
In today's data-driven world, businesses generate and collect more information than ever. This data often lives in various systems, databases, and formats across the organization. Without proper integration, these isolated data silos can prevent companies from gaining valuable insights and making informed decisions.
Effective data integration brings together information from multiple sources into a unified view, enabling businesses to:
- Make better-informed decisions based on complete information
- Identify trends and patterns that might otherwise remain hidden
- Improve operational efficiency through automation
- Enhance customer experiences by having a 360-degree view of interactions
Cloud-Based ETL: The Role of AWS Glue & Azure Data Factory
Extract, Transform, Load (ETL) processes form the backbone of modern data integration. As organizations move their data infrastructure to the cloud, cloud-based ETL services have become increasingly important.
AWS Glue and Azure Data Factory represent two leading cloud-based data integration solutions from the biggest cloud providers: Amazon Web Services and Microsoft Azure. These platforms help businesses move, transform, and prepare their data for analysis without the need to manage complex infrastructure.
Whether you're just starting your data integration journey or looking to optimize your existing processes, understanding the differences between AWS Glue and Azure Data Factory will help you make better-informed decisions.
What is AWS Glue?
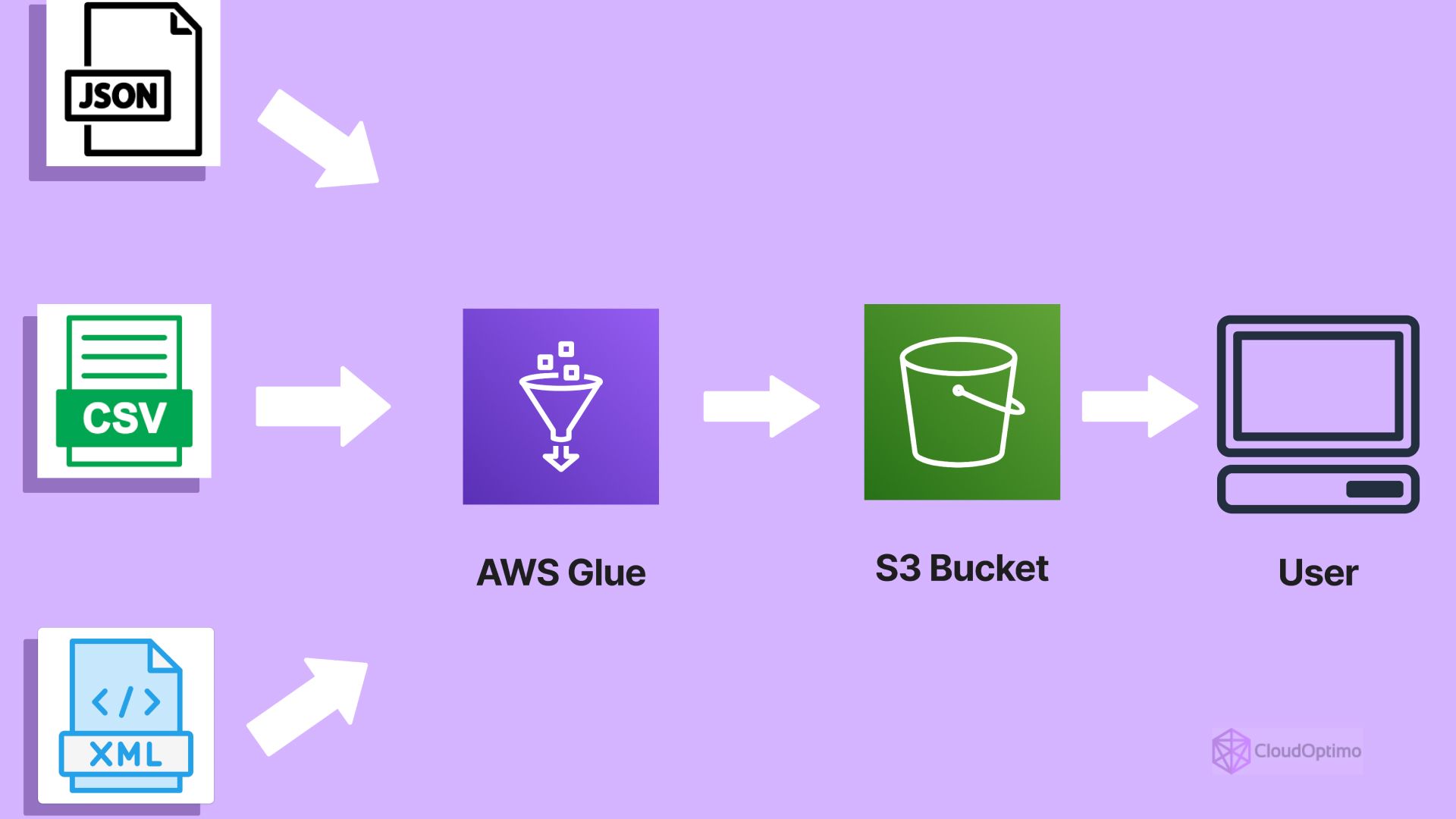
AWS Glue is Amazon's fully managed extract, transform, and load (ETL) service designed to make it easy for customers to prepare and load their data for analytics. It automatically discovers and profiles your data, recommends and generates ETL code, and provides a flexible scheduler for handling dependencies between data processing jobs.
At its core, AWS Glue is a serverless data integration service that simplifies the process of discovering, preparing, and combining data for analytics, machine learning, and application development.
Key Features & Capabilities
- Data Catalog: A central metadata repository that automatically discovers and catalogs data assets
- Schema Discovery: Automatically infers schemas from structured and semi-structured data
- Job Scheduler: Dependency-based scheduling for ETL workflows
- Developer Endpoints: Interactive development environments for ETL script creation
- AWS Glue Studio: Visual interface for creating, running, and monitoring ETL jobs
- Bookmarks: Track processed data to enable incremental data processing
- Streaming ETL: Process streaming data in real-time
- Flexible Job System: Supports Python and Scala for ETL script development
- Built-in Transforms: Pre-built transforms for common data preparation tasks
When Should You Use AWS Glue?
AWS Glue is particularly well-suited for:
- AWS-centric organizations: If you're already heavily invested in the AWS ecosystem
- Data discovery needs: When you need to discover and catalog data from various sources
- Serverless requirements: When you want to minimize infrastructure management
- Python/Scala developers: If your team is comfortable with these programming languages
- Analytics preparation: When preparing data for analysis in services like Amazon Redshift, Amazon Athena, or Amazon EMR
What is Azure Data Factory?
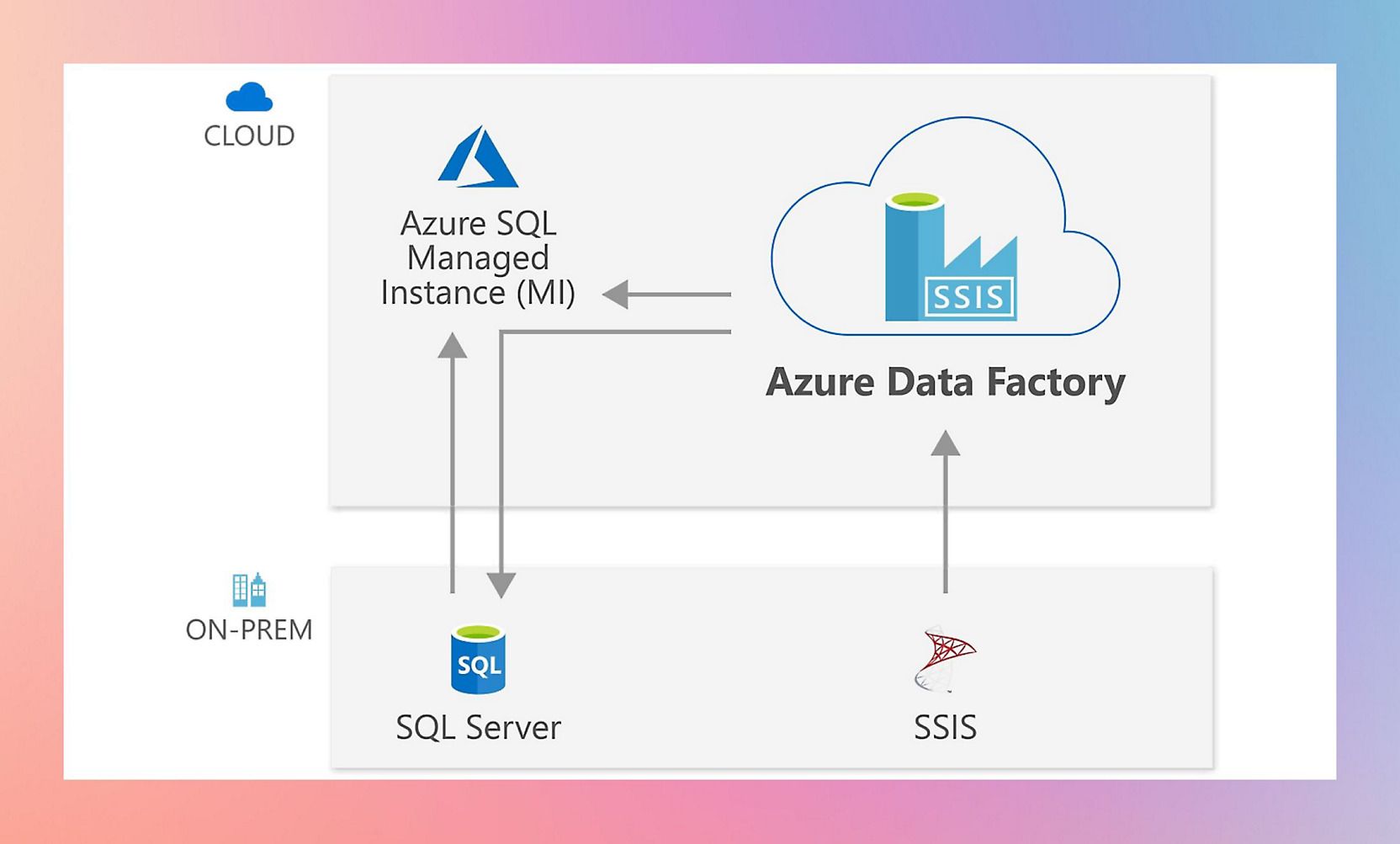
Source - Azure
Azure Data Factory is Microsoft's cloud-based data integration service that allows you to create data-driven workflows for orchestrating and automating data movement and transformation. It provides a way to create, schedule, and manage data pipelines across on-premises and cloud environments.
Azure Data Factory focuses on providing a visual, low-code experience for data integration, while also offering advanced capabilities for complex data transformation requirements.
Key Features & Capabilities
- Visual Data Flow: Low-code/no-code interface for data transformation
- Control Flow: Orchestration of data pipeline activities with complex logic
- Data Flow Debugging: Live debugging of data transformation logic
- Integration Runtime: Flexible runtime for executing integration activities
- Over 90 Built-in Connectors: Connect to various data sources without coding
- SSIS Integration: Run SQL Server Integration Services (SSIS) packages
- Integration with Azure Services: Seamless integration with other Azure services
- Mapping Data Flows: Visual data transformation without writing code
- Git Integration: Source control for data pipeline development
- Monitoring Dashboard: Comprehensive monitoring and alerting
When Should You Use Azure Data Factory?
Azure Data Factory is particularly well-suited for:
- Microsoft ecosystem users: If you're already using Microsoft products and services
- Low-code preference: When you want visual development rather than coding
- Hybrid data integration: When connecting on-premises systems with cloud services
- Complex orchestration needs: For sophisticated data pipeline workflows
- SQL Server migration: When migrating from on-premises SQL Server Integration Services (SSIS)
AWS Glue vs. Azure Data Factory: A Head-to-Head Comparison
Now that we have explored the individual capabilities of AWS Glue and Azure Data Factory, it's time to compare them directly. Both services are designed for cloud-based data integration, but they cater to different use cases, architectures, and operational models.
Understanding these differences is essential for selecting the right tool based on your organization's data processing needs, infrastructure preferences, and cost considerations.
| Feature | AWS Glue | Azure Data Factory |
| Architecture | Fully serverless with automatic scaling | Hybrid model with configurable compute |
| Primary Use Case | ETL processing and data preparation | Data pipeline orchestration and movement |
| Ease of Use | Code-first approach (Python, Scala) | Low-code, visual pipeline designer |
| Processing Engine | Apache Spark-based ETL | Mapping Data Flows, SSIS, and Azure Databricks |
| Security Model | AWS IAM, VPC, encryption | Azure AD, Private Link, Key Vault |
| Data Connectors | Primarily AWS ecosystem | 90+ built-in connectors for various sources |
Breaking Down the Key Comparisons
- Architecture & Scalability: AWS Glue is entirely serverless, meaning it automatically provisions and scales resources based on workload. Azure Data Factory, on the other hand, offers a hybrid model where users have manual control over compute environments via Integration Runtimes.
- Data Processing Approach: AWS Glue is optimized for ETL workloads and is tightly integrated with AWS analytics services. Advanced transformations require Python or Scala coding. Azure Data Factory focuses on data movement and orchestration, offering low-code data transformation through Mapping Data Flows.
- Ease of Use: AWS Glue is more suited for developers and engineers comfortable with code-based ETL. Azure Data Factory is built for both technical and non-technical users, offering a visual interface to build and manage pipelines with minimal coding.
- Integration & Connectivity: AWS Glue is designed for AWS-native workloads, with some support for external data sources. Azure Data Factory provides a broader range of built-in connectors, making it ideal for hybrid and multi-cloud integrations.
- Cost Considerations: AWS Glue's pay-per-use model is straightforward, charging based on Data Processing Units (DPUs) per job execution. Azure Data Factory separates pricing into pipeline orchestration, data movement, and transformation costs, which can be more flexible for simple workflows but expensive for complex ETL processes.
This comparison provides a clear framework for evaluating AWS Glue and Azure Data Factory. Next, we will dive deeper into specific aspects to determine which service is the better fit for different data integration needs.
Architecture & Core Components
AWS Glue's Strengths in Serverless Architecture
Powered by a fully managed ETL service, AWS Glue excels in serverless operations with minimal infrastructure management. Its architecture is optimized for automatic scaling and data discovery, making it well-suited for organizations looking to minimize operational overhead.
Key Features:
- Data Catalog: Central metadata repository that automatically discovers and catalogs data
- Serverless ETL Engine: Apache Spark-based processing that scales automatically
- Job Scheduler: Manages dependencies between jobs with no server provisioning
- Developer Endpoints: Interactive development environments for ETL script creation
Azure Data Factory's Optimized Performance for Complex Orchestration
Azure Data Factory is built to handle sophisticated data movement and transformation with robust orchestration capabilities. Its architecture is designed for visual pipeline development and complex workflow management, offering more granular control over execution environments.
Key Features:
- Visual Pipeline Designer: Low-code interface for creating complex data workflows
- Control Flow: Advanced orchestration with conditional execution and loops
- Integration Runtime: Flexible runtime environment with three types (Azure, Self-hosted, SSIS)
- Monitoring Dashboard: Comprehensive monitoring and alerting capabilities
| Feature | AWS Glue | Azure Data Factory |
| Service Model | Fully serverless | Hybrid model (cloud & self-hosted integration runtime) |
| Execution Environment | Auto-scaled Apache Spark-based ETL | Uses external compute (Azure IR, SSIS, Databricks, HDInsight) |
| Workflow Orchestration | Basic job scheduling with triggers | Advanced orchestration with dependencies, branching, loops |
| Development Approach | Code-first with Python/Scala ETL scripts | Low-code, visual designer with drag-and-drop pipelines |
| Metadata Management | Built-in Data Catalog for automated schema discovery | No native catalog; relies on external metadata sources |
| Monitoring & Logging | CloudWatch-based job logs | Built-in monitoring dashboard with detailed execution tracking |
Data Ingestion & Processing Capabilities
AWS Glue's Strengths in Code-First Processing
AWS Glue provides powerful data processing capabilities through Apache Spark, focusing on code-based transformations and automatic schema discovery. Its approach is optimized for developers comfortable with Python or Scala, offering flexibility for complex data manipulation.
Key Features:
- Schema Discovery: Automatically infers schemas from various data sources
- Python/Scala Scripts: Code-based ETL with Apache Spark
- Machine Learning Transforms: Built-in ML capabilities for data cleansing
- Streaming ETL: Support for real-time data processing
- Crawlers: Automatic data discovery and cataloging
Azure Data Factory's Optimized Performance for Visual Data Transformation
Azure Data Factory excels in visual data transformation and movement, designed for broad accessibility across technical skill levels. Its extensive connector library and visual interface make it ideal for organizations that prefer low-code approaches to data integration.
Key Features:
- Mapping Data Flows: Visual data transformation without writing code
- 90+ Data Connectors: Extensive library of pre-built connectors
- SSIS Integration: Support for legacy SQL Server Integration Services
- Data Flow Debugging: Live debugging of transformation logic
- Wrangling Data Flows: Interactive data preparation capabilities
| Feature | AWS Glue | Azure Data Factory |
| Data Processing Engine | Apache Spark-based ETL | Uses external compute (Azure Databricks, HDInsight, SSIS) |
| Data Transformation Style | Code-first ETL using Python/Scala | Low-code transformations via Mapping Data Flows |
| Schema Handling | Automatic schema inference with Crawlers | Requires manual schema definition |
| Streaming & Real-time ETL | Native streaming ETL support | Event-driven and batch-triggered pipelines |
| Connector Library | AWS-centric with fewer third-party connectors | Extensive (90+ built-in connectors for various platforms) |
| Performance Optimization | Auto-tuned Spark execution with Glue Optimizer | Pushdown computation for optimized data movement |
| Data Preparation & ML | Built-in ML transforms for data cleansing | Wrangling Data Flows for interactive data prep |
Ease of Use: Low-Code vs. Code-First Approach
AWS Glue's Developer-Oriented Experience
AWS Glue provides a more code-centric experience, ideal for data engineers and developers comfortable with programming. While AWS Glue Studio offers some visual capabilities, the service is fundamentally designed for those who prefer writing code for data transformations.
Key Features:
- AWS Glue Studio: Visual interface for basic job creation
- Script Generation: Automatic generation of ETL scripts
- Python/Scala Support: Flexibility for custom transformations
- Developer Endpoints: Interactive development environments
Azure Data Factory's Business-Friendly Visual Interface
Azure Data Factory delivers an accessible, low-code experience that bridges the gap between business users and technical teams. Its visual interface empowers users without extensive programming knowledge to create sophisticated data pipelines.
Key Features:
- Visual Pipeline Designer: Drag-and-drop interface for pipeline creation
- Data Flow Canvas: Visual data transformation design
- Copy Data Tool: Wizard-driven data movement configuration
- Visual Monitoring: Graphical pipeline execution monitoring
| Feature | AWS Glue | Azure Data Factory |
| Target Users | Optimized for developers comfortable with coding | Designed for both technical and non-technical users |
| Learning Curve | Steeper—requires knowledge of Python/Scala | Easier—low-code interface with minimal scripting |
| User Interface | Primarily code-based with basic visual tools | Visual, drag-and-drop interface |
| Interactivity | Developer Endpoints for interactive coding | Interactive Data Flow Canvas for designing transformations |
| Customization | High flexibility with custom scripting | Predefined components with minimal customization |
| Development Flow | Code-first, script generation, and customization | Visual design-first with minimal coding |
| Pipeline Creation | Write custom ETL scripts with auto-generated suggestions | Create workflows using a low-code design canvas |
| Debugging & Monitoring | Primarily log-based, manual debugging | Visual error tracking and debugging via UI |
Scalability & Performance
AWS Glue's Automatic Scaling for Varying Workloads
AWS Glue offers seamless scalability through its serverless architecture, automatically adjusting resources based on workload demands. This approach minimizes management overhead while ensuring optimal performance for both small and large-scale data processing tasks.
Key Features:
- Automatic Resource Allocation: Scales based on job requirements
- Data Processing Units (DPUs): Flexible compute capacity
- Job Concurrency: Configurable parallel job execution
- Worker Type Selection: Options for memory-intensive workloads
Azure Data Factory's Configurable Performance Options
Azure Data Factory provides granular control over performance through configurable Integration Runtimes and compute resources. This approach allows organizations to optimize costs and performance based on specific workload requirements.
Key Features:
- Integration Runtime Types: Azure, Self-hosted, and SSIS options
- Azure IR Units: Configurable compute capacity
- Pipeline Concurrency: Adjustable parallel activity execution
- Data Flow Cluster Settings: Custom compute configuration for transformations
| Feature | AWS Glue | Azure Data Factory |
| Scaling Approach | Serverless, automatic scaling based on workload | Configurable scaling with manual resource adjustments |
| Compute Resource Management | Automatic Data Processing Units (DPUs) allocation | User-defined compute with Azure Integration Runtime (IR) options |
| Job Concurrency | Automatically scales to execute multiple jobs concurrently | Configurable parallelism with manual activity execution controls |
| Customization for Performance | Limited customization, automatic performance tuning with DPUs | Highly customizable with specific performance settings for different workloads |
| Cost Control | Automatic scaling minimizes costs based on actual demand | Cost management through manual adjustments of compute capacity and runtime configuration |
| Real-Time Scaling | Scales instantly based on job requirements | Scalable with user-defined settings for optimal resource allocation in real-time |
Supported Data Sources & Integrations
AWS Glue provides native connections to AWS services like S3, DynamoDB, and Redshift, as well as JDBC connections to databases like MySQL, PostgreSQL, and Oracle. It also supports connections to various file formats and Amazon services.
Azure Data Factory boasts over 90 built-in connectors, covering a wide range of data sources including Azure services, other cloud providers, SaaS applications, file systems, and databases. This gives it an edge in terms of connectivity options.
Key Difference: Azure Data Factory offers a wider range of pre-built connectors, while AWS Glue has stronger integration with the AWS ecosystem.
Security & Compliance
AWS Glue's Integrated Security Framework
AWS Glue leverages Amazon's comprehensive security infrastructure, offering robust protection for sensitive data processing workflows. Its security model integrates seamlessly with existing AWS security services, making it ideal for organizations already invested in the AWS ecosystem.
Key Features:
- AWS IAM Integration: Fine-grained access control and permission management
- Encryption Options: Data encryption at rest and in transit
- VPC Connectivity: Secure processing within private networks
- CloudTrail Integration: Comprehensive audit logging and monitoring
- Compliance Certifications: SOC, HIPAA, PCI DSS, and more
Azure Data Factory's Enterprise-Grade Security
Azure Data Factory provides enterprise-level security features built on Microsoft's security framework, with a strong emphasis on hybrid environments and integration with Azure Active Directory. Its security capabilities are designed for organizations with complex compliance requirements.
Key Features:
- Azure Active Directory: Centralized identity management
- Role-Based Access Control: Granular permission assignments
- Private Link Support: Private network connectivity
- Key Vault Integration: Secure credential management
- Microsoft Defender: Advanced threat protection
Feature | AWS Glue | Azure Data Factory |
Security Integration | Deep integration with AWS security services | Built on Microsoft’s security framework, with hybrid environment support |
Identity Management | AWS IAM for fine-grained access control | Azure Active Directory for centralized identity management |
Encryption | Data encryption at rest and in transit | Encryption at rest and in transit with integration to Azure Key Vault |
Network Security | VPC connectivity for secure processing within private networks | Private Link support for secure data transfer within private networks |
Audit & Monitoring | CloudTrail for comprehensive logging and monitoring | Microsoft Defender for advanced threat protection and monitoring |
Compliance Standards | SOC, HIPAA, PCI DSS, and more | ISO, HIPAA, SOC, and other industry certifications |
Credential Management | Uses AWS IAM roles for secure access control | Key Vault integration for secure credential management |
Pricing Model
AWS Glue's Consumption-Based Pricing
AWS Glue follows a straightforward consumption-based pricing model focused on actual resource usage, making it cost-effective for organizations with predictable ETL workloads. This approach offers transparency and eliminates costs when services aren't actively running.
Key Components:
- ETL Jobs: $0.44 per DPU-hour ($0.22 per DPU-hour for Python shell jobs)
- Development Endpoints: $0.44 per DPU-hour
- Data Catalog: First million objects are stored free, then $1 per 100,000 objects
- Crawlers: $0.44 per DPU-hour
AWS Glue charges only for the resources used during job execution, with no charges when jobs aren't running.
Azure Data Factory's Activity-Based Pricing
Azure Data Factory employs a more granular pricing structure that separates orchestration from execution costs, offering flexibility for various integration scenarios. This model can be advantageous for organizations with diverse data integration needs.
Key Components:
- Pipeline Activities: $0.001 per activity run beyond 2,000/month
- Data Movement: Starting at $0.10 per Azure IR vCore-hour
- Data Flow Execution: Starting at $0.274 per Azure IR vCore-hour
- External Processing: Additional costs for Azure Databricks, etc.
Azure Data Factory charges for pipeline orchestration and execution, with additional costs for data processing using services like Azure Databricks.
Key Difference: AWS Glue's pricing is simpler and more predictable for ETL tasks, while Azure Data Factory's pricing model separates orchestration from execution, potentially resulting in lower costs for simple pipelines but higher costs for complex transformations.
Key Cost Considerations:
AWS Glue:
- More cost-effective for heavy data processing workloads
- Simpler billing structure with fewer variables
- Higher costs for long-running, resource-intensive jobs
- No separate charges for orchestration vs. execution
Azure Data Factory:
- More economical for simple data movement tasks
- Lower entry cost with free activity runs
- More complex pricing model requiring careful planning
- Separation of orchestration and processing costs offers flexibility
| Feature | AWS Glue | Azure Data Factory |
| Pricing Model | Consumption-based (charges only for active resources used) | Activity-based (charges for orchestration and execution separately) |
| ETL Jobs |
| $0.274 per Azure IR vCore-hour for Data Flow Execution |
| Development Endpoints | $0.44 per DPU-hour | Additional costs for external processing like Azure Databricks ($0.60 per vCore-hour for Azure Databricks) |
| Data Catalog |
| No direct equivalent in ADF, but usage counts towards pipeline and execution costs |
| Crawlers | $0.44 per DPU-hour (for automatic data discovery) | No equivalent service in Azure Data Factory |
| Pipeline Activities | No direct cost for orchestration | $0.001 per activity run beyond 2,000/month |
| Data Movement | $0.44 per DPU-hour (Data Processing Unit for data movement) | $0.10 per Azure IR vCore-hour for data movement |
| Data Flow Execution | Included in ETL job costs (based on DPUs) | Starts at $0.274 per Azure IR vCore-hour for data flow execution |
| Free Tier | Free tier includes 1 million objects in Data Catalog, up to 1,000 crawlers, and 25 hours of job runtime per month | Free tier includes 5 Data Movement activities and 200 pipeline activities per month |
Key Takeaways:
- AWS Glue offers a simpler pricing model that can be more predictable, especially for consistent ETL workloads. The costs for crawling and job execution are straightforward—it charges primarily for the compute (DPUs) used during processing.
- Azure Data Factory has a more granular pricing structure, which can make it more cost-effective for simple tasks, but could become complex and costly for advanced transformations and orchestration. Costs can vary significantly based on pipeline execution and external integrations.
Choosing the Right Tool: Which One Fits Your Needs?
Best for Cloud-Native Workloads
If you're fully committed to a single cloud provider:
- AWS Glue is the natural choice for AWS-native environments, offering seamless integration with services like S3, Redshift, and Athena.
- Azure Data Factory works best in Azure-native ecosystems, integrating smoothly with Azure Synapse Analytics, Azure Blob Storage, and Azure SQL Database.
Best for Hybrid & On-Premise Integrations
If you need to connect on-premises systems with cloud services:
- Azure Data Factory has a clear advantage with its Self-hosted Integration Runtime, which provides secure data movement between on-premises and cloud environments.
- AWS Glue has more limited hybrid capabilities, though it can connect to on-premises databases via JDBC if they're accessible from the AWS network.
Best for Real-Time vs. Batch Processing
For different processing needs:
- AWS Glue offers both batch and streaming ETL capabilities, making it suitable for real-time data processing scenarios.
- Azure Data Factory is primarily designed for batch processing, though it can trigger near-real-time pipelines with event-based triggers.
Best for Cost-Conscious Businesses
For organizations watching their budget:
- AWS Glue may be more cost-effective for heavy ETL workloads since it bundles compute and orchestration costs.
- Azure Data Factory might be more economical for simple data movement tasks with minimal transformation needs.
The best choice depends on your specific use case, budget constraints, and existing infrastructure investments.
Real-world Use Cases & Industry Adoption
How Companies Use AWS Glue?
E-commerce Analytics: A major online retailer uses AWS Glue to prepare daily sales data from multiple sources for analysis in Amazon Redshift, enabling better inventory management and personalized marketing.
Financial Services: A global bank leverages AWS Glue to process transaction data from legacy systems, transforming it into a standardized format for fraud detection and compliance reporting.
Healthcare Data Integration: A healthcare provider uses AWS Glue to integrate patient records from different systems, creating a unified patient view while ensuring HIPAA compliance.
How Companies Use Azure Data Factory
Manufacturing IoT: A manufacturing company uses Azure Data Factory to process IoT sensor data from factory equipment, orchestrating complex pipelines that feed into predictive maintenance models.
Retail Marketing: A retail chain leverages Azure Data Factory to integrate customer data from in-store purchases and online behavior, creating comprehensive customer profiles for targeted marketing.
Media Content Management: A media company uses Azure Data Factory to process and distribute digital content across multiple platforms, automating the content supply chain from creation to delivery.
Pros & Cons:
Strengths & Weaknesses of AWS Glue
Strengths:
- Serverless architecture with automatic scaling
- Excellent integration with AWS services
- Built-in data cataloging and schema discovery
- Support for both batch and streaming ETL
- Powerful for data preparation and transformation
Weaknesses:
- Steeper learning curve for non-developers
- Limited visual interface capabilities
- Fewer pre-built connectors compared to Azure Data Factory
- Higher costs for long-running jobs
- Less robust orchestration capabilities
Strengths & Weaknesses of Azure Data Factory
Strengths:
- Visual, low-code interface
- Extensive connector library
- Strong hybrid integration capabilities
- Robust orchestration and workflow features
- Seamless integration with Microsoft ecosystem
Weaknesses:
- More complex pricing model
- Limited serverless capabilities
- Separation of orchestration and processing can increase complexity
- Requires more setup for performance optimization
- Less integrated metadata management
Final Thoughts & Recommendations
Making an Informed Decision
When choosing between AWS Glue and Azure Data Factory, consider these factors:
- Existing Cloud Investment: If you're already heavily invested in AWS or Azure, choosing the corresponding service often makes the most sense.
- Technical Expertise: Azure Data Factory is more accessible to users without extensive programming experience, while AWS Glue is better suited for teams with Python or Scala skills.
- Use Case Complexity: For complex data transformations, AWS Glue's code-based approach may offer more flexibility. For complex orchestration with simpler transformations, Azure Data Factory might be preferable.
- Hybrid Requirements: If connecting on-premises systems is a primary concern, Azure Data Factory has stronger capabilities in this area.
- Budget Considerations: Analyze your specific workload patterns to determine which pricing model aligns better with your usage.
Remember that both services are constantly evolving, with new features and capabilities being added regularly. The best choice today might change as your needs evolve or as the services themselves advance.
Many organizations even use both services for different purposes, leveraging AWS Glue for heavy data transformation within the AWS ecosystem and Azure Data Factory for orchestration and integration with Microsoft systems.






