader effort, alongside Graviton (for general compute), to reduce dependency on third-party chipmakers and control both performance tuning and TCO.
1.3 Inferentia and Trainium in the AI Landscape
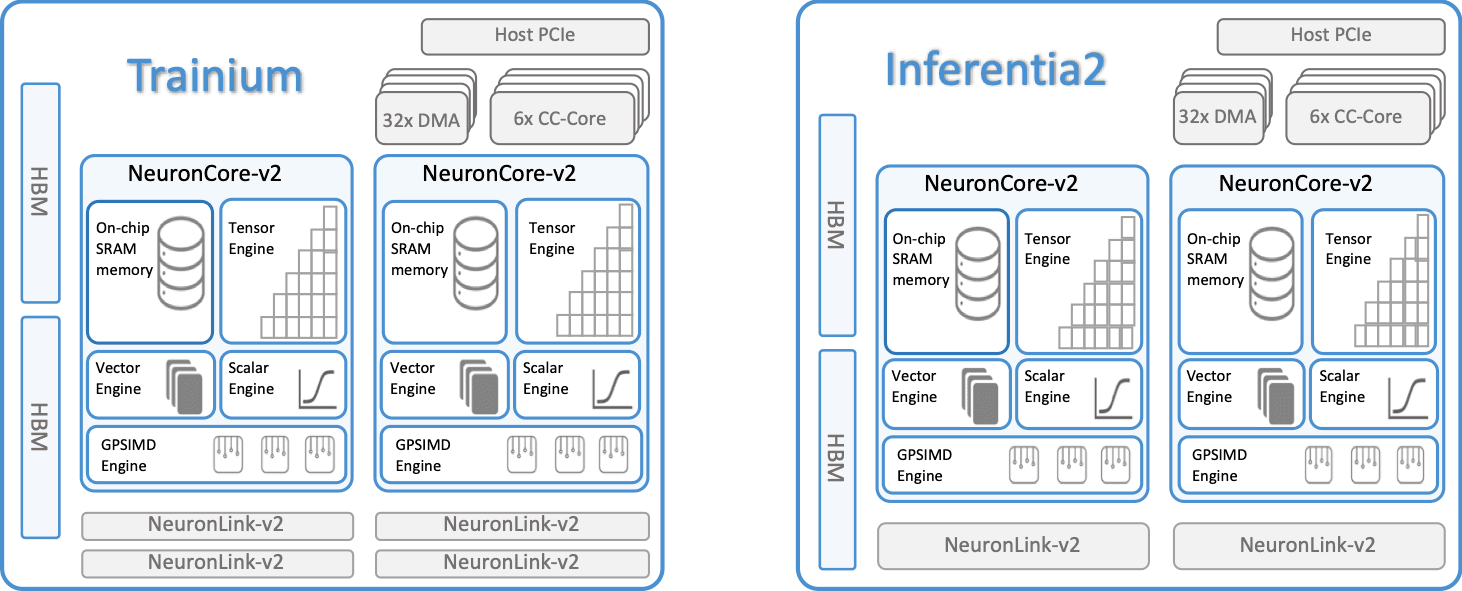
Source: AWS Docs
Inferentia and Trainium occupy distinct yet complementary roles:
- Inferentia is tailored for high-throughput, low-latency inference.
- Trainium targets the computationally intensive process of training deep learning models.
They directly compete with NVIDIA's A100/H100 and Google's TPU v4/v5e but differentiate themselves through seamless AWS integration, predictable pricing, and optimized infrastructure.
Together, these chips position AWS as a full-stack provider capable of supporting both training and deployment of machine learning models at industrial scale.
2. Amazon Inferentia: Architecture and Capabilities
Amazon Inferentia is AWS’s purpose-built chip for accelerating machine learning inference workloads. First introduced in 2018 and launched in 2019 with Inf1 instances, Inferentia was designed to reduce inference costs while maintaining high throughput and low latency—especially in production environments where models are already trained and deployed at scale.
2.1 Design Principles and AI-Focused Innovations
Inferentia was built around the core idea that inference workloads have fundamentally different requirements than training. While training demands massive compute and memory for large batch sizes and backpropagation, inference emphasizes low latency, high requests-per-second (RPS), and efficient scaling.
Key design priorities include:
- Low-latency execution for real-time applications like chatbots and voice assistants
- High throughput for batch inference at scale
- Support for multiple precision formats to balance accuracy and performance
- Energy efficiency, with performance-per-watt optimization
Inferentia chips are deeply integrated into the AWS ecosystem, supported by the AWS Neuron SDK, and designed to work seamlessly within Amazon EC2, ECS, EKS, and SageMaker environments.
2.2 Inferentia1 vs. Inferentia2: What’s New and Improved
The second generation of Inferentia—Inferentia2, launched in 2022—delivered significant improvements in compute capability, memory architecture, and networking.
| Specification | Inferentia1 | Inferentia2 |
| Launch Year | 2019 | 2022 |
| Process Technology | 16nm | 7nm |
| NeuronCore Version | v1 | v2 |
| Throughput | Up to 128 TOPS | 4x the throughput of Inferentia1 |
| Model Support | Moderate-sized models | Large models, including LLMs |
| Networking | Limited | Up to 800 Gbps with EFA |
| Supported Precision | FP16, INT8 | BF16, FP16, INT8 |
| Deployment | Inf1 Instances | Inf2 Instances |
Inferentia2 is well-suited for the latest generation of models, including BERT variants, ResNet, and recommendation systems that require higher precision and throughput.
2.3 NeuronCore: Specialized Inference Engines
Each Inferentia chip contains several NeuronCores, which are optimized hardware blocks specifically for deep learning inference operations. These cores are responsible for executing the compiled model graph produced by the Neuron Compiler (neuron-cc).
Key capabilities of NeuronCores include:
- Matrix multiplication acceleration
- Parallel data paths for higher throughput
- Support for batched inference
- Efficient execution of models in TensorFlow, PyTorch, and MXNet
NeuronCores are the heart of the chip, enabling developers to achieve low latency without sacrificing model complexity or batch size.
2.4 System and Memory Architecture for Inference Workloads
Inferentia's architecture is optimized for fast memory access and minimal data movement—two crucial elements for real-time inference.
Key highlights:
- On-chip SRAM used as fast-access memory for weight loading and intermediate activations
- Shared DRAM pools for larger model parameters
- Efficient memory tiling and caching via the Neuron SDK
This design reduces the overhead of moving data between memory and compute units, improving throughput without excessive power consumption.
2.5 Supported Data Types and Precision Modes
Inferentia supports a range of precision formats tailored for inference:
| Precision Mode | Use Case | Performance Benefit |
| INT8 | High-throughput, latency-sensitive workloads | Max throughput with quantization |
| FP16 | Balanced performance and precision | Fast, with minimal loss in accuracy |
| BF16 | Deep learning model compatibility | Better numerical stability for LLMs |
Developers can use mixed precision where appropriate—automatically handled by the Neuron compiler—to achieve the best performance-to-accuracy ratio for each model.
3. Amazon Trainium: Deep Learning Training at Scale
Amazon Trainium, introduced in 2020 and launched with Trn1 instances, is AWS’s custom chip designed for training the most demanding machine learning models in the cloud. It supports distributed training at scale for use cases like large language models, image generation, speech synthesis, and more.
Trainium is part of AWS’s broader goal to make training more accessible, scalable, and cost-effective compared to relying solely on GPUs.
3.1 Design Philosophy and Use Cases
While Inferentia focuses on serving predictions, Trainium is designed to create those models—often requiring millions or billions of parameters and massive compute cycles.
Targeted use cases include:
- Transformer-based LLMs (e.g., GPT, BERT, T5)
- Vision models (e.g., ResNet, EfficientNet)
- Recommendation models with high-dimensional embeddings
- Reinforcement learning workloads
Trainium’s architecture is tuned to handle both data parallelism and model parallelism, enabling it to scale across multiple chips and nodes efficiently.
3.2 Compute Capacity, BF16/FP32 Support, and Throughput
Trainium chips include the next-generation NeuronCore-v2 units, significantly upgraded over those found in Inferentia.
Notable features:
- Support for BF16 and FP32: BF16 for performance, FP32 for high-precision use cases
- Stochastic rounding: Helps maintain numerical stability in training loops
- Compiler-level optimization: The Neuron SDK compiles models into executable graphs tailored to the hardware layout
This results in higher throughput per watt than many traditional GPUs, allowing users to train larger models faster and at lower cost.
3.3 Memory Subsystem Design and I/O Architecture
Training large models requires massive memory bandwidth and fast access to weights and gradients. Trainium delivers this through:
- Large on-chip SRAM cache per core
- Direct-attached high-bandwidth memory (HBM)
- Inter-core communication fabric for efficient parallel training
This memory architecture reduces bottlenecks during backpropagation and optimizer steps, which are typically the most memory-intensive parts of training.
3.4 Networking and Scalability with EFA and Multi-Chip Topologies
AWS Trn1 and Trn1n instances use Elastic Fabric Adapter (EFA) to achieve high-bandwidth, low-latency networking across multiple nodes—critical for distributed training.
| Feature | Trn1 | Trn1n |
| Max EFA Bandwidth | 400 Gbps | 800 Gbps |
| Instance Size | up to 16 Trainium chips | up to 32 Trainium chips |
| Training Support | PyTorch DDP, SageMaker, TensorFlow MultiWorker | Same, plus faster interconnect for LLMs |
| Use Case Fit | General DL workloads | Multi-node LLMs, fine-tuning, foundation models |
Together with the Neuron SDK, Trainium enables seamless horizontal scaling of training jobs using frameworks like PyTorch Lightning, TensorFlow, and Hugging Face Accelerate.
4. AWS Instance Families
As AWS continues to refine its custom silicon, these advancements are surfaced to users through tailored EC2 instance families. Each instance type is designed to expose the core strengths of either Inferentia or Trainium, depending on whether the workload involves inference or training.
4.1 Inf1 Instances: First-Generation Inference
Launched in 2019, Inf1 instances were the first to feature Inferentia1 chips. These instances provided a lower-cost alternative to GPU-based inference, targeting high-volume, latency-sensitive workloads such as natural language understanding, object detection, and recommendation systems.
| Instance Type | vCPUs | Memory | NeuronCores | Max Network Bandwidth |
| inf1.xlarge | 4 | 8 GiB | 1 | Up to 10 Gbps |
| inf1.6xlarge | 24 | 96 GiB | 4 | Up to 25 Gbps |
| inf1.24xlarge | 96 | 192 GiB | 16 | 100 Gbps |
Inf1 instances are tightly integrated with the Neuron SDK and continue to be suitable for mature models with steady inference requirements.
4.2 Inf2 Instances: High-Performance Inference
Inf2 instances, introduced in 2022, are powered by Inferentia2 and reflect a significant architectural upgrade. They offer higher model capacity, enhanced support for BF16, and improved interconnect bandwidth.
Key features:
- NeuronCore-v2 architecture
- Support for multi-modal and generative models
- Enhanced parallelism for larger batch inference
These instances are suitable for deploying LLMs, generative AI pipelines, and low-latency recommendation systems at scale.
4.3 Trn1 and Trn1n Instances: Trainium-Based Training
Training workloads benefit from high interconnect bandwidth and memory throughput—both of which are addressed by Trn1 and Trn1n instances, built on Trainium.
- Trn1 instances support up to 16 Trainium chips, suitable for single-node training of large models.
- Trn1n instances extend this capability to multi-node setups with 800 Gbps EFA networking for distributed training.
These instances are optimized for model and data parallelism across PyTorch, TensorFlow, and Hugging Face training workflows.
4.4 Regional and Availability Zone Support
Support for Inf and Trn instances varies by region, typically launching first in North America and gradually expanding.
| Region | Inf1 | Inf2 | Trn1 | Trn1n |
| US East (N. Virginia) | ✅ | ✅ | ✅ | ✅ |
| US West (Oregon) | ✅ | ✅ | ✅ | ✅ |
| Europe (Frankfurt) | ✅ | ✅ | ❌ | ❌ |
| Asia Pacific (Singapore) | ✅ | ❌ | ❌ | ❌ |
This deployment pattern reflects AWS’s strategy of aligning high-demand AI services with data locality and availability.
5. Cost Economics and Efficiency
One of the primary drivers behind the development of AWS’s custom silicon—Inferentia for inference and Trainium for training—has been to make large-scale AI deployments economically viable and energy-efficient. By designing purpose-built accelerators tailored to common deep learning workloads, AWS enables developers to achieve superior performance at a fraction of the cost typically associated with GPU-based infrastructure.
5.1 Instance Pricing Overview
Inferentia and Trainium instances are priced competitively, especially when performance and throughput are factored in. In many cases, organizations can replace GPU instances with fewer AWS custom silicon instances due to higher efficiency per chip.
The table below provides a comparative view of hourly on-demand pricing (as of early 2025) for typical instance types across the US East (N. Virginia) region:
| Instance Type | Chipset | Purpose | On-Demand Rate (USD/hr) | Comparable GPU Instance | GPU Rate (USD/hr) |
| inf1.xlarge | Inferentia1 | Inference (entry-level) | ~$0.228 | g4dn.xlarge (T4) | ~$0.526 |
| inf2.xlarge | Inferentia2 | High-performance inference | ~$0.45 | A10G or L4 equivalents | ~$0.78 |
| trn1.2xlarge | Trainium | Training | ~$1.30 | p4d.24xlarge (A100) | ~$3.06 |
Note: Prices may vary across regions and availability zones. Savings increase further with reserved or spot pricing models.
These numbers highlight how AWS custom silicon can provide 30–60% savings at the instance level compared to equivalent GPU configurations, without sacrificing model accuracy or inference latency.
5.2 Total Cost of Ownership vs. GPU-Based Alternatives
While hourly rates are a key metric, organizations often focus on Total Cost of Ownership (TCO) when evaluating long-term infrastructure investments. TCO considers not just hardware costs but also operational efficiency, scalability, and energy use.
AWS reports that customers adopting Inferentia and Trainium achieve up to 50% lower TCO due to several factors:
- Higher performance-per-watt: Better utilization of silicon resources means fewer instances are required.
- Optimized runtime stack: The Neuron SDK reduces overhead through operator fusion and memory-efficient scheduling.
- Reduced cooling and power requirements: Trainium and Inferentia consume less power per inference or training operation than general-purpose GPUs.
- Less over-provisioning: High throughput per instance allows right-sizing of workloads, minimizing idle compute.
For large-scale deployments—like running 24/7 inference services or training multi-billion parameter models—the compound savings are substantial.
5.3 Reserved Capacity and Savings Plans
To further enhance cost efficiency, AWS provides flexible purchasing models tailored to workload predictability:
- Savings Plans: Provide up to 72% savings over on-demand pricing in exchange for a consistent usage commitment (measured in $/hr) across any instance type.
- Reserved Instances (RIs): Offer discounts of up to 75% when instances are reserved for 1- or 3-year terms in specific Availability Zones.
- Spot Instances: Leverage unused EC2 capacity at steep discounts—ideal for fault-tolerant jobs like distributed model training with checkpointing. Trn1 and Inf2 support spot pricing where available.
✅ Best Practice: Combine Reserved Instances for inference endpoints and Spot Instances for batch training to optimize cost-performance balance.
5.4 Cost Optimization Strategies
To maximize cost efficiency on Inferentia and Trainium, AWS recommends adopting a mix of architectural and operational strategies:
- Model quantization: Lower-precision formats like INT8 (inference) and BF16 (training) reduce compute requirements while preserving accuracy.
- Batching: Aggregate multiple inputs per inference call to increase utilization and reduce per-request cost. Neuron Runtime supports dynamic batching.
- Right-sizing instances: Match model size, memory needs, and expected concurrency to the most appropriate instance type. For example, small models on inf1.xlarge, LLMs on inf2.48xlarge.
- Elastic scaling: Use Amazon SageMaker with auto-scaling or EC2 Auto Scaling Groups to adjust instance counts based on real-time load.
- Neural architecture search (NAS) and pruning: Design smaller, more efficient models to run faster on specialized hardware.
6. Development Ecosystem and Tools
To make custom silicon practical for real-world use, AWS offers a robust ecosystem of tools and SDKs designed to reduce friction in developing, deploying, and optimizing AI models.
6.1 AWS Neuron SDK: Compiler, Runtime, and Libraries
The Neuron SDK supports both Inferentia and Trainium chips. Its core components:
- Neuron Compiler (neuron-cc): Converts models from popular ML frameworks to optimized formats
- Neuron Runtime: Handles model execution
- Monitoring and profiling tools: Enable performance tuning and observability
The SDK is regularly updated and integrates with AWS's cloud-native tooling, including CloudWatch and SageMaker.
6.2 Framework Support: PyTorch, TensorFlow, Hugging Face
AWS supports training and inference across widely-used ML frameworks:
| Framework | Inference (Inferentia) | Training (Trainium) |
| PyTorch | ✅ torch-neuron | ✅ torch-neuronx |
| TensorFlow | ✅ neuron-tensorflow | ✅ neuronx |
| Hugging Face | ✅ via Optimum | ✅ via Optimum Neuron |
This flexibility ensures that developers can maintain their current toolchains while leveraging AWS silicon under the hood.
6.3 Debugging, Profiling, and Model Conversion
AWS offers built-in support for:
- NeuronPerf and NeuronProfiler for throughput and latency analysis
- Debugging hooks compatible with TensorBoard
- Model conversion tools to move from ONNX or PyTorch checkpoints to Neuron-compiled formats
These tools are intended to close the usability gap between general-purpose hardware and AWS’s domain-specific chips.
6.4 CI/CD and DevOps Best Practices
For organizations deploying ML in production, Neuron supports full DevOps lifecycle integration:
- Model packaging via Docker
- Deployment with ECS, EKS, or SageMaker endpoints
- Integration with CodePipeline, GitHub Actions, and Terraform
- Inference monitoring via CloudWatch Metrics and Alarms
These features allow developers to treat ML infrastructure as code, enabling continuous delivery of AI services.
6.5 Community, Open Source Projects, and Ecosystem Support
The Neuron ecosystem includes:
- Community-maintained examples on GitHub
- Collaboration with Hugging Face on the Optimum library
- Growing documentation and tutorial base
- Dedicated support via AWS forums and GitHub issues
These resources help bridge the gap for teams transitioning from GPU-centric pipelines to AWS-native AI deployments.
7. Deployment Models and Integration
The flexibility of AWS’s Inferentia and Trainium chips extends beyond hardware performance—they are engineered for integration into a wide range of deployment environments. Whether for real-time inference, large-scale training, or hybrid architectures, these chips can be deployed across standard AWS services and custom pipelines.
7.1 Direct EC2 Deployment Patterns
Direct EC2 deployment remains the most customizable approach. It allows full control over instance provisioning, model compilation, and runtime configuration. This is common in scenarios where low-level tuning is necessary or when integrating into existing orchestration systems.
Typical setup includes:
- Launching Inf1/Inf2 or Trn1 instances
- Installing the Neuron SDK and dependencies
- Compiling models locally or in CI pipelines
- Running inference or training jobs manually or through scripts
This method provides flexibility at the cost of increased operational complexity.
7.2 Container Deployments (ECS, EKS, Kubernetes)
For teams using containers, both Inferentia and Trainium are supported in containerized workflows through:
- Amazon ECS with Neuron-optimized AMIs
- Amazon EKS with Neuron device plugin for Kubernetes
- Custom container runtimes with the Neuron runtime and compiler pre-installed
These models allow integration into CI/CD pipelines and standardized dev environments while maintaining infrastructure abstraction and autoscaling capabilities.
7.3 SageMaker Integration for Training and Inference
Amazon SageMaker offers a managed environment for deploying and scaling ML models using Trainium and Inferentia instances.
Benefits include:
- Pre-built container images for PyTorch and TensorFlow
- Automatic model compilation via Neuron SDK
- Endpoint deployment with autoscaling and monitoring
- Multi-model endpoints and batch transform support
This approach minimizes infrastructure overhead and accelerates time-to-deployment for both training and inference workloads.
7.4 Multi-Node and Distributed Deployments
Trainium instances are specifically designed to support distributed training across nodes, using:
- Elastic Fabric Adapter (EFA) for low-latency interconnect
- Libraries like torch.distributed, Horovod, or TensorFlow MultiWorkerMirroredStrategy
- S3 or FSx-backed shared storage for checkpointing and data sharding
Multi-node setups are typically used for LLM pretraining or vision models with large parameter counts and datasets.
7.5 Security and Governance Considerations
Security remains a top concern in enterprise deployments.
AWS provides:
- IAM roles and permissions for Neuron-based workloads
- VPC isolation, private subnets, and service endpoints
- Data encryption at rest and in transit via AWS KMS
- Logging and monitoring through CloudTrail, GuardDuty, and CloudWatch
Additionally, containerized deployments can leverage runtime security tools like AWS Inspector and EKS Pod Security Policies.
8. Performance Tuning and Optimization
Achieving peak efficiency with AWS Inferentia and Trainium isn’t just about selecting the right instance—it’s about aligning the software stack with the hardware’s architectural strengths. Through optimized compilation, intelligent batching, and precision control, developers can significantly increase throughput and reduce costs.
8.1 Compilation Strategies and Neuron Optimizations
Model compilation transforms a framework-native representation (e.g., PyTorch or TensorFlow graph) into optimized operations executable on NeuronCores. The Neuron Compiler (neuron-cc and neuronx-cc) plays a critical role here.
Compilation optimizations include:
- Operator fusion: Combines adjacent operations (e.g., matmul + bias + activation) into a single kernel to reduce memory access overhead.
- Graph pruning: Eliminates unused branches or redundant computations.
- Static memory planning: Allocates tensors and weights efficiently across NeuronCores to minimize copying.
To improve compilation results:
- Preprocess the model (layer normalization, weight folding)
- Freeze parameters (for inference)
- Use model tracing or scripting where supported (especially in PyTorch)
Multiple compilation profiles can be generated for different batch sizes and cached for reuse.
8.2 Quantization and Mixed Precision Techniques
Quantization reduces the numeric precision of models, typically converting from FP32 to INT8 (for inference) or BF16 (for training), reducing memory use and improving compute density.
Supported data types across hardware:
| Data Type | Inferentia | Trainium | Use Case |
| FP32 | Partial | Yes | High-accuracy training |
| BF16 | Yes | Yes | Default for training |
| FP16 | Yes | Partial | Mixed precision inference |
| INT8 | Yes | No | High-speed inference |
Strategies:
- Post-training quantization (PTQ): Simpler, faster, may slightly impact accuracy.
- Quantization-aware training (QAT): Requires retraining but preserves accuracy better.
Frameworks like PyTorch and TensorFlow offer native support through torch.quantization and tfmot.
8.3 Batching and Latency Optimization
Batching is essential for maximizing throughput, especially on inference instances where compute can be underutilized at low batch sizes.
Latency vs. throughput trade-offs:
- Small batch sizes: Lower latency, lower throughput (suitable for real-time NLP APIs)
- Large batch sizes: Higher throughput, increased latency (suitable for batch jobs)
Inferentia’s Neuron Runtime supports:
- Dynamic batching: Incoming requests are grouped at runtime
- Asynchronous execution: Multiple model executions in parallel
- Multi-threaded queuing: Reduces head-of-line blocking
Use NeuronPerf and NeuronMonitor to profile latency per request and adjust batching accordingly.
8.4 Model Partitioning and Memory Efficiency
As model sizes grow—particularly for transformer-based architectures—memory becomes a bottleneck.
To handle this:
- Tensor parallelism: Split tensor operations across NeuronCores or Trainium chips.
- Pipeline parallelism: Partition layers into stages across multiple cores or nodes.
- NeuronLink interconnect (Trainium): Facilitates high-speed communication across NeuronCores within a chip and between chips.
Other techniques:
- Compress embedding tables (used in recommender systems)
- Share weights across attention heads (for smaller transformer variants)
- Use attention sparsity or pruning to reduce compute
8.5 Real-World Examples: NLP, Vision, and Recommenders
| Workload | Optimization Applied | Measurable Impact |
| BERT Inference (Inf2) | INT8 + Operator Fusion | 3x throughput vs. FP32 |
| YOLOv5 Inference (Inf1) | Static Batching | 2.5x speed-up for 1080p input |
| GPT-J Training (Trn1) | Pipeline + Tensor Parallel | Trained 6B model across 32 chips |
| Collaborative Filtering (Inf1) | INT8 + Model Pruning | 60% lower latency, 40% smaller model |
These use cases demonstrate the importance of end-to-end optimization across both the model architecture and deployment infrastructure.
9. Workload-Specific Design Considerations
Not all AI workloads scale the same way. Model architecture, latency requirements, and training paradigms must be mapped effectively to the characteristics of Inferentia and Trainium chips. Below are considerations and best practices by domain.
9.1 Large Language Models (LLMs)
LLMs demand:
- High memory capacity for embeddings and attention heads
- Cross-node synchronization for parameter updates
- Mixed precision for training efficiency (e.g., BF16 with loss scaling)
Trainium + EFA enables LLM pretraining with horizontal scaling:
- GPT-2, GPT-J, T5 (1B–6B parameters) fit on Trn1n clusters
- Frameworks: Hugging Face Transformers + DeepSpeed or Megatron-LM
Inference on Inf2 works well with:
- Encoder-decoder models for summarization
- Autoregressive decoding with attention caching
9.2 Computer Vision Applications
Typical vision models include:
- CNNs (ResNet, EfficientNet)
- Object detection (YOLOv5/6, Faster R-CNN)
- Vision transformers (ViT, Swin)
Optimization tips:
- Preprocess to fixed input resolution (static shape)
- Quantize convolutions and batch norms
- Deploy with multi-threaded NeuronRuntimes for camera streams
Training vision transformers is compute-heavy and well-suited to Trainium’s throughput and memory capacity.
9.3 Recommendation Systems and Ranking Models
Recommenders rely on:
- Large embedding lookups
- Sparse input handling
- Custom ranking metrics
Inferentia supports:
- INT8 quantized MLPs and dense layers
- Compressed or hashed embeddings
- Accelerated inference at scale
Trainium is suitable for collaborative filtering or DLRM-style training using BF16 precision.
9.4 Time Series and Forecasting Workloads
Forecasting models—LSTMs, GRUs, and Transformers—often require long-sequence memory handling. Inferentia and Trainium address this through:
- Efficient sequence batching
- Input windowing for sliding forecasts
- Stateful inference (e.g., tracking hidden state externally)
These models are frequently used in:
- Energy usage forecasting
- Predictive maintenance
- Financial time series modeling
Trainium’s compute and memory combination supports encoder-decoder style forecasting architectures.
9.5 Inference Deployment Models: Cloud, Edge, and Hybrid
While Inferentia and Trainium are currently cloud-based, workload deployment models may vary:
- Cloud: Suitable for LLM APIs, recommendation systems, batch inference
- Edge (experimental): AWS is researching Neuron-compatible edge devices for real-time use
- Hybrid: Preprocess data at the edge, run inference in the cloud; useful for latency-critical, bandwidth-sensitive applications (e.g., autonomous inspection, industrial IoT)
SageMaker Edge Manager, while not currently supporting Inferentia directly, may evolve to integrate edge-compatible Neuron models in the future.
10. Case Studies and Production Adoption
The real test of any AI infrastructure lies in how well it performs under production-scale workloads. Across industries, organizations are leveraging Inferentia and Trainium to meet diverse demands—ranging from high-throughput inference to cost-effective model training—without compromising accuracy or latency.
10.1 Enterprise Adoption Scenarios
A number of large-scale AWS customers have adopted Inferentia and Trainium across verticals:
- Snap Inc. uses Inferentia for computer vision models that power AR filters. Migrating from GPU-based inference to Inf1 resulted in up to 70% cost reduction for their inference workloads.
- Anthem (Elevance Health) has integrated Trainium into their biomedical research pipeline, particularly for model training involving large genomic datasets.
- Amazon Alexa moved NLP workloads to Inferentia, achieving 2x latency improvements in real-time voice assistants.
- Money Forward, a fintech firm, adopted Inf2 for financial document classification and saw both latency and operational cost improvements.
These use cases reflect growing confidence in the stability, performance, and tooling around AWS’s custom silicon.
10.2 Performance Benchmarks in Production
While benchmark tests offer insight into raw performance, production workloads test the chips under realistic scenarios including network variability, concurrent users, and real-time latency constraints.
| Application | Platform | Observed Improvement |
| Transformer Inference (BERT-base) | Inf2 | 3.1x throughput vs. g4dn |
| Recommendation Engine | Inf1 | 2.4x throughput + 60% cost savings |
| Vision Transformer Training (ViT) | Trn1 | 25% lower epoch time than V100 |
| GPT-J Fine-Tuning | Trn1n | 45% faster convergence vs. A100 |
Results vary by batch size, model architecture, and input distribution but consistently favor AWS silicon for predictable workloads.
10.3 Cost Savings and Efficiency Gains
In most case studies, cost savings came from three key areas:
- Higher throughput per dollar: Due to the NeuronCore’s efficient scheduling and execution.
- Smaller instance counts: High-performance per instance means fewer machines are needed.
- Power consumption reductions: Organizations operating in multi-region, always-on environments observed meaningful reductions in electricity usage.
Some customers also reported over 50% lower TCO when combining Reserved Instances and workload-aware optimizations.
10.4 Migration Journey Narratives
Most successful migrations follow a common pattern:
- Assessment: Benchmark the GPU-based baseline
- Model adaptation: Quantization, re-compilation, batching strategy
- Validation: Run inference comparison tests to ensure parity
- Phased rollout: Start with a low-risk use case, scale as confidence grows
AWS provides tools like the Neuron SDK migration guide, optimum-neuron, and Neuron-compatible model repositories to help streamline this process.
11. Competitive Landscape Analysis
AWS is not alone in developing domain-specific accelerators. This section compares Inferentia and Trainium against leading alternatives from NVIDIA, Google, and other cloud providers, offering a perspective on technical advantages, performance metrics, and cost efficiency.
11.1 NVIDIA GPUs: Flexibility vs. Specialization
| Feature | Inferentia/Trainium | NVIDIA GPUs |
| Specialization | AI-specific (inference/training) | General-purpose |
| Compilation | Required (Neuron SDK) | Plug-and-play |
| INT8 Optimization | Superior in Inferentia | Strong (TensorRT) |
| Cost Efficiency | Higher (for fixed workloads) | Moderate |
| Ecosystem Maturity | Growing | Extensive |
Takeaway: NVIDIA excels in flexibility and ecosystem breadth. AWS silicon excels in cost-per-inference and tight integration for repeatable, production-grade AI.
11.2 Google TPUs: Proprietary vs. Cloud-Native Integration
| Feature | Trainium | TPU v4 |
| Precision Modes | BF16/FP32 | BF16/FP32 |
| Training Speed | Comparable | Slightly higher (specific to large models) |
| Interconnect | EFA (800 Gbps) | TPU Interconnect (preferred only in Google Cloud) |
| Ecosystem | Fully integrated in AWS | Limited outside GCP |
Takeaway: TPUs are extremely fast for Google-native models (like PaLM or T5), but Trainium offers better integration with PyTorch, Hugging Face, and AWS services.
11.3 Other Cloud Offerings
| Provider | Chip | Observations |
| Microsoft Azure | Project Maia (in preview) | Early-stage; not yet production-grade |
| Alibaba Cloud | Hanguang 800 | Primarily used internally; limited external adoption |
| Intel Gaudi | Used in AWS DL1 instances | Lower maturity and less ecosystem support |
AWS currently leads in custom AI chip maturity for external developers with Neuron SDK, extensive documentation, and support across instance families.
11.4 Performance-per-Dollar and Strategic Positioning
In most scenarios, AWS silicon wins on performance-per-dollar, especially when:
- Workloads are inference-heavy and stable
- Training involves large batch jobs or transformers
- Reserved or spot capacity is used
NVIDIA and Google alternatives may still be superior for:
- Ad-hoc experimentation
- Rapid prototyping with pre-built models
- Specialized tooling or proprietary hardware libraries
12. Future Outlook and Roadmap
The AI landscape is evolving rapidly. AWS continues to invest in making Inferentia and Trainium not just relevant but essential to the future of scalable AI infrastructure.
12.1 Announced and Projected Roadmap Features
AWS has confirmed multiple upcoming enhancements to the Neuron platform:
- Neuron SDK 3.x with faster compile times and model introspection
- Model-as-a-Service (MaaS) platform for LLMs running on Trainium
- Expanded support for transformer-based fine-tuning and quantized training
- Potential future: Trainium2 chips with larger memory and integrated on-die networking
Some of these features are already in preview as of early 2025.
12.2 Integration with Emerging AI Techniques
New workloads like diffusion models, multi-modal training, and graph neural networks (GNNs) are being tested on AWS silicon. Enhancements include:
- Wider native ops support in the Neuron compiler
- Optimizations for sparse attention and multi-head self-attention
- Better support for LoRA, QLoRA, and parameter-efficient fine-tuning
These improvements aim to support more dynamic and less statically-shaped models, which previously required GPUs due to their flexibility.
12.3 Scaling to Larger Models and Infrastructure
With the rise of trillion-parameter models and autonomous agents, Trainium’s roadmap focuses on:
- Dense node clustering for shared training workloads
- Hardware-aware model partitioning that reduces cross-chip communication
- Greater memory per core, enabling deeper models without splitting
AWS is also experimenting with infrastructure automation tools for deploying large-scale model training clusters with minimal manual configuration.
12.4 Trends in Specialized AI Silicon
Industry-wide, there is a move toward:
- Vertical integration (chip + compiler + cloud platform)
- AI-specific orchestration (e.g., SageMaker Pipelines with Neuron support)
- Green AI: chips that deliver more ops-per-watt for sustainability
AWS is expected to remain a major player in this space by continuing to align Neuron roadmap development with the evolution of generative AI and foundation models.




